本文记录在Canal实战中遇到的问题和重点
一、关于高可用 HA
canal的高可用,有几个维度
1.数据库高可用
目前canal支持 数据库的master和standby,但需要修改默认配置打开
在zk的cursor中可以看到数据库信息,是否正常切换
数据库HA 实现分析
由于我们知道canal是订阅binlog的,那么当主宕机后,canal去连接standby,如何找到新的position呢,我们进行简单分析
首先了解mysql主从复制的基本流程,主维护一个binlog,从会维护一个relay log,进行回放。
通常情况下,从并不记录自己的binlog,因为要避免多个从引起的多次写入。但如果只有一个从的情况下,可以开启--log-slave-updates
这样从也会维护一份binlog,但这些都不重要,你需要知道确认的一点是 不管从维护不维护binlog,主从的binlog都是不一样的,你单独连数据库,查看binlog名称就可以看出来!
回过来分析canal的数据库HA
关键的类为 HeartBeatHAController
这个类反向追踪,会在instance模块的初始化doInitEventParser中创建。
心跳检测
MysqlDetectingTimeTask
首先会有一个核心的心跳任务,默认每隔3s执行一次心跳,配置为detectingIntervalInSeconds
timer.schedule(heartBeatTimerTask, interval * 1000L, interval * 1000L);
这个task的任务就是去检测心跳,默认我们通过select 1语句去进行检测
public void run() {
try {
if (reconnect) {
reconnect = false;
mysqlConnection.reconnect();
} else if (!mysqlConnection.isConnected()) {
mysqlConnection.connect();
}
Long startTime = System.currentTimeMillis();
// 可能心跳sql为select 1
if (StringUtils.startsWithIgnoreCase(detectingSQL.trim(), "select")
|| StringUtils.startsWithIgnoreCase(detectingSQL.trim(), "show")
|| StringUtils.startsWithIgnoreCase(detectingSQL.trim(), "explain")
|| StringUtils.startsWithIgnoreCase(detectingSQL.trim(), "desc")) {
mysqlConnection.query(detectingSQL);
} else {
mysqlConnection.update(detectingSQL);
}
Long costTime = System.currentTimeMillis() - startTime;
if (haController != null && haController instanceof HeartBeatCallback) {
((HeartBeatCallback) haController).onSuccess(costTime);
}
} catch (SocketTimeoutException e) {
if (haController != null && haController instanceof HeartBeatCallback) {
((HeartBeatCallback) haController).onFailed(e);
}
reconnect = true;
logger.warn("connect failed by ", e);
} catch (IOException e) {
if (haController != null && haController instanceof HeartBeatCallback) {
((HeartBeatCallback) haController).onFailed(e);
}
reconnect = true;
logger.warn("connect failed by ", e);
} catch (Throwable e) {
if (haController != null && haController instanceof HeartBeatCallback) {
((HeartBeatCallback) haController).onFailed(e);
}
reconnect = true;
logger.warn("connect failed by ", e);
}
}
当3次检测失败后,执行切换doSwitch方法
public void onFailed(Throwable e) {
failedTimes++;
// 检查一下是否超过失败次数
synchronized (this) {
if (failedTimes > detectingRetryTimes) {
if (switchEnable) {
eventParser.doSwitch();// 通知执行一次切换
failedTimes = 0;
} else {
logger.warn("HeartBeat failed Times:{} , should auto switch ?", failedTimes);
}
}
}
}
切换时的业务逻辑
// 处理主备切换的逻辑
public void doSwitch() {
AuthenticationInfo newRunningInfo = (runningInfo.equals(masterInfo) ? standbyInfo : masterInfo);
this.doSwitch(newRunningInfo);
}
public void doSwitch(AuthenticationInfo newRunningInfo) {
// 1. 需要停止当前正在复制的过程
// 2. 找到新的position点
// 3. 重新建立链接,开始复制数据
// 切换ip
String alarmMessage = null;
if (this.runningInfo.equals(newRunningInfo)) {
alarmMessage = "same runingInfo switch again : " + runningInfo.getAddress().toString();
logger.warn(alarmMessage);
return;
}
if (newRunningInfo == null) {
alarmMessage = "no standby config, just do nothing, will continue try:"
+ runningInfo.getAddress().toString();
logger.warn(alarmMessage);
sendAlarm(destination, alarmMessage);
return;
} else {
stop();
alarmMessage = "try to ha switch, old:" + runningInfo.getAddress().toString() + ", new:"
+ newRunningInfo.getAddress().toString();
logger.warn(alarmMessage);
sendAlarm(destination, alarmMessage);
runningInfo = newRunningInfo;
start();
}
}
首先是判断正在运行的是主还是从,支持来回切换。
接下来可以清晰的看到,先执行stop,停止目前的复制,再是输出日志,最后重新start,此时start的running 已经采用新的切换后的Info。
重新启动start后,这时候主要就要去搞清楚,是如何找到新的position
// 4. 获取最后的位置信息
long start = System.currentTimeMillis();
logger.warn("---> begin to find start position, it will be long time for reset or first position");
EntryPosition position = findStartPosition(erosaConnection);
protected EntryPosition findStartPosition(ErosaConnection connection) throws IOException {
if (isGTIDMode()) {
// GTID模式下,CanalLogPositionManager里取最后的gtid,没有则取instanc配置中的
LogPosition logPosition = getLogPositionManager().getLatestIndexBy(destination);
if (logPosition != null) {
return logPosition.getPostion();
}
if (masterPosition != null && StringUtils.isNotEmpty(masterPosition.getGtid())) {
return masterPosition;
}
}
EntryPosition startPosition = findStartPositionInternal(connection);
if (needTransactionPosition.get()) {
logger.warn("prepare to find last position : {}", startPosition.toString());
Long preTransactionStartPosition = findTransactionBeginPosition(connection, startPosition);
if (!preTransactionStartPosition.equals(startPosition.getPosition())) {
logger.warn("find new start Transaction Position , old : {} , new : {}",
startPosition.getPosition(),
preTransactionStartPosition);
startPosition.setPosition(preTransactionStartPosition);
}
needTransactionPosition.compareAndSet(true, false);
}
return startPosition;
}
- 当使用gtid时,可以看到是通过gtid来进行新的postion定位的
- 不使用gtid时
protected EntryPosition findStartPositionInternal(ErosaConnection connection) {
MysqlConnection mysqlConnection = (MysqlConnection) connection;
LogPosition logPosition = logPositionManager.getLatestIndexBy(destination);
if (logPosition == null) {// 找不到历史成功记录
.....
} else {
if (logPosition.getIdentity().getSourceAddress().equals(mysqlConnection.getConnector().getAddress())) {
....
} else {
// 针对切换的情况,考虑回退时间
long newStartTimestamp = logPosition.getPostion().getTimestamp() - fallbackIntervalInSeconds * 1000;
logger.warn("prepare to find start position by switch {}:{}:{}", new Object[] { "", "",
logPosition.getPostion().getTimestamp() });
return findByStartTimeStamp(mysqlConnection, newStartTimestamp);
}
}
}
一般生产我们使用zk进行position的保存,可以看到针对切换的情况,可以看到是通过时间戳进行定位的
canal.instance.fallbackIntervalInSeconds
canal发生mysql切换时,在新的mysql库上查找binlog时需要往前查找的时间,单位秒
说明:mysql主备库可能存在解析延迟或者时钟不统一,需要回退一段时间,保证数据不丢
默认60
然后就在binlog里面根据时间找到startPosition
- 其他:我们公司采用了proxy的策略,作为数据库的路由,经测试发现,在主库宕机时,切换过程30s,无法提供服务,所以仍然可以心跳失败,重新寻找位点,这里有个坑,重新寻找位点后,虽然不影响业务,但zk中的serverid和binlogName对应不起来
2.canal Server的高可用
canal的高可用,需要通过zookeeper实现,这个也简单,就是启动2个server,会进行抢占,在zk上可以看到,destinations节点中的信息,有利于帮助理解实现。虽然在destinations会显示多个 server,但是在running那里可以看到,最终执行的server,挂掉一个,会自动切换
3.client的高可用
这个我得试试,首先在官方example中,有2种connector,一直是SimpleCanalConnector,另一种是ClusterCanalConnector
- SimpleCanalConnector
2个同时打开,由于每次connector都会释放,所以2个程序一直while循环时,建立连接的会得到数据,每次都不固定 - clusterCanalConnector
打开第一个后,在zk上1001下可以看到running的client信息,打开第二个只会和zk保持ping的信息
当关闭第一个后,第二个会开始工作,zk上的running信息改变
二.数据一致性问题
方案评估的时候,被否定,在mysql主从结构中,复制的机制,如果mysql没有问题,但是复制机制出了问题,出现主主或者主从数据不一致的情况 。是否有报警,是否能恢复?
1.mysql 的复制机制
复制如何工作
整体上来说,复制有3个步骤:
(1) master将改变记录到二进制日志(binary log)中(这些记录叫做二进制日志事件,binary log events);
(2) slave将master的binary log events拷贝到它的中继日志(relay log);
(3) slave重做中继日志中的事件,将改变反映它自己的数据。
将event的读取和执行分开,避免被执行时拖慢 ,这时是分为了IO线程和SQL线程
2.canal的工作机制
原理相对比较简单:
canal模拟mysql slave的交互协议,伪装自己为mysql slave,向mysql master发送dump协议
mysql master收到dump请求,开始推送binary log给slave(也就是canal)
canal解析binary log对象(原始为byte流)
3.数据库的异步、半同步、全同步
参考文档:https://www.jianshu.com/writer#/notebooks/15190526/notes/30341321
- 有了以上的基础知识,进行分析,当canal在数据库服务器高可用时,假设服务器是主主半同步A,B,由于proxy高可用,存在情况,写入的是A,但canal当时监听的是B
此时,A的binlog需要先到B的中继日志,再回放写到B中,半同步只能保证A的binlog到了某一个从的relaylog,其余无法保证,如果B回放过程出现问题,但没有报警机制,确实可能会出现问题。
三、binlog的查看
3.1binlog的基础知识
binlog主要用于复制和复原,日志由一组二进制日志文件和一个索引文件组成如
HOSTNAME-bin.0000101
HOSTNAME-bin.0000102
HOSTNAME-bin.0000103
HOSTNAME-bin.index
1.每个日志文件包含一个4字节的幻数,后跟一组描述数据修改的事件:
幻数字节是0xfe 0x62 0x69 0x6e = 0xfe'b''i''n'(这是BINLOG_MAGIC 常数log_event.h)
每个事件都包含头字节,后跟数据字节:
标头字节提供有关事件类型,生成时间,服务器等的信息。
数据字节提供特定于事件类型的信息,例如特定的数据修改。
2.第一个事件是描述符事件,它描述文件的格式版本(用于在文件中写入事件的格式)。
3.其余事件根据版本进行解释。
4.最后一个事件是一个日志轮换事件,它指定下一个二进制日志文件名。
5.索引文件是一个文本文件,列出了当前的二进制日志文件。
所有的事件类型可以参照官网:https://dev.mysql.com/doc/internals/en/event-classes-and-types.html
事件意义为https://dev.mysql.com/doc/internals/en/event-meanings.html
canal对此有封装为内部的类型
3.2 binlog的常见命令
1.查看所有binlog日志列表
mysql> show master logs;
2.查看master状态,即最后(最新)一个binlog日志的编号名称,及其最后一个操作事件pos结束点(Position)值
mysql> show master status;
3.刷新log日志,自此刻开始产生一个新编号的binlog日志文件
mysql> flush logs;
注:每当mysqld服务重启时,会自动执行此命令,刷新binlog日志;在mysqldump备份数据时加 -F 选项也会刷新binlog日志;
4.重置(清空)所有binlog日志
5
show variables like 'log_%'; 查看binlog是否开启
show variables like 'binlog_%' 查看format
- binlog的2中模式
Statement-based logging: Events contain SQL statements that produce data changes (inserts, updates, deletes)
Row-based logging: Events describe changes to individual rows
所以当选择row的format时,可能一个sql语句产生很多的记录,如假设对全表某个字段加1
1.查看具体的binlog
SHOW BINLOG EVENTS
[IN 'log_name']
[FROM pos]
[LIMIT [offset,] row_count]
不允许直接不加任何条件查一个mysql文件,很容易oom
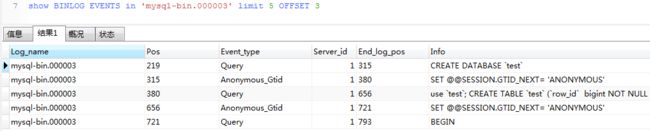
2.登录数据库主机,bin/mysqlbinlog目录下查看
1.指定时间段
mysqlbinlog --start-datetime="2017-01-09 17:50:00" --stop-datetime="2017-01-09 18:00:00" bin.000025
注意时间段的选择,别超过10s,不然根本看不清
2.指定position
mysqlbinlog --start-postion=107 --stop-position=1000 bin.000025