1.Intuition
本部分主要借鉴于这篇博客.
Word2Vec算法主要包括两个子算法:CBOW(Continuos Bag Of Words)和Skip-Gram算法.Word2Vec算法具体过程如下:
首先,给定一个数据集(一组句子,也叫语料库),然后模型遍历每一个句子的每一个单词.对于每一个单词,要么使用当前单词去预测相邻单词(Skip-gram),要么使用相邻单词去预测当前单词(CBOW).相邻单词,相邻的概念是由超参数window size (窗口大小)来确定的.
Skip-gram算法是一种最简单的神经网络模型,仅仅利用一个简单到只有一个隐藏层的神经网络去执行一个任务,但是我们并不会实际用到模型最终的运行结果.我们真正需要的是隐藏层训练后的各个权重值--这些权重值就是我们要学习的word vectors.
我们将会训练简单的神经网络去完成这样一个任务:给定句子中的某一个单词(输入词),检测周围单词,并且随机选择其中的一个.我们构建的网络将会告诉我们,语料库中的每一个单词出现在当前单词周围的概率是多少.
这个网络输出的各个单词的概率就是各个单词出现在输入词周围的概率.举例来说,如果输入词是'Soviet',那么诸如'Russia','Union'这样词对应的输出概率就会比较大;反之,'wagtermelon','kangaroo'这样不相关的词对应的概率值就会比较小.
为了训练这个神经网络,我们将会从语料库中提取单词对,用这些单词对作为训练样本.下面这个例子以 “The quick brown fox jumps over the lazy dog.” 这样一个句子为例进行讲解.简单起见,例子中使用了窗口大小为2,加粗的单词是输入词.
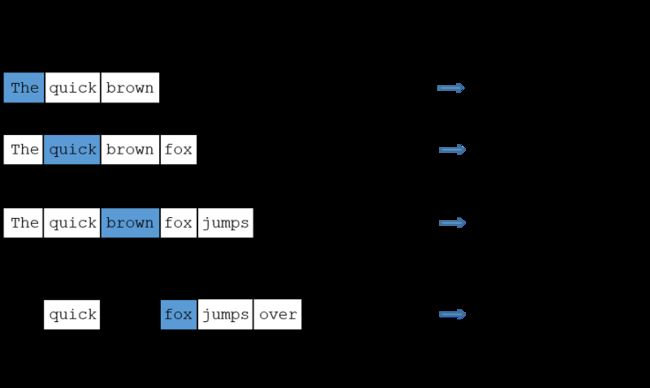
我们将会使用one-hot 向量来表示输入词.这个向量将会有10,000维(包含语料库中的每一个单词),在输入词对应的位置是1,其他位置全是0.
神经网络的结构图如下

值得一提的是,在这个网络的隐藏层的每一个神经元是没有激活函数的,并且输出神经元采用softmax算法输出结果.
举例来说,假设我们想要学习具有300个特征的单词向量,那么隐藏层的参数矩阵的维度将会是10,000*300.300个特征也正是谷歌新闻数据集的特征个数,可以直接从 这里下载. 本质上讲,特征的个数也是可以调节的超参数之一,需要根据预测结果进行选择.隐藏层的参数矩阵的每一行就是我们需要的单词向量.
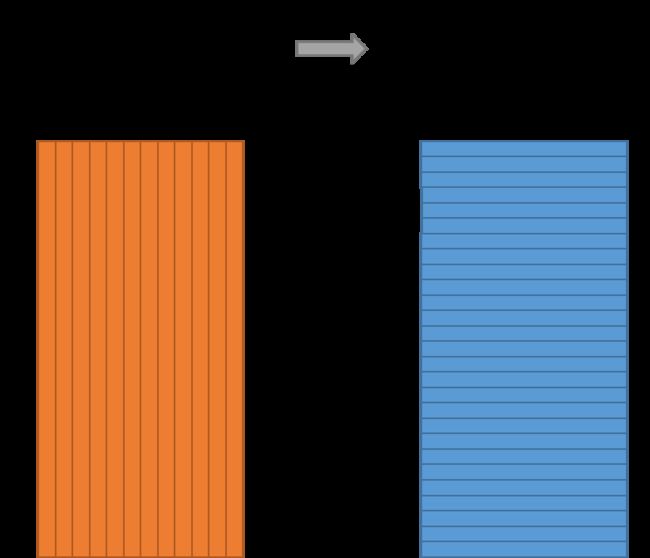
所以,整个模型的最终目的就是为了得到隐藏层的参数矩阵,输出层给出的结果将会直接被丢弃.输出层采用softmax方法进行分类,每一个输出神经元都会和单词隐藏层的单词向量进行点乘,然后取自然指数,除以公共分母得到输出的概率.下面给出一个以输入单词为'car'为例的过程:

如果两个不同的单词有相似的语境,那么我们的模型性该要输出相似的结果.而想要输出相似的结果,就需要具有相似的单词向量.换句话说,如果单词有相似的语境,那么这两个单词的单词向量就应该相似.
那么什么叫有相似上文语境呢?首先像'intelligent'和'smart'这样的近义词应该有着非常相似的语境.或者相关联的单词,例如'engine'和'transmission'这样的单词也应该有相似的语境.
利用这样一个特征,我们可以解决词根问题,因为像'ants'和'ant'这样同词根的单词使用的语境也是非常相似的.
可以观察到,这里的模型中每个单词是有两个word vector的,也就是有两个对应的向量的矩阵,一个用来表示中心词,一个用来表示语境.最后就是简单的采用两个矩阵直接逐元素相加的方法合成一个新的矩阵作为最终的单词向量.至于为什么这种做法更加精确嘛,就是玄学的范畴啦....Chris Manning 都呵呵一笑的原因,我还是暂时当个鸵鸟吧.
至此,模型已经建立完毕,但是仍然需要做一些调整才能使得这个模型能够被训练.因为在这么大的一个神经网络中进行梯度下降是十分缓慢.更严重的问题是,我们需要非常大的数据集才能够避免过拟合的产生.好在Word2Vec的作者在他们的第二篇论文.中解决了这些问题.这篇论文主要包括以下三个创新点:
1.将固定词组当成一个单词
2.通过采样(subsampling)常用词的方式减少训练样本
3.利用负采样(negative sampling)的方法调整优化目标,使得每个训练样本仅仅更新一小部分模型的参数.
值得一提的是,采样和负采样的方法不仅提高了模型训练的效率,而且提高了训练结果的准确性.
2.Improvement for training
本部分来自于word2vec的作者在该算法的第二篇论文.作者在论文中具体提出了几种可以改进计算效率的算法.包括频率采样,负采样等.本部分的主要内容参考自这篇博客.
2.1 Subsampling (filtering)
我们现在已经对于word2vec 有了一定程度上的了解,但是正如同前文提到的,这个算法需要大量的数据才能保证不会产生过拟合的现象;此外,训练过程中每一步的梯度更新都是很耗时的,因此需要考虑采用一些优化方案才能使得这个算法成为可行的.最简单的思路就是从语料库中减少一些不是很有价值的训练样本.
那么,我们不妨先来考虑一下是否存在一些不是很有价值的训练样本.答案是肯定的,可以考虑单词"the".英语中的这个定冠词的使用频率非常高,但是其所包含的价值就很低,在很多的词组中是可以忽略其含义的.这一点和香农的信息论的观点是不谋而合的,出现频率越高,可以近似的看做是出现的概率越大(大数定律),而出现的概率越大,这种情况所包含的自信息(Self-Information)就越小.通俗点说就是频率越高,信息量越小.因此,我们可以把这些信息量小的测试样本抛弃.
在这里的Subsampling算法选择的策略是对语料库进行筛选,筛选的方式是按照一定概率的丢弃一些单词对,丢弃的原则是根据单词对中的某一个单词的频率,丢弃的概率和单词的频率成正比.这一步可以算在数据预处理阶段,并没有多少难度,在此不再赘述.
2.2 Negative Sampling
这是论文中采用的第二个优化策略,这一次不再从输入数据出发,而是考虑更新步骤.在原始的word2vec的算法的设计当中,每一次的的样本输入,都要对全部的参数进行数据的更新.这是非常耗时而且价值并不是很高的.因此这里作者有开动了他的小脑袋瓜,机智的想出了Negative Sampling.就是通过修改损失函数,增加了几个错误的样本的损失,通过最小化新的损失函数可以实现使得正确的样例对应的损失减小,错误的样例的损失增大.这明显就是"抄袭"(just kidding)的max-margin的思路嘛!也就是和SVM的主要思路有相似之处.But/However/Nevertheless,it works!并且能够很大程度上减少更新整个参数向量的开销,每次只需要更新一个正确的样例和几个错误的样例对应的参数就好啦.
错误样本的选择是通过这样的一个公式给出的概率进行抽样的.其中3/4这个指数值,又是玄学大师的杰作,我们就不讨论啦先.在论文中,作者指出指出对于小规模数据集,选择5-20个negative words会比较好,对于大规模数据集可以仅选择2-5个negative words。

3.Homework
作业完成可称辛苦,一路踩坑无数.所幸坚持下来,大难不死,必有后福~
另外在此补充关于CBow的内容,视频中并没有明确的证明或者讲解,但是我想在这里进行一下简单的说明.

&emsp: 上述这个直观的表述可以说是很棒了.一言以蔽之,skip-gram的任务是用中心词推语境词;CBOW的任务是用语境推中心词.通过对神经网络的训练我们希望能够得到能最好地完成这两个任务的模型参数,而得到的这些参数中就有我们需要的单词向量,这样,我们最终极的目的就达成了.