Extremal Region(极值区域)文本定位与识别法-学习笔记(一)
最近做一个计算机视觉的项目,要将其中复杂场景中的文本识别率从92%进一步提升,挑战很大也很有意思。边阅读一些最新的文本定位与识别的论文,边在这里记下阅读笔记与翻译内容,慢慢研究。本人英语与专业水平有限,仅供学习参考,欢迎交流,请多指教。
Reference:Real-TimeScene Text Localization and Recognition Luk´aˇsNeumann Jiˇr´ı Matas 2012 IEEE
一:引言
现实场景的文本定位与识别是很多计算机视觉应用的关键部分。比如通过文本内容来搜索图片、在地图应用(如谷歌街景)中读取商标,或者辅助视觉障碍人员。
在图像中进行文本定位,是一项潜在计算代价非常高的任务,通常一个有N个像素的图像,2N(每个像素都有2种可能:选取做为像素子集中的像素或不选取,所以有2N个像素子集)个像素子集中任何一个都可能是符合的文字图像。文本定位处理这一难点时,采用了两种不同的方法:
(1) 用滑动窗口来将这种搜索限制在图像矩形的子集中,这将检测文字出现的子集数减少到cN(c是常数值,单尺度、单旋转方法时,c小于1;多尺度、多旋转、多倾斜等方法处理时c大于1)。
(2) 假定属于同一字符的像素有相似性质,则可以用连通域分析的方法,把像素分组成不同区域,以此来找到单独的字符。连通域分析根据用到的属性(颜色、笔划宽度等)而不同。
优点:其复杂性不依赖于文本的属性(尺度范围,方向,字体),而且它提供了可供OCR步骤中利用的分割。
缺点:对混乱和闭塞(clutter and occlusions)(会改变连通结构)敏感。
二:前人方法总结
1. B. Epshtein, E. Ofek, and Y.Wexler. Detecting text in natural scenes with stroke width transform. In CVPR2010, pages 2963 –2970.
将图像转为灰度图后进行Canny边缘检测,平行的边缘对用来计算笔划宽度,相似宽度笔划的像素被一起分进字符组。
缺点:对噪声和模糊敏感,因为它是基于成功的边缘检测的。而且它只提供单字符的分割,分割结果对于OCR模块不便利用。
2. J. Zhang and R. Kasturi. Character energy and link energy-based text extraction in sceneimages. In ACCV 2010, volume II of LNCS6495, pages 832–844, November 2010.
依然是基于边缘的方法,但用的是连通域算法。
3.K. Wang, B. Babenko, and S. Belongie. End-to-end scene text recognition. In ICCV 2011, 2011.
用滑动窗口的方法来将找到的多个单独的字符视作可见词,并用一个词典来将字符分组成单词。
优点:可以处理带噪声的数据。
缺点:被词典中的单词数限制了图像中能找到的单词。(他们实验中词典最多可以包含500个单词)
4.L. Neumann and J. Matas. A method for text localization and recognition inreal-world images. In ACCV 2010, volume IV of LNCS 6495, pages 2067–2078,November 2010.
L. Neumann and J. Matas. Text localization inreal-world mages using efficiently pruned exhaustive search. In ICDAR 2011,pages 687–691, 2011.
该方法将字符作为最大稳定极值区域(MSERs)来检测,并用MSER检测器得到的分割结果来进行文字识别。而MSER是Extremal Region的一种特殊形式,MSER的尺寸在不同的阀值下保持几乎(virtually?)不变。这种方法性能很好,但对于模糊图像或者低对比度的字符仍存在问题。

ER法与基于MSER的方法不同在于它检测所有ERs,而不仅是MSERs的子集,与此同时减少内存占用以保持相同计算复杂度和实时性能。
5. J. Matas and K. Zimmermann.A new class of learnable detectors for categorisation. In Image Analysis, volume 3540 of LNCS, pages541–550. 2005.
该方法抛弃了MSERs对稳定性的要求,并选择了一种依赖类型(不必稳定)的Extremal Regions。它使用图像矩作为单神经网络(monolithic neuralnetwork?)需要的特征,这个神经网络被训练用于特定形状集合(如纹理,特定字符)的识别。
而在ER法中,选择合适的ERs是通过一个序列分类器来实现实时效果的。该分类器是基于一种专门针对文字的新特征。再者,这个分类器是被训练用来输出概率大小的,因此可以提取一个字符的多种分割。
三:极值区域(ER)法简介
LukasNeumann与JiriMatas大牛的ER文本检测方法是一种实时的端对端文本定位与识别方法。该方法通过把文字检测问题处理为从Extremal Region(ERs)(极值区域)集合中进行有效序列选择,从而达到实时检测效果。ER检测器对模糊、光照、色彩、纹理变化、低对比度的文字都有很稳健的效果!!!其复杂度为O(2pN)(p指用到的通道数(projections投影数))。

这个方法在ICDAR 2011dataset上取得了state-of-the-art的效果,而且是第一个对end-to-end text(端对端文字)识别报告结果的。在更有挑战的StreetView Text dataset上,该方法也取得了state-of-the-art的效果。(PS:在2011的ICDAR比赛中,最好的方法仅能正确地定62%的单词,而且这个数据集并非完全现实场景的,它的单词都是水平的,位于图像显著部分,没有透视扭曲或者明显的噪声。)
ICDAR 2011 dataset.上的测试结果,对反光以及穿过文字的线的稳健检测效果。

StreetView Text dataset上的测试效果,对高噪声与模糊效果稳健
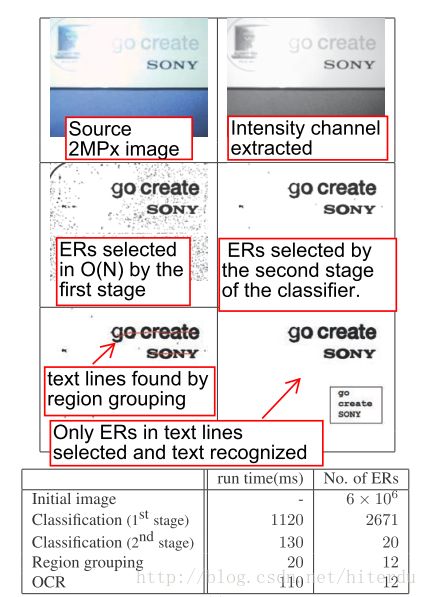
该方法在分类第一阶段时,每一个ER是字符的可能性是用novel features(每个区域的计算复杂度为O(1))来估计的。只有局部最大可能性的ERs被选中,作为第二阶段处理的ERs。
第二阶段的分类是用计算代价更高的特征来进一步改善。然后,一种高效的带反馈回路的穷举搜索方法被用于把ERs分组成词以及选择最有可能的字符分割。最后,文字在OCR阶段被识别出来(用synthetic fonts(合成字体?)来训练识别器)。
另外,引入了一种新的梯度级投影(gradientmagnitude projection),它可以利用边缘去减少ERs。(引入该梯度投影,可以使ER detector检测到94.8%的字符。)
To be continued...