【算法与数据结构 06】先进先出的队列 —— 顺序队列 || 循环队列 || 链式队列 大盘点
写在前面:大家好!我是【AI 菌】,一枚爱弹吉他的程序员。我
热爱AI、热爱分享、热爱开源! 这博客是我对学习的一点总结与思考。如果您也对深度学习、机器视觉、算法、C++、Python感兴趣,可以关注我的动态,我们一起学习,一起进步~
我的博客地址为:【AI 菌】的博客
上一篇:【算法与数据结构 05】“霸道“ 的栈——先进后出
在上一篇中,我们学习了后进先出的数据结构——栈,与之对应的是一种先进先出的数据结构——队列。今天,我们就一起来学习队列,掌握顺序队列、循环队列和链式队列中数据的基本操作。
文章目录
- 1. 什么是队列
- 2. 顺序队列中的数据操作
- (1)增操作
- (2)删操作
- (3)越界问题
- 3. 循环队列的数据操作
- 4. 链式队列的数据操作
- (1)增操作
- (2)删操作
- (3)查操作
1. 什么是队列
简单来说,队列就是一个FIFO(先进先出)的系统。元素只能从队尾插入,且最先插入的元素最先被删除。
就如同在食堂排队就餐,先进入队伍的人先取到餐,且从队首离开,即先进先出;而所有人只能从队尾加入队列,从队首离开,即元素只能从队尾插入,队首删除。

相信说到这里,大家对队列已经有了一个基本的了解!那么,下面我们更深一步挖掘~
从本质上来说,队列也是一种特殊的线性表,与线性表的不同之处体现在对数据的增删操作上。
队列的特点是先进先出:
- 先进,表示队列的数据新增操作只能在末端进行,不允许在队列的中间某个结点后新增数据;
- 先出,队列的数据删除操作只能在始端进行,不允许在队列的中间某个结点后删除数据。
也就是说,队列的增和删的操作只能分别在这个队列的队尾和队头进行。
除此之外,与线性表、栈一样,队列也存在这两种存储方式,即顺序队列和链式队列:
- 顺序队列,依赖数组来实现,其中的数据在内存中也是顺序存储。
- 链式队列,则依赖链表来实现,其中的数据依赖每个结点的指针互联,在内存中并不是顺序存储。链式队列,实际上就是只能尾进头出的线性表的单链表。
对单链表、链式结构还不了解的同学,墙裂建议先看看这篇文章:【算法与数据结构 04】多图讲解——线性表、顺序表、链表
在学习队列的增删查操作之前,我们需要简单了解一下队列中指针与节点的关系,下面以链式队列为例:
如下图所示,一般情况,我们将队头指针front指向链式队列的头结点,队尾指针rear指向终端结点。

当队列为空时,front 和 rear 必须都指向头结点,如下图所示:

实际上,不管是哪种实现方式,一个队列都依赖队头(front)和队尾(rear)两个指针进行唯一确定。
理解了这个之后,我们正式进入:队列对于数据的增删查处理!
2. 顺序队列中的数据操作
队列从队头(front)删除元素,从队尾(rear)插入元素。前面已经谈到过链式列表;那么,对于一个顺序队列的数组来说,也会设置一个 front 指针来指向队头,并设置另一个 rear 指针指向队尾。当我们不断进行插入删除操作时,头尾两个指针都会不断向后移动。
(1)增操作
下面以顺序链表为例,为了实现一个有 k 个元素的顺序存储的队列,我们需要建立一个长度比 k 大的数组,以便把所有的队列元素存储在数组中。队列新增数据的操作,就是利用 rear 指针在队尾新增一个数据元素。过程如下图所示:

因为这个过程不会影响其他数据,所以时间复杂度为 O(1)。
(2)删操作
队列删除数据的操作与栈不同。队列元素出口在队列头部,即下标为 0 的位置。当利用 front 指针删除一个数据时,队列中剩余的元素都需要向前移动一个位置,以保证队列头部下标为 0 的位置不为空,过程如下图所示:

因为剩余的元素都需要向前移动一个位置,此时时间复杂度就变成 O(n) 。
我们看到,front 指针删除数据的操作引发了时间复杂度过高的问题,那么我们该如何解决呢?
(3)越界问题
我们可以通过移动指针的方式来删除数据,这样就不需要移动剩余的数据了。但是,这样的操作,也可能会产生数组越界的问题。接下来,我们来详细讨论一下。
首先,我们来看一个例子:利用顺序队列,持续新增数据和删除数据
1)初始时,定义了长度为 5 的数组,front 指针和 rear 指针相等,且都指向下标为 0 的位置,队列为空队列。
2)当 A、B、C、D 四条数据加入队列后,front 依然指向下标为 0 的位置,而 rear 则指向下标为 4 的位置。过程如下图所示:

3)当 A 出队列时,front 指针指向下标为 1 的位置,rear 保持不变。其后 E 加入队列,front 保持不变,rear 则移动到了数组以外,如下图所示:
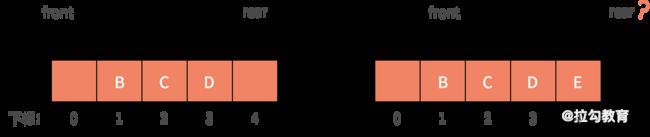
假设这个列队的总个数不超过 5 个,但是目前继续接着入队,因为数组末尾元素已经被占用,再向后加,就会产生我们前面提到的数组越界问题。而实际上,我们列队的下标 0 的地方还是空闲的,这就产生了一种 “假溢出” 的现象。
这种问题在采用顺序存储的队列时,是一定要小心注意的。两个简单粗暴的解决方法就是:
- 不惜消耗 O(n) 的时间复杂度去移动数据;
- 或者开辟足够大的内存空间确保数组不会越界。
3. 循环队列的数据操作
显然,上面的两个方法都不太友好。其实,数组越界问题可以通过队列的一个特殊变种来解决,叫作循环队列。
循环队列进行新增数据元素操作时,首先判断队列是否为满。如果不满,则可以将新元素赋值给队尾,然后让 rear 指针向后移动一个位置。如果已经排到队列最后的位置,则 rear指针重新指向头部。
循环队列进行删除操作时,首先判断队列是否为空,然后将队头元素赋值给返回值,front 指针向后移一个位置。如果已经排到队列最后的位置,就把 front 指针重新指向到头部。这个过程就好像钟表的指针转到了表盘的尾部 12 点的位置后,又重新回到了表盘头部 1 点钟的位置。这样就能在不开辟大量存储空间的前提下,不采用 O(n) 的操作,也能通过移动数据来完成频繁的新增和删除数据。

好啦,我们继续回到前面提到的例子中。对于一般的队列,末尾元素已经被占用,再向后加,就会产生我们前面提到的越界问题。
当我们使用循环队列时,rear 指针就可以重新指向下标为 0 的位置,如下图所示:

如果这时再新增了 F 进入队列,就可以放入在下标为 0 的位置,rear 指针指向下标为 1 的位置。这时的 rear 和 front 指针就会重合,指向下标为 1 的位置,如下图所示:
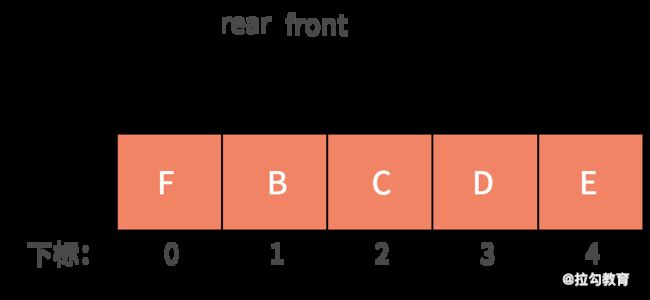
此时,又会产生新的问题,即当队列为空时,有 front 指针和 rear 指针相等。而现在的队列是满的,同样有 front 指针和 rear 指针相等。那么怎样判断队列到底是空还是满呢?常用的方法是,设置一个标志变量 flag 来区别队列是空还是满。
4. 链式队列的数据操作
我们再看一下链式队列的数据操作。链式队列就是一个单链表,同时增加了 front 指针和 rear 指针。链式队列和单链表一样,通常会增加一个头结点,并让 front 指针指向头结点。头结点不存储数据,只是用来辅助标识。
(1)增操作
链式队列进行新增数据操作时,比如要新增数据X,要将拥有数值 X 的新结点 s 赋值给原队尾结点的后继,即 rear.next。然后把当前的 s 设置为队尾结点,指针 rear 指向 s。如下图所示:

(2)删操作
当链式队列进行删除数据操作时,实际删除的是头结点的后继结点。这是因为头结点仅仅用来标识队列,并不存储数据。因此,出队列的操作,就需要找到头结点的后继,这就是要删除的结点。接着,让头结点指向要删除结点的后继。过程如下图所示:
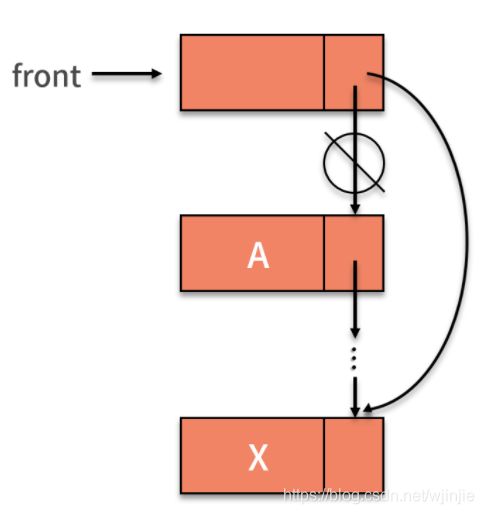
需要注意的是:如果这个链表除去头结点外只剩一个元素,那么删除仅剩的一个元素后,rear 指针就变成野指针了。这时候,需要让 rear 指针指向头结点。也许你前面会对头结点存在的意义产生怀疑,似乎没有它也不影响增删的操作。那么为何队列还特被强调要有头结点呢?
这主要是为了防止删除最后一个有效数据结点后, front 指针和 rear 指针变成野指针,导致队列没有意义了。有了头结点后,哪怕队列为空,头结点依然存在,能让 front 指针和 rear 指针依然有意义。
(3)查操作
对于队列的查找操作,不管是顺序还是链式,队列都没有额外的改变。跟线性表一样,它也需要遍历整个队列来完成基于某些条件的数值查找。因此时间复杂度也是 O(n)。
相关文章推荐
【C++养成计划】队列 —— 快速上手STL queue类(Day13)
【算法与数据结构 04】多图讲解——线性表、顺序表、链表
【算法与数据结构 05】“霸道“ 的栈——先进后出