李宏毅机器学习2016 第二十一讲 隐马尔可夫模型和条件随机场
视频链接:李宏毅机器学习(2016)_演讲•公开课_科技_bilibili_哔哩哔哩
课程资源:Hung-yi Lee
课程相关PPT已经打包命名好了:链接:https://pan.baidu.com/s/1c3Jyh6S 密码:77u5
我的第二十讲笔记:李宏毅机器学习2016 第二十讲 结构化线性模型
Hidden Markov Model & Conditional Random Field
本章主要通过举例词性标注的例子讲解了隐马尔可夫模型和条件随机场。
1.词性标注(part-of-speech tagging,POS tagging)
对应输入是序列输出也是序列的结构化学习问题,词性标注属于其中。词性标注指的是在一串的字词中标注每一个所属的词性。

在上图中,第一个“saw”的词性是动词,第二个“saw”的词性是名词。
2.隐马尔可夫模型(Hidden Markov Model,HMM)
隐马尔可夫模型有两步:第一步是基于语法生成一个合法的词性序列(generate a POS sequence based on the grammar);第二部是基于字典生成一个句子序列在第一步生成的词性序列的基础上(gengerate a sentence based on the POS sequence;based on a dictionary)。
例如第一步,基于合法的语法,可以计算出生成一个词性序列的概率。
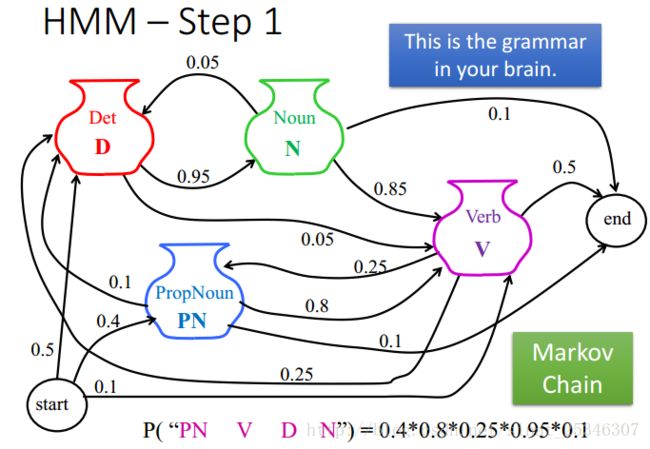
第二步,基于字典,可计算出在第一步生成的合法词性序列的条件下生成对应句子的概率。
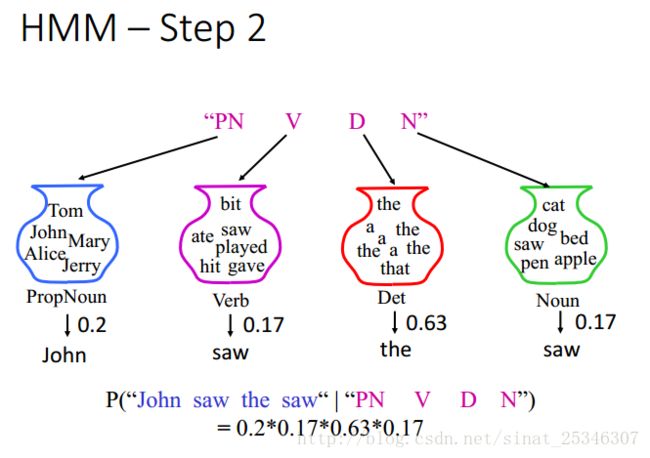
这两步之后就可计算出x和y,对应的词性和句子一起出现的概率。

将其一般化,可将第一步的概率称为转移概率(transition probability),第二步的概率称为输出概率(emission probability)。其概率值都可以通过训练数据得到。

计算概率值可以通过在训练数据中出现的次数计算得到。

词性标注的任务是给定x(句子序列),找到y(词性序列)。

需要遍历所有的y来找到能够使得P(x,y)最大的y,可以使用维特比算法(Viterbi Algorithm)减少计算的复杂度。

总结下HMM,至此其三个问题就得到了解决。

HMM的缺点(Drawback):
1、HMM只依赖于每一个状态和它对应的观察对象:
计算转移概率和输出概率是分开计算的,认为其是相互独立的。然而序列标注问题不仅和单个词相关,而且和观察序列的长度,单词的上下文,等等相关。
2、目标函数和预测目标函数不匹配:
HMM学到的是状态和观察序列的联合分布P(Y,X),而预测问题中,我们需要的是条件概率P(Y|X)。
3.条件随机场(Conditional Random Field,CRF)
条件随机场对隐马尔可夫模型进行了改进。CRF假设概率P(x,y)正比于一个函数。

下面介绍下公式由来。
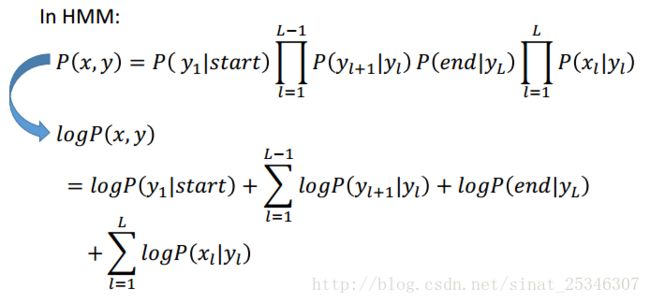


所以可得:

可以认为概率值是正比于一个权值和特征向量的内积。
特征向量由两部分组成,一个部分是标签和词的关系(relations between tags and words);

第二部分是标签之间的关系(relations between tags);

CRF的训练准则是找到满足的权值向能够在最大化目标函数。能够最大化我们所观察到的同时,最小化我们没有观察到的。

可以使用梯度上升(gradient ascent)方法来求解。
在求得权值向量和特征向量后,同样可以和隐马尔可夫模型一样使用维特比算法找到y。

总结下CRF,至此其三个问题就得到了解决。

4.对比(comparsion)
与HMM比较。CRF没有HMM那样严格的独立性假设条件,因而可以容纳任意的上下文信息。CRF模型解决了标注偏置问题,去除了HMM中两个不合理的假设,当然,模型相应得也变复杂了。因此训练代价大、复杂度高。

5.总结
本章重点以词性标注(part-of-speech tagging,POS tagging)为例,讲述了隐马尔可夫模型(Hidden Markov Model,HMM)和条件随机场(Conditional Random Field,CRF),并对二者进行了对比(comparsion)。