AlexNet论文总结
1.Relu激活函数的使用
使用ReLU激活函数,要比使用常用的的费线性激活函数如sigmoid,tanh等函数,网络的训练速度要快上好几倍。

ReLU函数为什么可以提高训练速度?
一下内容借鉴了Physcal博客ReLU激活函数
传统sigmoid函数的特点(logistic-sigmoid。tanh-sigmoid)
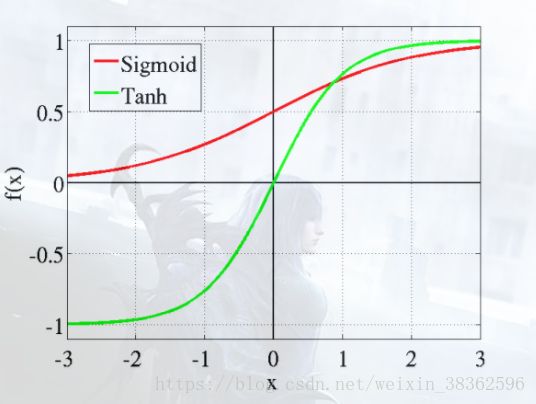
从图上看,非线性的sigmoid的函数对中央区的信号增益较大,两侧的信息增益较小(从函数的斜率上看,网络在进行反向传播时,激活函数的导函数会以一个因数相乘得到参数的变化量)
从神经科学来看,中央为神经元的兴奋态,两侧为神经元的抑制态。
近似生物神经网络的激活函数 softplus&ReLU

这个模型对比有三点变化:
- 单侧抑制(可以看到激活函数的一侧的导函数为0,不产生兴奋)
- 相对宽阔的兴奋边界
- 稀疏激活性
(emmmmmm就我看来稀疏激活性好像包括了单侧抑制的这个变化)
下面这一段为自己的思考总结emmmm可能出现错误
单侧抑制
传统的sigmoid函数,当x取极大或者极小的时候,倒数近似为0,此时映射到神经元上就是抑制的状态,而只有在中央区域,神经元处于兴奋状态。这和我们所认知的神经元的抑制兴奋状态不相符合。(应一侧为兴奋状态,一侧为抑制状态,即所谓的单侧抑制)
相对宽阔的兴奋边界
我们观察sigmoid的函数的形状,发现在x>2之后其倒数基本上就为0,如果数据未做归一化处理,就会产生一个梯度弥散的问题(梯度弥散问题后文会做分析)。例如如alexnet论文中所述的那样。其输入数据的预处理只是将每张图片256*256的像素减去了平均像素.(当然alexnet里面也采用了局部归一化的tirck)如果经过卷积后得值未被归一化,就会造成梯度小,模型学习慢稀疏激活性
下面内容援引博客ReLU激活函数
在神经科学方面,除了新的激活频率函数之外,神经科学家还发现了神经元的稀疏激活性。
还是2001年,Attwell等人基于大脑能量消耗的观察学习上,推测神经元编码工作方式具有稀疏性和分布性。2003年Lennie等人估测大脑同时被激活的神经元只有1~4%,进一步表明神经元工作的稀疏性。
从信号方面来看,即神经元同时只对输入信号的少部分选择性响应,大量信号被刻意的屏蔽了,这样可以提高学习的精度,更好更快地提取稀疏特征。
从这个角度来看,在经验规则的初始化W之后,传统的Sigmoid系函数同时近乎有一半的神经元被激活,这不符合神经科学的研究,而且会给深度网络训练带来巨大问题。
Softplus照顾到了新模型的前两点,却没有稀疏激活性。因而,校正函数max(0,x)成了近似符合该模型的最大赢家。
1.1 信息解离
当前,深度学习一个明确的目标是从数据变量中解离出关键因子。原始数据(以自然数据为主)中通常缠绕着高度密集的特征。原因是这些特征向量是相互关联的,一个小小的关键因子可能牵扰着一堆特征,有点像蝴蝶效应,牵一发而动全身。
基于数学原理的传统机器学习手段在解离这些关联特征方面具有致命弱点。
然而,如果能够解开特征间缠绕的复杂关系,转换为稀疏特征,那么特征就有了鲁棒性(去掉了无关的噪声)。
1.2 线性可分性 稀疏特征有更大可能线性可分,或者对非线性映射机制有更小的依赖。因为稀疏特征处于高维的特征空间上(被自动映射了)
从流形学习观点来看(参见降噪自动编码器),稀疏特征被移到了一个较为纯净的低维流形面上。
线性可分性亦可参照天然稀疏的文本型数据,即便没有隐层结构,仍然可以被分离的很好。
1.3 稠密分布但是稀疏 稠密缠绕分布着的特征是信息最富集的特征,从潜在性角度,往往比局部少数点携带的特征成倍的有效。
而稀疏特征,正是从稠密缠绕区解离出来的,潜在价值巨大。
1.4 稀疏性激活函数的贡献的作用: 不同的输入可能包含着大小不同关键特征,使用大小可变的数据结构去做容器,则更加灵活。
假如神经元激活具有稀疏性,那么不同激活路径上:不同数量(选择性不激活)、不同功能(分布式激活),
两种可优化的结构生成的激活路径,可以更好地从有效的数据的维度上,学习到相对稀疏的特征,起到自动化解离效果。
解决梯度弥散问题(Vanishing Gradient Problem)
这也是为啥用ReLU训练速度会加快的重要原因
从反向传播的推倒式子中我们可以知道,在每一个layer都要乘以当前层的输入神经元值,激活函数的一阶导数。Grad=Error⋅Sigmoid′(x)⋅x。如果用sigmoid函数,会面临两个问题:
- 如果 x在-1和1之间,x值会对Grad进行缩放
- 如果 x不在-1和1之间,Sigmoid′(x)会对Grad进行缩放
这样经过每一层后,其参数变化的速度都会越来越慢,梯度不停衰减使得网络学习越来越慢。
但是我们的ReLU函数就不一样了,其激活函数的一阶导数为1,且只在一端饱和,使得模型的收敛速度维持在一个稳定的状态。
这也是为什么使用ReLU函数会使模型的训练比用sigmoid函数速度快这么多
2.多GPU进行训练(taining on Multiple GPUs)
单个GTX 580 GPU只有3GB的内存,从而限制了能由它训练出的网络的最大规模。实验表明使用120万训练样本训练网络已足够,但是这个任务对一个GPU来说太大了。因此,本文中的网络使用两个GPU。当前的GPU都能很方便地进行交叉GPU并行,因为它们可以直接相互读写内存,而不用经过主机内存。我们采用的并行模式本质上来说就是在每一个GPU上放二分之一的核(或者神经元),我们还使用了另一个技巧:只有某些层才能进行GPU之间的通信。这就意味着,例如第三层的输入为第二层的所有特征图。但是,第四层的输入仅仅是第三层在同一GPU上的特征图。在交叉验证时,连接模式的选择是一个问题,而这个也恰好允许我们精确地调整通信的数量,直到他占计算数量的一个合理比例。
最终的结构有点像Ciresan等[5]采用的柱状卷积神经网络,但是本文的列不是独立的(见图2)。与每个卷积层拥有本文一半的核,并且在一个GPU上训练的网络相比,这种组合让本文的top-1和top-5错误率分别下降了1.7%和1.2%。本文的2-GPU网络训练时间比一个GPU的时间都要略少。
3.局部相应归一化
4.重叠池化
CNNs的池化层归纳了同一个核特征图中的相邻神经元组的输出。例如池化kernel_size=3,池化stride=2。
5.降低过拟合
5.1数据增强
第一种形式是生成平移图像和水平翻转图像。做法就是从256x256的图像中提取随机的224x224大小的块(以及它们的水平翻转),然后基于这些提取的块训练网络。这个让我们的训练集增大了2048倍((256-224)2*2=2048)。网络通过提取5个224x224块(四个边角块和一个中心块)以及它们的水平翻转(因此共十个块)做预测,然后网络的softmax层对这十个块做出的预测取均值。
第二种数据增强是改变训练数据的RGB通道的强度。(这个方法没看懂。。直接引用了)
特别的,本文对整个ImageNet训练集的RGB像素值进行了PCA。对每一幅训练图像,本文加上多倍的主成分,倍数的值为相应的特征值乘以一个均值为0标准差为0.1的高斯函数产生的随机变量。因此对每一个RGB图像像素Ixy=[IRxy,IGxy,IBxy]T加上如下的量

这里Pi,λi分别是RGB像素值的3x3协方差矩阵的第i个特征向量和特征值,αi是上述的随机变量。每一个αi的值对一幅特定的训练图像的所有像素是不变的,直到这幅图像再次用于训练,此时才又赋予αi新的值。这个方案得到了自然图像的一个重要的性质,也就是,改变光照的颜色和强度,目标的特性是不变的。这个方案将top-1错误率降低了1%。
6.Dropout层引入
这个Dropout层在AlexNet中第一次被提出,作者用他来做模型的泛化能力,减少过拟合。
在Dod_Jd的博客中要较为通俗的和详细的解释CNN中的Dropout的理解(反正我是看懂了233333)
Dropout强迫一个神经单元,和随机挑选出来的其他神经单元共同工作,达到好的效果。消除减弱了神经元节点间的联合适应性,增强了泛化能力。