Pandas的stack和unstack
概述
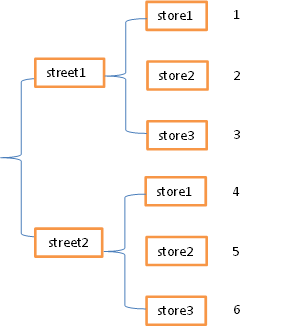
常见的数据的层次化结构有两种,一种是表格(在行、列方向上均有索引)
|
|
store1 |
store2 |
store3 |
| street1 |
1 |
2 |
3 |
| street2 |
4 |
5 |
6 |
一种是“花括号”(只在列方向上有索引)
 “花括号”结构
“花括号”结构
stack: 将数据从”表格结构“变成”花括号结构“,即将其列索引变成行索引。
DataFrame.stack(self, level=-1, dropna=True)
# https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.stack.htmlunstack:数据从”花括号结构“变成”表格结构“,即要将其中一层的行索引变成列索引。如果是多层索引,则以上函数是针对内层索引(这里是store)。利用level可以选择具体哪层索引。
DataFrame.unstack(self, level=-1, fill_value=None)[source]
# https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.unstack.html#pandas.DataFrame.unstack
例子
import numpy as np
import pandas as pd
from pandas import Series,DataFrame
data=DataFrame(np.arange(12).reshape((3,4)),index=pd.Index(['street1','street2','street3']),
columns=pd.Index(['store1','store2','store3','store4']))
print(data)
print('-----------------------------------------\n')
data2=data.stack()
data3=data2.unstack()
print(data2)
print('-----------------------------------------\n')
print(data3)输出:
'''
store1 store2 store3 store4
street1 0 1 2 3
street2 4 5 6 7
street3 8 9 10 11
-----------------------------------------
street1 store1 0
store2 1
store3 2
store4 3
street2 store1 4
store2 5
store3 6
store4 7
street3 store1 8
store2 9
store3 10
store4 11
dtype: int32
-----------------------------------------
store1 store2 store3 store4
street1 0 1 2 3
street2 4 5 6 7
street3 8 9 10 11
'''可以看到:
使用stack函数,将data的列索引['store1','store2','store3’,'store4']转变成行索引(第二层),便得到了一个层次化的Series(data2)
使用unstack函数,将data2的第二层行索引转变成列索引(默认内层索引,level=-1),便又得到了DataFrame(data3)
下面的例子我们利用level选择具体哪层索引
data4=data2.unstack(level=0)
print(data4)
'''
street1 street2 street3
store1 0 4 8
store2 1 5 9
store3 2 6 10
store4 3 7 11
'''我们可以清晰看到,当我们取level=0时,即最外层索引时,unstack把行索引['street1','street2','street3’]变为了列索引。