【数据分析】数据加载及探索性数据分析
数据加载
载入数据
数据集下载:https://www.kaggle.com/c/titanic/overview
导入numpy和pandas及载入数据
import numpy as np
import pandas as pd
df = pd.read_csv('train.csv') # 使用相对路径载入数据
df.head(3) # 展示前三行
df = pd.read_csv('C:\Users\nero\Jupyter notebook\hands-on-data-analysis\第一单元项目集合\train.csv') # 使用绝对路径载入数据
df.head(3)
每1000行为一个数据模块,逐块读取
chunker = pd.read_csv('train.csv', chunksize=1000)
数据集太大时,需要逐块读取数据以加快速度。
将表头改成中文
df = pd.read_csv('train.csv', names=['乘客ID','是否幸存','仓位等级','姓名','性别','年龄','兄弟姐妹个数','父母子女个数','船票信息','票价','客舱','登船港口'],index_col='乘客ID',header=0)
df.head()
初步观察
查看数据的基本信息
df.info()
观察表格前10行的数据和后15行的数据
df.head(10)
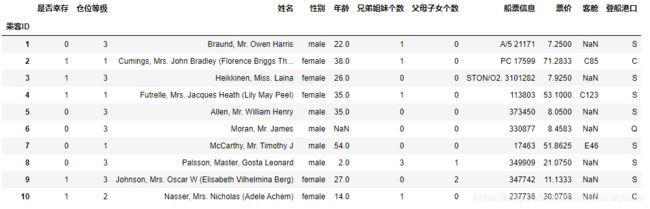
df.tail(15)

判断数据是否为空,为空的地方返回True,其余地方返回False
df.isnull().head()

将你加载并做出改变的数据,在工作目录下保存为一个新文件train_chinese.csv
df.to_csv('train_chinese.csv')
Pandas基础
数据类型Series
Series (Series)是能够保存任何类型的数据(整数,字符串,浮点数,Python对象等)的一维标记数组。轴标签统称为索引。
- data 参数
- index 索引 索引值必须是唯一的和散列的,与数据的长度相同。 默认np.arange(n)如果没有索引被传递。
- dtype 输出的数据类型 如果没有,将推断数据类型
- copy 复制数据 默认为false
数组创建:
data = ['a','b','c','d','e']
res= pd.Series(data,index=[i for i in range(1,6)],dtype=str)
print(res)
1 a
2 b
3 c
4 d
5 e
dtype: object
字典创建:
data = {"a":1.,"b":2,"c":3,"d":4}
res = pd.Series(data,index=["d","c","b","a"])
print(res) # 字典的键用于构建索引
d 4.0
c 3.0
b 2.0
a 1.0
dtype: float64
常量创建:
# 如果数据是常量值,则必须提供索引。将重复该值以匹配索引的长度。
res = pd.Series(5,index=[1,2,3,4,5])
print(res)
1 5
2 5
3 5
4 5
5 5
dtype: int64
数据查询
切片:
data = [1,2,3,4,5]
res = pd.Series(data,index=["a","b","c","d","e"])
print(res[0:3],"---") # 这里跟python的切片一样
print(res[3],"---")
print(res[-3:],"---")
a 1
b 2
c 3
dtype: int64 ---
4 ---
c 3
d 4
e 5
dtype: int64 ---
使用索引检索数据:
data = [1,2,3,4,5]
res = pd.Series(data,index=["a","b","c","d","e"])
print(res["a"])
# 检索多个值 标签用中括号包裹
print(res[["a","b"]]) # 如果用没有的标签检索则会抛出异常KeyError: 'f'
1
a 1
b 2
dtype: int64
data = [1,2,3,4,5]
res = pd.Series(data)
res[[2,4]]
2 3
4 5
dtype: int64
使用head()/tail()查看前几个或后几个:
data = [1,2,3,4,5]
res = pd.Series(data,index=["a","b","c","d","e"])
res.head(3) # 查看前三个
res.tail(2) # 查看后两个
series元素进行去重:
s = pd.Series(data=[1,1,2,2,3,4,5,6,6,6,7,6,6,7,8])
s.unique()
array([1, 2, 3, 4, 5, 6, 7, 8], dtype=int64)
两个series元素相加
- 在运算中自动对齐不同索引的数据
- 如果索引不对应,则补NaN
# 当索引没有对应的值时,可能出现缺失数据显示NaN(not a number)的情况
s1 = pd.Series(data=[1,2,3,4,5],index=["a","b","c","d","e"])
s2 = pd.Series(data=[1,2,3,4,5],index=["a","b","c","d","f"])
s = s1 + s2
s
a 2.0
b 4.0
c 6.0
d 8.0
e NaN
f NaN
dtype: float64
监测缺失的数据:
isnull() :缺失的数据返回的布尔值为True
notnull() : 缺失的数据返回的布尔值为False
s1 = pd.Series(data=[1,2,3,4,5],index=["a","b","c","d","e"])
s2 = pd.Series(data=[1,2,3,4,5],index=["a","b","c","d","f"])
s = s1 + s2
s.isnull() # 缺失的数据返回的布尔值为True
a False
b False
c False
d False
e True
f True
dtype: bool
s1 = pd.Series(data=[1,2,3,4,5],index=["a","b","c","d","e"])
s2 = pd.Series(data=[1,2,3,4,5],index=["a","b","c","d","f"])
s = s1 + s2
s.notnull() # 缺失的数据返回的布尔值为False
a True
b True
c True
d True
e False
f False
dtype: bool
如果将布尔值作为Serrise的索引,则只保留True对应的元素值:
s[[True,True,False,False,True,True]]
a 2.0
b 4.0
e NaN
f NaN
dtype: float64
根据上面的特性,可以取出所有空的数据和所有不为空的数据:
s[s.isnull()] # 取所有空值
e NaN
f NaN
dtype: float64
s[s.notnull()] # 取出不为空的数据
a 2.0
b 4.0
c 6.0
d 8.0
dtype: float64
s.index # 取出索引
Index(['a', 'b', 'c', 'd', 'e', 'f'], dtype='object')
数据类型DataFrame
创建
data = np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]])
c = ['a', 'b', 'c']
r = ['A', 'B', 'C']
df = pd.DataFrame(data=data, columns=c, index=r)
排序
按列、行名排序:
# 行名排序 降序
df.sort_index(axis=0, ascending=False)
# 列名排序 降序
df.sort_index(axis=0, ascending=False)
按值排序:
df["a"].sort_values(ascending = False) # 拿出来排序
df.sort_values( ['a', 'b', 'c']) # df内排序
索引
位置索引:
df.iloc[2] # 选择第二行所有数据, 是Series类型
df.iloc[[2]] # 选择第二行所有数据, 是DataFrame类型
df.iloc[:, 2] # 选择第二列所有数据, 是Series类型
df.iloc[:, [2]] # 选择第二列所有数据, 是DataFrame类型
df.iloc[:, 0:2] # 选择0到2列所有数据
df.iloc[[2,3], 0:2] # 选择2和3行, 0到2列所有数据
df.iat[1, 1] # 根据位置快速取出数据, 获取单个数据推荐这种方法
自定义索引:
df.loc['top'] # 选择指定行数据, 是Series类型
df.loc[['top']] # 选择指定行数据, 是DataFrame类型
df.loc[:, 'xm'] # 选择指定列数据, 是Series类型(不推荐)
df.loc[:, ['xm']] # 选择指定列数据, 是DataFrame类型(不推荐)
df.loc[:, ['bj','xm']] # 选择多列数据(不推荐)
df.loc[:, 'bj':'xb'] # 选择多列之间所有数据, 列切片只能用这种方法
df.loc[['top','count'], 'bj':'xb'] # 选择指定行, 指定列数据
df.at['top', 'xm'] # 根据自定义索引快速取出数据, 获取单个数据推荐这种方法
布尔索引:
# 选取所有出生日期大于等于1998年的数据, 这里是字符串比较
df[df['csrq']>='1998']
# 选取所有出生日期大于等于1997年小于1999年的数据
df[(df['csrq']>='1997')&(data['csrq']<'1999')]
# 选取所有出生日期大于等于1997年小于1999年的数据
df[df['csrq'].between('1997', '1999')]
# 选取所有出生日期大于等于1997年或者姓名为张三的数据
df[(df['csrq']>='1997')|(data['xm']=='张三')]
# 另一种选取方式(不推荐, 实测效率比上面低)
df[df.csrq>='1998']
# 选择字段值为指定内容的数据
df[df['xm'].isin(['张三','李四'])]
插入与删除
# 假设cj列本来不存在, 这样会在列尾添加新的一列cj, 值为s(Series对象), 原地
df['cj'] = s
# 在第1列位置插入一列dz(地址), 值为s, 原地
df.insert(0, 'dz', s)
# 在df中添加内容为df2(必须是DataFrame对象)的新列(添加列), 非原地
df.join(df2)
# 将df2中的行添加到df的尾部(添加行), 非原地
df.append(df2)
# 删除单列, 并返回删除的列, 原地
df.pop('xm')
# 删除指定行, 非原地
df.drop(1)
# 删除指定列, axis=1指第2维, axis默认0, 非原地
df.drop(['xm', 'xh'], axis=1)
# 删除指定列,原地
df.drop([df.columns[[0,1]]],axis=1,inplace=True)
# 删除指定列
del df['a']
DataFrame 重要方法与属性
'''重要属性'''
df.values # 查看所有元素的value
df.dtypes # 查看所有元素的类型
df.index # 查看所有行名
df.index = ['总数', '不同', '最多', '频率'] # 重命名行名
df.columns # 查看所有列名
df.columns = ['班级', '姓名', '性别', '出生日期'] # 重命名列名
df.T # 转置后的df, 非原地
'''查看数据'''
df.head(n) # 查看df前n条数据, 默认5条
df.tail(n) # 查看df后n条数据, 默认5条
df.shape() # 查看行数和列数
df.info() # 查看索引, 数据类型和内存信息
'''数据统计'''
df.describe() # 查看数据值列的汇总统计, 是DataFrame类型
df.count() # 返回每一列中的非空值的个数
df.sum() # 返回每一列的和, 无法计算返回空, 下同
df.sum(numeric_only=True) # numeric_only=True代表只计算数字型元素, 下同
df.max() # 返回每一列的最大值
df.min() # 返回每一列的最小值
df.argmax() # 返回最大值所在的自动索引位置
df.argmin() # 返回最小值所在的自动索引位置
df.idxmax() # 返回最大值所在的自定义索引位置
df.idxmin() # 返回最小值所在的自定义索引位置
df.mean() # 返回每一列的均值
df.median() # 返回每一列的中位数
df.var() # 返回每一列的方差
df.std() # 返回每一列的标准差
df.isnull() # 检查df中空值, NaN为True, 否则False, 返回一个布尔数组
df.notnull() # 检查df中空值, 非NaN为True, 否则False, 返回一个布尔数组
df.reset_index(drop=True) # 重置索引
转换成 Numpy
df.values
np.array(df)