从未降级的搜索——主搜索分层优化
摘要
多年以来,主搜索的集群架构和排序算法相对比较单一,一定程度上制约了搜索业务的发展。本文主要介绍主搜索最新采用的索引分层技术。这种分层技术把主搜索集群架构从二维扩展到了三维。基于这种三维的新架构,主搜索可以根据不同的应用场景,选择不同的检索和排序算法,从而更好的提升主搜索的检索性能与检索效果。实践表明,这种分层技术能提升主搜索120%的检索性能和6%的搜索GMV。
1. 背景
主搜索多年以来一直采用二维集群架构来提供淘宝网商品的检索服务,其结构如图 1所示。主要的检索流程如下:
step 1. SP向QRS提交查询请求,QRS根据查询内容和Searcher的状态信息动态选择出一行searcher机器,把查询转发到这些searcher机器上进行检索。每个searcher只包含部分商品的索引,而被选择出的一行searcher则包含一个完整商品的索引。
step 2. Searcher机器根据查询,在索引的商品中检索符合查询串的商品,并对这些商品进行排序后返回top-k结果给QRS。Searcher机器之间查询是并行的处理,各searcher使用的检索与排序算法都一样。
step 3. QRS根据一定的规则对searcher返回的结果进行合并和排序,然后返回top-k’结果给SP。
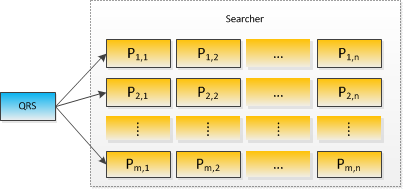
图1. 主搜索集群二维结构示意图
这种二维结构的集群架构和在这基础上的检索流程主要有以下几个问题:
- 集群需要的机器多。目前主搜索需索引的商品数量近10亿。在一定的查询响应时间下,单机的索引量非常有限。例如单机索引4000万商品,那就需要25台机器才能索引完整的商品数据。为了达到一定的服务规模,需要的行数也会特别多。如果单行的服务能力为1000QPS,那么在10万QPS的压力下,需要100行,共2500台searcher机器。
- 查询范围大,检索效率相对较低。QRS挑出的一行searcher索引了完整的商品数据。在这完整的商品中,与查询相关的商品可能有上百万个,而QRS最终只返回几十条最相关的结果给用户。因此绝大部分的商品是对查询结果没有用的,而对这些相关性小的商品的检索降低了检索的效率。主搜索中存在大量的冷门商品,它们与绝大部分的查询都不相关,索引和检索这些冷门商品都会浪费一定的资源。
- 支持索引结构单一,可使用检索优化方法较少。因为各个searcher中索引的结构是一致的,一旦采用了一种全局序索引优化就难再使用其它的全局序优化。 单一的全局序优化虽然能提升针对这种按全局序排序的查询性能,但对其它类型的排序就会有损害。在未做分层优化之前,主搜索的索引一直采用按商品下架时间(END_TIME)全局排序后进行索引。它对按END_TIME排序的查询能提升不少性能,但对按人气或销量排序的查询就非常低效。
- 对检索和排序的多样性支持并不友好。例如最终查询结果可能需要包含部分销量高的商品,部分相关性好的商品还需要照顾展示商品的多样性。基于这种结构需要多次完整查询才能得到结果,从而制约了相关性选择算法的问题空间。
显然,上述的问题对主搜索引擎都是致命的,它从一定程度上限制了主搜索的规模以及与搜索相关的业务发展,急需要一种新的方法来解决或缓解上述的问题。
2. 相关知识
在介绍主搜索具体的分层优化方法之前,我们先简单介绍一下搜索引擎中常用优化技术—索引剪枝(又称索引截断)。因为主搜索中使用三维集群架构,以及在些架构上采用的检索方法都是这些基础索引截断技术的演化版。通常索引截断可分为静态索引截断和动态索引截断:在静态索引截断中,以下三种方法比较常用:
- 根据文档静态质量分把文档划分成多个类别。例如在全网搜索中根据网页质量可把网页划分成正常网页和垃圾网页,同样主搜索中根据商品销量等可把商品划分成热门商品和冷门商品。这样我们就可以针对不同类别文档应用不同的索引结构和检索策略以便更高效的进行大规模的文档索引与检索。
- 根据每个索引词出现的文档按特定的特征对这些文档进行筛选。这个特征可以是文档的全局特征,也可以是term-doc的特征。例如在全网搜索中可以根据BM25分数挑出与索引词相关性程度较高的文档单独建成一个倒排链。在主搜索中可以根据商品的质量挑出与这个索引词最相关的高质量商品单独建倒排链。在搜索时,我们可以优先使用这个截断链快迅的找到与这个词最相关或最热门的文档。
- 根据文档中每个词的特性挑选出最能代表文档内容的词来代替全文内容,以减少索引量。例如,主搜索中的每个商品只挑选商品标题和SKU中的词进入索引,以减少倒排索引的大小或减少引入不相关的内容。
动态索引剪枝的技术比较多,但其剪枝算法通常与排序模型相关。多阶段的检索与排序是目前比较常用的方法。这种方法把文档的查询与排序划分成多个阶段,越靠前的阶段计算单个文档相关性所需的时间越少,但找出的文档越多;越后的阶段计算单个文档相关性所需要的时间越多,找到的文档越少。
主搜索一直使用二阶段排序模型来优化检索的性能。第一阶段商品的海选,先前主搜索默认按商品的下架时间海选出数万个最近会下架的商品。这主要是为了照顾快下架的商品有更多的展示机会。这些选出的商品不区分质量,只匹配查询词。第二阶段商品的精选阶段,对海选出的商品利用相关性等各种特征计算最匹配几十条商品返回给用户。二阶段的排序模型给主搜索带来的很大的性能提升,但由于后面阶段的输入依赖于前面阶段的输出。例如第一阶段输出的商品质量不高,则直接影响第二阶段的排序效果。所以主搜索为了保证二阶段的商品输入的质量,从一阶段中挑选了数千个文档给二阶段排序,但这些输入的文档绝大部分最终没有返回。
3. 分层优化
3. 1 辅链优化
主搜索先前采用的二维结构比较直观,也容易理解,但它很难满足检索性能与排序多样性的需求。主搜索的流量组成非常多样化,有来自网页、无线和各种应用的请求。在这些请求中,包含各种各样的商品排序需要,其中按人气排序和按END_TIME在主搜索查询流量中占比最大,它们分别是无线搜索与网页搜索的默认排序方式。
为了更快的支持END_TIME排序的查询处理速度,主搜索的索引一直按END_TIME全局序排序。当索引全局按END_TIME有序,就能通过二分查找快速的定位到满足查询条件商品的开始位置,可以略过很多相关但不符END_TIME的商品。但因为第一阶段的排序不包含其它信息,所以找出的文档质量参差不齐,因此需要找较多的文档给第二阶段的排序才能挑选出合适的商品给用户。
按人气排序的查询显然不能利用END_TIME排序的索引优化,所以它只能从前到后找人气高的并符合查询条件的商品。这种按人气排序的查询在一阶段选出的商品人气分很高,通常人手高的商品质量也比较好,所以二阶段只需要对少量的商品进行重排序即可找到非常相关的文档。但由于索引的商品按END_TIME排序,人气高的相关商品就会随机的出现索引的不同位置,所以在第一阶段需要查找的文档数量会比较多。
针对这个问题,主搜索目前使用人气辅链(截断链)来加速查询。人气辅链构建过程如下:
- 针对倒排链较长的词,遍历出现这个词的全部文档,根据一定的规则把人气分高的文档保存到另一个链中。每个词的筛选规则与出现这个词的文档整体水平相关,因此各个词筛选的阈值都会不一样。
- 所有的辅链组成一个辅链索引,辅链中文档的出现顺序与原始链中的顺序完全一致。
当有了人气辅链,按人气排序的查询在第一阶段就可以根据辅链信息快速找到人气高的商品。但使用辅链主要有以下两个问题:
- 使用辅链查找发现得到的商品数量不够,则还需要重新从原始链中重新查找。
- 使用辅链容易造成符合要求的商品没有第一阶段被召回。
商品没有被主要原因是各个词建出辅链的人气阈值都不一样,文档在能进词A的辅链但可能进不了词B的辅链。当同时使用多个辅链查询就出现这个问题。所以主搜索在一次查询中最多选一个词的辅链。虽然辅链在一定程序上能加快选定排序查询的检索速度,但同时增加了构建索引的复杂程序。特别是存在实时索引的情况下,构建辅链的开销将会非常大,另外辅链增加索引存储的开销。
3. 2 分层优化
索引全局序和辅链加速了检索速度,但没有解决低质量商品对查询的影响:1. 低质量商品通常包含一大堆热门查询词,所以对热门查询都需要重复的计算这些低质量的商品,但这些商品最终都不会被展示。2. 低质量商品占用大量索引存储, 由于绝大部分低质量的商品展示机会很少,重复的存储这些信息就的有点浪费了。另外,辅链中文档号与主链是顺序是一致的,所以辅链也没有解决索引结构单一的问题。最后,虽然辅链上的大部分文档在特定排序下优化于主链中的文档,但在查询仍需要完整遍历辅链,因为最相关的文档有可以出现在辅链的最尾部。
针对低质量商品的影响,一个简单的想法就是根据商品的质量把商品划分成多个类别,然后用不同的集群索引不同类别的文档。检索时,如果高质量的集群找出的商品数已经足够好,就直接返回检索结果。只有当高质量集群检索到的文档数量不够时,才会向低质量集群检索结果,最终合并检索结果返回。这种做法带来的好处是减少查找商品的范围,同时也降低质量商品对查询结果的影响。因为高质量的集群中的商品是原先的一个子集,包含的商品数量比完整的少很多。而且低质量商品不会现象先前一样重复的参与计算,因为这些低质量商品已经被移到另一个集群索引中。如果绝大部分的查询都可以通过高质量集群就可以满足,那么向低质量机群查询数就会变少,因此低质量集群所需要的行数会高质量的行会少很多,从而可以节省很多机器数量。当然不同质量的集群仍可以使用不同的辅链来优化不同排序的查询。
商品按质量分层部分解决了机器数量多与查找范围广的问题,仍没有解决索引结构单一与支持排序算法种类少的问题。我们知道辅链中包含选定排序下最好的文档信息,所以它能较大的提升特定排序查询的检索速度。由于它构建成本大,仍需要全部遍历限制了不能大规模的使用。我们可以把辅链索引的思想进一步的扩展,即把特定排序的辅链索引的中商品单独做成一个集群。单独做成一个集群的好处是:1. 索引商品的顺序不再受原始链的影响,可以灵活的采用自己特定排序方式,可使用的排序方案就会变多。2. 单独特定排序的集群的倒排链中得分高的商品在前面,得分低的在后面,检索算法很容易做动态截断,即不再需要完整的查找整个链。3.索引的构建与维护代价比使用辅链小。
我们可以针对不同排序的查询构建不同的小集群,虽然这些小集群索引的商品可能重复,但它极大减小检索商品的范围和提升检索速度,同时做多样化的商品检索也变比很容易,只需要向不同的小集群查询相应数量的商品即可。
有了低质量和高质量集群,再加按不同排序优化后的小集群,整个搜索集群的结构就可以拓展成如图2所示的三维架构。相对于二维结构,主要是增加集群维度。各维度的集群索引的商品集合如图3所示,其中高质量与低质量集群索引的商品是没有交集,小集群索引的商品是有交集的。
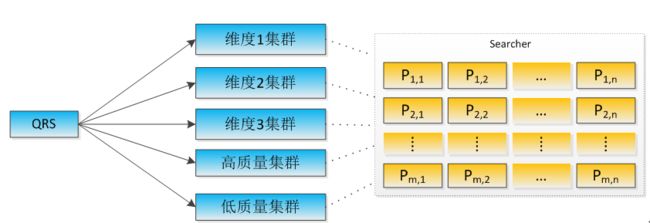
图2 基于分层的三维集群结构图

图3. 各集群索引文档的范围示意图
3. 3 主搜索的分层
主搜索目前采用的分层方案与上述讨论的类似,首先由算法团队根据一定的规则把商品分成了两类,good与bad。使用两个机群分别索引这两类商品。这种结构下,虽然索引完整数据的列数没有变大,good集群如果已经能满足绝大部分的查询需求,bad集群的查询量相对就较少。所以bad集群只需少数几行就可以满足搜索需要。在主搜索中,仍超过50%商品在good集群中,所以good集群索引的文档数量还是非常大的。由于查询总量还是不变,因此good集群需要行数未变。其次,其它针对人气排序等的查询,从Good集群的商品中挑选出人气分最高的商品单独组成一个集群,称为Excellent集群。Excellent机群的商品是Good机群的商品的子集,商品约占Good机群商品的15%。其结构如图4所示,有了这三个集群,其主搜索查询流程如下:
- 对人气排序的查询:首先查Excellent集群,如果Excellent集群查找到的文档不满足要求,则丢弃该结果,重新到Good 和Bad集群查询。否则,直接使用Excellent集群的结果返回。其它排序时则不查Excellent集群,直接查Good和Bad集群。
- 对非人气的查询,优先查询good集群,如果good集群返回的商品不满足相应条件,则会向bad机群再次查询结果,并把good与bad集群的商品合并后返回。Good与bad集群都会使用辅链加速不同排序查询的检索速度。
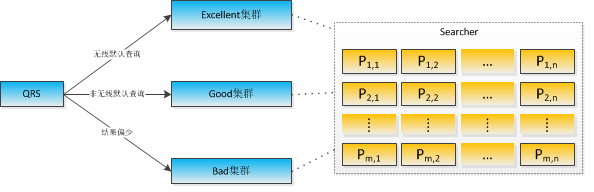
图4 主搜索分层后的三维结构示意图
4. 分层优化的效果
Good-Bad集群拆分极大减少了主搜索使用的机器数量。未拆分前一行有18列,拆分后Good机群索引近54%的商品,划分为9列。Bad机群索引46%的商品,划分为5列。Good集群承担的总流量不变,Bad机群承担的流量减少了50%。并且在Bad集群中商品信息明显少于Good集群,所以Bad集群的查询速度比Good快,一行的服务能力也比Good强。目前主搜索Good与Bad集群的行数比约为2:1,所以经过拆分后,总节约机群的百分比约为36%,而整体性能的提升约为40%。由于绝大多数的商品仍在Good集群,所以对检索的效果基本无影响。
Good-Bad拆分后,Bad集群的压力变小,但Good机群的性能仍是瓶颈。Excellent机群则分流按人气排序的查询。目前Excellent机群索引的商品数为Good机群的15%,划分成2列。约有45%流量走Excellent集群,这些走Excellent的查询中,约28%的查询由于不满相关条件重新查Good和Bad集群。Excellent集群的行数与Good机群约为8:3。虽然拆分Excellent集群整体使用的机器数量并没有减少,但它给Good集群分担约32%的流量。这些走Excellent集群的查询通常所需要的计算资源比较多,实验表明Good机群的性能比未拆分前提升近1倍,而Excellent-Good-Bad相对于只有Good-Bad机群时,整体提升了60%。
经Excellent-Good-Bad集群的拆分后,主搜索整体性能提升约为120%,那其搜索效果如何呢?以下是算法团队提供的Excellent拆分前后的一些指标变化。
Excellent-Good分层对无线流量的影响如图 5所示。分层后android客户端整体展现商品数量下降2.73%,转化率、CTR、客单价、笔单价、成交金额没有明显变化。iphone客户端整体展现商品数量下降3.36%,CTR下跌2.61%,客单价下跌0.63%,笔单价下跌0.66%,成交金额下跌0.68%。展现商品数量下降的原因是Excellent集群中的商品多样性有待丰富。
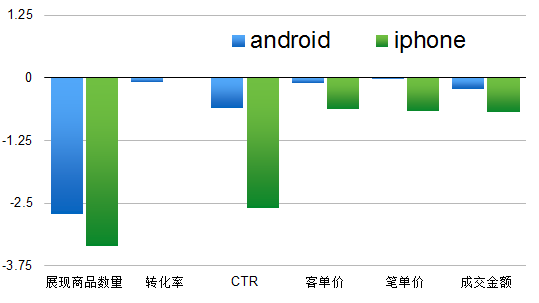
图5 Excellent-Good分层对无线流量的影响
分层对卖家的影响如图 6所示,分层后大卖家影响最小,中卖家其次,小卖家以及无成交卖家影响交大。小卖家以及无成交卖家PV和展现商品数下跌较明显。这是因为小卖家或无成交卖家在Excellent中的商品比例相对于大卖家少。
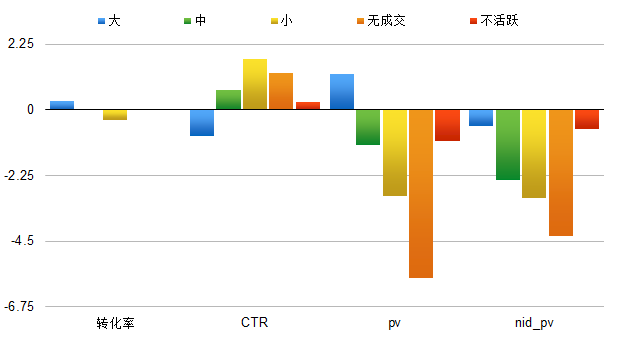
图6 Excellent-Good分层对卖家商品数的影响
分层对行业数据的影响如图7所示,我们可以发现分层对各行业展示商品的数量都有略微的下降。
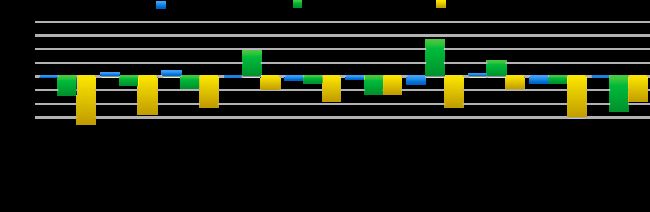
图7 Excellent-Good对行业数据的影响
5. 分层相关的挑战
分层优化给主搜索带来极大的性能提升,但优化过程中也碰到了一些挑战:
- 如何划分商品到各个机群中,以及拆分多少个机群比较合适的问题。商品的划分通过算法团队的不懈努尽,分层后的检索的一些关键指标如转化率、CTR、GMV、客单价等指标基本没有影响,但我们也注意到商品、商家的多样性都有略微的影响,如何减少影响将是未来的研究内容。
- 实时build性能。分层后有些机群的列数比较少,但因商品质量较高,商品发生变化的概率也较大,所以这些机群需要实时build的文档也多。例如Excellent集群列数只有2列,单台机器需要实时build的文档是good机群的3倍,bad机群的4倍。 为了缓解build的压力,线上开启异步build方式,即多个文档处理线程进行处理。多线程处理文档虽然能提升build的性能,但它占用检索资源,容易导致机器抖动,从而影响整个机群的性能。
- 消息系统的挑战。swift作为主搜索的消息系统,在流量高峰向swift机群请求消息容易引起网络堵塞等问题。