微盟数据库的涅槃之旅

作者:微盟DBA 余成真
1. 背景介绍
在经历了惨痛的黑天鹅事件以及激烈的数据恢复过程后,作为微盟DBA的我们进行了深刻的反省和自查,作为公司的核心资产,数据库也得到了前所未有的重视。如何保证数据安全以及用户服务的高可用性是我们必须要解决的首要问题。在经过对腾讯数据库深入分析以及业务调研的的基础上,我们选择了腾讯云数据库。通过借助腾讯云 CDB(TencentDB For MySQL)的数据库高可用、备份、恢复、审计、安全等体系,来提升微盟数据库的性能、稳定性与数据安全,满足业务发展的需求,所以我们逐步放弃自建数据库服务,迁移到腾讯云数据库〜
在云上迎接重生的微盟,成为微盟DBA团队核心工作目标。
本文准备就微盟MySQL数据库迁移CDB,从CDB性能上展开较为深入的分析与讨论,通过系统化的测试方案,将黑石限核与CDB各优化状态的数据进行比对,分析上云CDB后会有什么样的使用风险?各并发场景下的性能差异,产生差异的原因,解决过程及解决方案进行了详细的分析。
2. 产品选择
配置:上海四区16C64G(腾讯云数据库CDB)
为更贴近生产环境数据库使用场景,DB团队以微盟线上数据为样本,构建基准测试表及数据进行基准压测;收集线上27套实例的业务SQL进行业务压测。
测试方案:
对照组:黑石不限CPU(56核)32G——QPS值、黑石限16核32G——QPS值
CDB环境:原生CDB | CPU优化 | 网络参数优化 | MySQL参数优化
基准压测:在16|32|64|100|200|400并发情况下各环境QPS性能数据。
业务压测:在16|32|64|100|200|400并发情况下各环境QPS性能数据。
结论:基于线上QPS性能数据,按照(16C64G)CDB产品介绍及压测数据报表,得出优化后CDB能满足公司数据库需求。
3. 方案验证
3.1 压测方法
主要用MySQL官方的压测工具mysqlslap进行压测。例如:
mysqlslap --iterations=100 --create-schema='test' --query="query.sql" --number-of-queries=20000 --delimiter=";" --concurrency=100
表示100并发下运行20000次query.sql, 迭代100次后,输出相关信息如下
Average number of seconds to run all queries: 0.198 seconds
Minimum number of seconds to run all queries: 0.198 seconds
Maximum number of seconds to run all queries: 0.199 seconds
Number of clients running queries: 100
Average number of queries per client: 200
其中平均时间为迭代100次算出的平均时间。QPS = 20000次/平均时间
3.1.1 压测时间线
4月8日发现性能问题1---->4月9日微盟腾讯成立专项组分析并验证问题---->4月10日21时确认问题原因,进行第一版优化---->4月13日抽检29套CDB实例并应用第一排优化配置---->4月14日基准+业务压测---->4月14日23时全面分析生成压测报告发现性能问题2---->4月23日第二版优化---->4月24日第三版优化---->4月25日30个实例DTS迁移任务---->4月26日发现性能问题3---->4月26日第四版优化,CDB上云---->建立长期基准压测任务
3.1.2 主要优化思路
相对于黑石自建的 MySQL 实例,云上的环境较为复杂,这些复杂之处主要包括网络延迟 、虚拟机环境、操作系统版本环境、资源隔离策略、腾讯数据库 CDB (TencentDB for MySQL)内核的稳定性与可靠性、CDB 备份与恢复等,整个上云过程在腾讯云团队的全力配合下,也做到了有惊无险,结果超出预期,排查问题的方法与工具主要包括以下几点:
模拟短连接的mysqlslap & 长链接的sysbench,以及业务定制化的lua脚本,借助sysbench模拟长链接下业务持续压力下数据库性能 & 稳定性表现;
环境对比:主要包括黑石自建环境的对比以及 CDB 实例所在机器的操作系统参数对比,主要包括 NUMA、网络参数设置等
MySQL 参数对比:用于还原自建性能并发现问题
perf 工具:用于分析特殊 SQL 语句在 MySQL 内部的资源消耗情况
pt-pmp 工具:用于排查大并发环境下的性能瓶颈,提升实例性能
腾讯云 CDB 团队内核层的源码分析与修改(腾讯内核大神青林, 阿远)
数据库性能秒级监控工具(orzdba):用于在稳定性压测过程中观察是否存在抖动
3.2 压测中遇到的问题
我们在腾讯CDB和微盟自建的环境下,用相同的方法进行压测对比。在压测过程中主要遇到了如下问题:
3.2.1 NUMA 绑核问题
问题描述
我们在 CDB 环境下进行业务压测的时候,遇到了一个诡异的问题,所有压测语句中有一个 select count(*) ... 的语句执行有性能方面的异常,具体表现是我们黑石自建数据库的性能要比 CDB 环境下的数据库性能高4倍以上,其他语句大都正常,部分的业务 SQL 语句在 CDB 的表现要优于我们在黑石自建的数据库性能;我们在使用 mysqlslap 或者 sysbench 模拟压测时都可以把问题进行重现,基于问题的表现,一时有点懵逼的感觉……
排查过程
首先腾讯云CDB团队从MySQL上查找原因,我们配合他们对MySQL版本是否一致、不同版本的语句执行计划是否一致、MySQL相关参数如 optimizer_switch 等是否一致、并根据他们的要求提供了perf 产生的data信息用于定位不同阶段的CPU消耗,用以定位问题的原因,但当这些因素被一一排除后,他们得出的结论是排除CDB内核的原因,并将突破口放到了网络环境和主机硬件的差异;
其次,压测环境客户端是跑在腾讯的CVM上的,为此他们将压测程序部署在CDB所在主机上,进行本地压测,结果同样出现性能下降的问题,因此排除了网络环境因素的猜疑;
接下来我们对比主机的CPU等硬件配置也没有差异。另外CDB主机开启了NUMA,为了排除NUMA的影响我们建议他们关闭 NUMA 进行测试,但效果依然不好。
CDB 的CPU是通过cgroup进行资源隔离的,在放开了cgroup的限制后压测性能仍然不好。这个时候,我们发现我们自建的 MySQL实例的 CPU资源隔离是通过绑核的方式进行的,和CDB的CPU的隔离策略并不一致。腾讯云CDB的资源隔离是通过cgroup控制CPU时间分片进行实现的,这样有可能导致工作的CPU会分配到不同的Node上,造成跨Node 的CPU访问内存的现象,进而导致性能降低。
将CDB的CPU隔离策略修改和自建一致后,CDB 实例性能比微盟自建要好。同时我们也将自建压测主机放开CPU隔离限制即整机资源不做隔离,发现比绑核限制的性能要差,这也证明了绑核的影响。
问题原因
性能差异主要是由于腾讯云CDB cgroup隔离策略和微盟cgroup隔离策略不一致造成的,业务进程可用核数变多,实际的并发度增大提升了锁开销。锁竞争的增大消耗了更多的cpu时间,相同quota配置下,用于处理实际业务逻辑的cpu时间变短进而降低了QPS。其次,业务绑核不是很合理导致远端内存访问较多,由于外部总线(QPI总线)比内部总线性能差,跨numa内存访问降低了QPS。
解决方案
调整cpu quota设置,修改测试CDB机器CPU隔离策略,按核进行绑定,并将核绑定到同一个Node上。对于消耗大量内存的内存数据库可以尝试使用interleave内存分配策略。
方案效果
CDB性能10倍提升,满足微盟需求,性能调优后的 CDB 实例要优于微盟自建实例〜

3.2.2 网络参数问题
问题描述
使用 mysqlslap 压测某个语句,当并发数提升到200或400时,CDB性能下降,不符合业务预期排查过程
这里只和高并发有关,CDB团队首先想到的是MySQL是否开启了thread pool功能,对于CDB和自建均未开启thread pool功能,而在CDB上打开了thread pool功能后问题仍然存在。而且在本地和远程压测都存在同样问题,这也排除了网络的因素。
有一个细节是CDB团队观察到压测过程中数据库的连接数并不稳定,忽上忽下,就开始怀疑是mysqlslap压测工具的问题。于是CDB团队开始查看mysqlslap源码, 确认mysqlslap用的是否是短连接。然而mysqlslap用的是长连接,并不是短连接。但有一种情况,当mysqlslap执行完一轮(number_of_querys)语句后会新建连接。当压测参数iterations设置较大,number_of_querys较小,并且调大并发数时,每个连接执行的语句相对就少了。也就是说,当并发数增大时,压测过程中的新建连接增加了。为了验证这个问题, CDB团队调大压测参数number_of_querys后,压测性能就上去了。
到这里,问题可以归结为大量建立连接影响了性能。于是CDB团队开始查找TCP相关系统参数的区别,通过修改主机参数tcp_rmem/tcp_wmem/tcp_max_syn_backlog/somaxconn,解决了高并发下的性能下降问题。
问题原因
mysqlslap的实现方式是每次迭代都后重新建立连接,即所有客户端执行完number_of_queries数量的SQL后会重新建连连接,当并发增加时,每个客户端执行的sql相对较少,mysqlslap这种长连接测试方式退化类似于短连接的测试方式,而CDB主机对短连接处理的不是特别好。解决方案
tcp_rmem="4096 873800 4194304" (原"4096 87380 4194304", TCP receive memory buffers)
tcp_wmem = "4096 163840 4194304" (原"4096 16384 4194304", TCP send memory buffers)
tcp_max_syn_backlog=3240000 (原4096, sync queue size)
somaxconn = 2048(原128, accept queue size)
方案效果
通过优化腾讯云CDB主机参数tcp_rmem/tcp_wmem/tcp_max_syn_backlog/somaxconn,解决了通过短连高并发下的性能下降问题。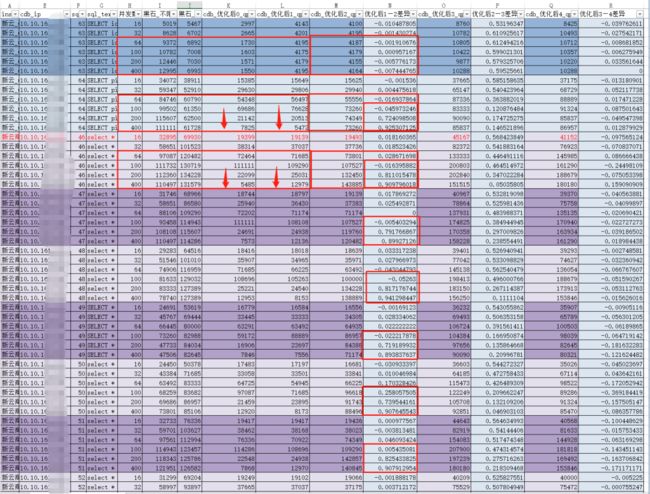
3.2.3 低并发性能问题
问题描述
腾讯云CDB低并下发性能问题不如自建环境, 但在高并发下性能没有差异。
排查过程
首先CDB团队在本地进行了测试发现并没有出现低并发下性能下降的问题,因此基本确定是网络问题引起的。同时CDB团队也用最简单的sql语句"select 1;"进行了测试也验证了是网络的问题。于是开始对比CDB和自建的网络环境差异,发现CDB的网络架构需要三跳才能到后端DB节点(RS),CVM->VPCGW->TGW->RS,相比自建环境要复杂。于是CDB团队手动去掉TGW这一层后,再进行测试发现性能可以上去。从而确定了是CDB网络架构多了一层导致的。
问题原因
CDB的网络架构需要三跳才能到后端DB节点,CVM->VPCGW->TGW->CDB,因此网络链路上耗时会增加,尤其从CVM和CDB各层节点网络亲和性不好的情况下,低并发的性能差距比较明显。而高并发下,单个query的RT对吞吐量影响不大,CDB的性能就满足需要,于是顺便和 CDB 团队了解了一下这个名叫TGW的东东,我们从三个方面解析一下TGW:
1. 为什么要使用TGW ?
通俗的讲,TGW就是DBProxy。和其他云数据库服务一样,CDB也通过加入一层代理来对外屏蔽物理机器,既能带来访问上的安全,又能提供一个统一的访问入口,避免物理DB IP和Port的变化给应用带来的影响。 只不过,TGW是一个操作系统内核态的proxy,在稳定性和性能上相比会更好些,当然这里开发TGW在技术上也是一个挑战。
2. 使用 TGW 存在什么问题?
目前,用户在腾讯云一般是通过CVM+CDB的方式来使用CDB实例。用户一般会先构建一个VPC网络,把购买的CVM放置在某个VPC网络。CDB实例是在特定的underlay网络。打通这两个网络依赖一个VPCGW,这样一个query的访问路径就是CVM->VPCGW->TGW->CDB。对于用户使用而言,多一层网关,会直接导致单次tcp交互时延增加。
3. 如何解决 TGW 的问题?
网络时延的增加在小并发下会引起吞吐量的问题,为了提升用户体验,腾讯CDB团队目前在做一系列的优化,其中的一项工作就是支持移除对TGW的依赖,用户的一条query访问路径从CVM->VPCGW->TGW->CDB缩短为CVM->VPCGW->CDB。减少访问链路中网关的个数,进而减少访问CDB实例的时延问题。
解决方案
腾讯云计划年内去掉TGW,到时我们再测试一下
方案效果
目前性能满足需求
3.2.4 范围查询场景下性能下降
问题描述
腾讯云CDB在范围查询场景下性能下降。
排查过程
这个问题比较诡异,排查过程也比较艰辛。
首先CDB团队也是从MySQL版本、参数、查询计划等基本因素上查看差异,并没有任何收获。腾讯云CDB内核在MySQL原生基础上做了大量的改进和优化,为了排除CDB内核的影响。出现问题的实例是MySQL 5.6的实例,CDB团队用和我们微盟一致的官方MySQL版本在CDB所在主机上进行测试,发现官方MySQL版本并没有问题。
到这里可以基本确定是CDB 5.6内核引入的问题。然而CDB 5.6在MySQL原生基础上有数百个修改提交, 排查起来并不简单。首先CDB团对从可能有影响的几个查询优化的修改提交上排查,然而并没有收获。于是CDB团队开始二分查找的方式进行定位是哪个提交的影响。经过数次的二分编译版本压测验证,最终定位到CDB5.6一个提交,这个提交是引入官方MySQL5.7对只读事务的优化,详见WL#6047W。这个提交约有2000行代码。关键是这个优化表面上看对这的问题场景并没有影响,反而此优化后性能应该提升才对。而且CDB团队也测试过此优化对sysbench只读场景性能确实有提升。经过仔细review这2000行代码后也没有发现异常。
于是,CDB团队由开始了一个宏大的代码定位过程,通过在没有问题的代码上做加法来缩小影响的代码行数,从最初的2000行,到1000行,到800行,到360行,最后到180行。这180行没法再拆分,然后只有一行一行分析这180行代码,表面上看整体逻辑和这180行也没有关系。但是,这180行中有一行逻辑会修改只读事务id为0,之前只读事务和读写事务一样都是自己的id。但这个修改会影响其他部分代码关于innodb_rows_read的计算效率,官方后续修复了这个问题,具体可以参考官方修复代码。但CDB5.6没有及时发现跟进修复这个问题。
在CDB5.6内核上修复此bug后,经过压测验证性能比自建更好。
问题原因
官方MySQL原先innodb_rows_read统计计数有个优化是通过trx_id的递增性来打散优化计数。腾讯云CDB-5.6内核版本优化了只读事务,修改只读事务id为 0 后没有跟进官方后续的 BugFix,导致只读事务统计计数性能变低。
解决方案
这里补充一下,此问题仅在CDB5.6老版本中存在,CDB其他版本没有此问题。同时CDB5.6可以通过升级新版本解决。
方案效果
新版本优化后,腾讯云CDB5.6性能明显比自建更好。
3.2.5 整体性能100并发下QPS略低问题
问题描述
腾讯云CDB在100并发下大部份CDB QPS普遍略低于自建问题。排查过程
在优化两版后,CDB性能已提升几倍,但相较于自建仍有大部份低于自建QPS值,此时CPU绑定、系统层面、CDB内核层面已找不到问题点,MySQL参数成为首要关注目标,比对自建与黑石variables的配置差异,发现不少不同点:innodb_io_capacity_max、innodb_write_io_threads、innodb_open_files、open_files_limit、table_open_cache、table_open_cache_instances等。
问题原因
数据库相关参数应该由业务根据数据库运行情况来进行相应的修改,不同业务场景下数据库性能有着不同的表现,参数不能一概而论,如刷脏,表缓存个数、异步读写线程个数、redo log 文件大小等在不同场景下都需要不同的配置,所以需要对 CDB 的默认参数进行相应的修改,以提升数据库性能,不能着了CDB的道~ (听说他们有个工具叫 CDBTune,还发过 Sigmod,就是为了帮助业务调优数据库性能的东西,期待一下下~)
解决方案
按以上最优化参数配置应用到实例。
方案效果
目前总体性能提升明显,且趋于稳定,部份实例超过自建QPS值。
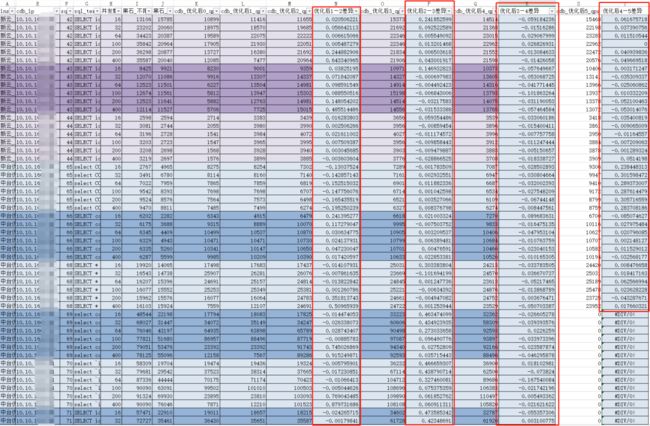
4. 上云过程
4.1 配置CDB
按QPS:根据业务历史性能数据,将不同业务数据库实例配置不同规格CDB
按业务核心度:筛选近30套核心实例,按16C64G标配CDB
4.2 制定迁移计划
按业务类型与各研发负责人逐实例进行迁移时间确认:
是否需压测、CDB配置特殊要求、迁移时间、迁移负责人
4.3 实施迁移
建立DTS迁移任务(提前2日)。
迁移实例在线列表、业务相关负责人、测试方案。
数据一致性检查(三方确认:DTS任务全量校验、TOP30大表的行数校验、业务核心表数据校验)。
切换CDB(自建DB实例只读、域名切换CDB、DTS停止同步、kill自建源DB数据库连接进程、检查自建DB与腾讯云CDB数据库连接情况、有DNS缓存服务重启)。
测试、完成。
5. 最终效果
5.1 性能数据
受限于多种外界因素干扰,本报告以100并发为观察点,结合各优化阶段性QPS值,大部份波动小于25%以内 基准压测报告 业务压测报告(100并发)
业务压测报告(100并发)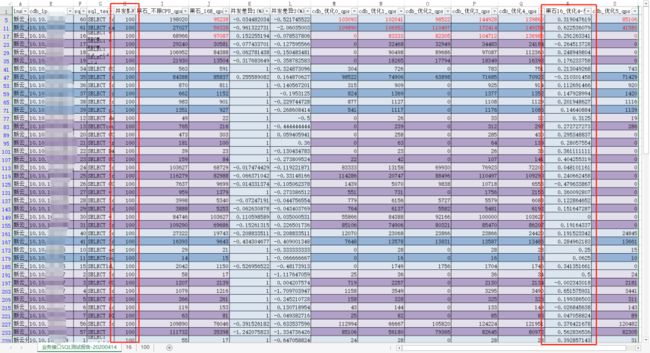 CDB比黑石差(5%):
CDB比黑石差(5%): CDB比黑石强(95%)
CDB比黑石强(95%)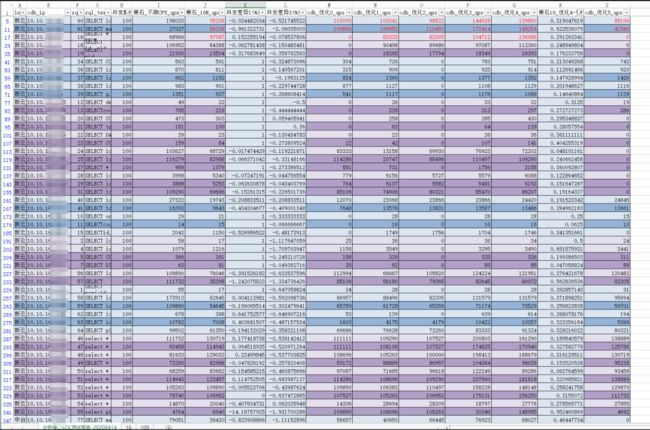
5.2 提升效果
相较原生CDB,基准压测数据方面 QPS提高4-10倍;业务压测部份场景SQL提升2倍以上,总体性能数据提升非常明显。
6. 写在上云后(上云的注意事项)
一定要对现有业务的QPS进行评估,选购合适规格的CDB。
最好进行压测:CDB与在用数据库压测后进行性能对比,明确QPS差异是否在预期之内。
CDB版本与参数做到与在用数据库一致。
使用在线文档让所有相关研发信息共享,及时沟通、及时汇报迁移进度。
迁移前确认CDB账号及权限,DBA自己做一次数据一致性校验。
迁移工作尽量工具化,降低操作时间,减少服务受损时间。
迁移DTS完成后,一定要对实例表进行analyze table,防止系统统计表数据丢失引起的系统下降。
测试必不可少,迁移后观察各日志报错信息,做到问题早发现。