Datawhale组队学习机器学习算法第一章
第一部分:Demo实践
Step1:函数库导入
## 基础函数库
import numpy as np
## 导入画图库
import matplotlib.pyplot as plt
import seaborn as sns
## 导入逻辑回归模型函数
from sklearn.linear_model import LogisticRegression
##Demo演示LogisticRegression分类
## 构造数据集
x_fearures = np.array([[-1, -2], [-2, -1], [-3, -2], [1, 3], [2, 1], [3, 2]])
y_label = np.array([0, 0, 0, 1, 1, 1])
## 调用逻辑回归模型
lr_clf = LogisticRegression()
## 用逻辑回归模型拟合构造的数据集
lr_clf = lr_clf.fit(x_fearures, y_label) #其拟合方程为 y=w0+w1*x1+w2*x2
x_fearures #(6,2)的矩阵
array([[-1, -2],
[-2, -1],
[-3, -2],
[ 1, 3],
[ 2, 1],
[ 3, 2]])
y_label #一维数列,代表标记值
array([0, 0, 0, 1, 1, 1])
##查看其对应模型的w
print('the weight of Logistic Regression:',lr_clf.coef_)
##查看其对应模型的w0
print('the intercept(w0) of Logistic Regression:',lr_clf.intercept_)
##the weight of Logistic Regression:[[0.73462087 0.6947908]]
##the intercept(w0) of Logistic Regression:[-0.03643213]
the weight of Logistic Regression: [[0.73455784 0.69539712]]
the intercept(w0) of Logistic Regression: [-0.13139986]
## 可视化构造的数据样本点
plt.figure()
plt.scatter(x_fearures[:,0],x_fearures[:,1], c=y_label, s=50, cmap='viridis')
plt.title('Dataset')
plt.show()

# 可视化决策边界
plt.figure()
plt.scatter(x_fearures[:,0],x_fearures[:,1], c=y_label, s=50, cmap='viridis')
plt.title('Dataset')
nx, ny = 200, 100
x_min, x_max = plt.xlim()
y_min, y_max = plt.ylim()
x_grid, y_grid = np.meshgrid(np.linspace(x_min, x_max, nx),np.linspace(y_min, y_max, ny))
z_proba = lr_clf.predict_proba(np.c_[x_grid.ravel(), y_grid.ravel()])
z_proba = z_proba[:, 1].reshape(x_grid.shape)
plt.contour(x_grid, y_grid, z_proba, [0.5], linewidths=2., colors='blue')
plt.show()

### 可视化预测新样本
plt.figure()
## new point 1
x_fearures_new1 = np.array([[0, -1]])
plt.scatter(x_fearures_new1[:,0],x_fearures_new1[:,1], s=50, cmap='viridis')
plt.annotate(s='New point 1',xy=(0,-1),xytext=(-2,0),color='blue',arrowprops=dict(arrowstyle='-|>',connectionstyle='arc3',color='red'))
## new point 2
x_fearures_new2 = np.array([[1, 2]])
plt.scatter(x_fearures_new2[:,0],x_fearures_new2[:,1], s=50, cmap='viridis')
plt.annotate(s='New point 2',xy=(1,2),xytext=(-1.5,2.5),color='red',arrowprops=dict(arrowstyle='-|>',connectionstyle='arc3',color='red'))
## 训练样本
plt.scatter(x_fearures[:,0],x_fearures[:,1], c=y_label, s=50, cmap='viridis')
plt.title('Dataset')
# 可视化决策边界
plt.contour(x_grid, y_grid, z_proba, [0.5], linewidths=2., colors='blue')
plt.show()

##在训练集和测试集上分布利用训练好的模型进行预测
y_label_new1_predict=lr_clf.predict(x_fearures_new1)
y_label_new2_predict=lr_clf.predict(x_fearures_new2)
print('The New point 1 predict class:\n',y_label_new1_predict)
print('The New point 2 predict class:\n',y_label_new2_predict)
##由于逻辑回归模型是概率预测模型(前文介绍的p = p(y=1|x,\theta)),所有我们可以利用predict_proba函数预测其概率
y_label_new1_predict_proba=lr_clf.predict_proba(x_fearures_new1)
y_label_new2_predict_proba=lr_clf.predict_proba(x_fearures_new2)
print('The New point 1 predict Probability of each class:\n',y_label_new1_predict_proba)
print('The New point 2 predict Probability of each class:\n',y_label_new2_predict_proba)
##TheNewpoint1predictclass:
##[0]
##TheNewpoint2predictclass:
##[1]
##TheNewpoint1predictProbabilityofeachclass:
##[[0.695677240.30432276]]
##TheNewpoint2predictProbabilityofeachclass:
##[[0.119839360.88016064]]
The New point 1 predict class:
[0]
The New point 2 predict class:
[1]
The New point 1 predict Probability of each class:
[[0.69567724 0.30432276]]
The New point 2 predict Probability of each class:
[[0.11983936 0.88016064]]
第二部分:鸢尾花数据集逻辑回归实践
本次我们选择鸢花数据(iris)进行方法的尝试训练,该数据集一共包含5个变量,其中4个特征变量,1个目标分类变量。共有150个样本,目标变量为 花的类别 其都属于鸢尾属下的三个亚属,分别是山鸢尾 (Iris-setosa),变色鸢尾(Iris-versicolor)和维吉尼亚鸢尾(Iris-virginica)。包含的三种鸢尾花的四个特征,分别是花萼长度(cm)、花萼宽度(cm)、花瓣长度(cm)、花瓣宽度(cm),这些形态特征在过去被用来识别物种。
| 变量 | 描述 |
|---|---|
| sepal length | 花萼长度(cm) |
| sepal width | 花萼宽度(cm) |
| petal length | 花瓣长度(cm) |
| petal width | 花瓣宽度(cm) |
| target | 鸢尾的三个亚属类别,‘setosa’(0), ‘versicolor’(1), ‘virginica’(2) |
Step1:函数库导入
import pandas as pd
Step2:数据读取/载入
利用sklearn中自带的iris数据作为数据载入,并利用Pandas转化为DataFrame格式
from sklearn.datasets import load_iris
data = load_iris() #得到数据特征
iris_target = data.target #得到数据对应的标签
iris_features = pd.DataFrame(data=data.data, columns=data.feature_names)
Step3:数据信息简单查看
iris_features
| sepal length (cm) | sepal width (cm) | petal length (cm) | petal width (cm) | |
|---|---|---|---|---|
| 0 | 5.1 | 3.5 | 1.4 | 0.2 |
| 1 | 4.9 | 3.0 | 1.4 | 0.2 |
| 2 | 4.7 | 3.2 | 1.3 | 0.2 |
| 3 | 4.6 | 3.1 | 1.5 | 0.2 |
| 4 | 5.0 | 3.6 | 1.4 | 0.2 |
| ... | ... | ... | ... | ... |
| 145 | 6.7 | 3.0 | 5.2 | 2.3 |
| 146 | 6.3 | 2.5 | 5.0 | 1.9 |
| 147 | 6.5 | 3.0 | 5.2 | 2.0 |
| 148 | 6.2 | 3.4 | 5.4 | 2.3 |
| 149 | 5.9 | 3.0 | 5.1 | 1.8 |
150 rows × 4 columns
iris_target #其对应的类别标签为,其中0,1,2分别代表'setosa','versicolor','virginica'三种不同花的类别
array([0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2])
iris_features.info()
RangeIndex: 150 entries, 0 to 149
Data columns (total 4 columns):
sepal length (cm) 150 non-null float64
sepal width (cm) 150 non-null float64
petal length (cm) 150 non-null float64
petal width (cm) 150 non-null float64
dtypes: float64(4)
memory usage: 4.8 KB
iris_features.describe()
| sepal length (cm) | sepal width (cm) | petal length (cm) | petal width (cm) | |
|---|---|---|---|---|
| count | 150.000000 | 150.000000 | 150.000000 | 150.000000 |
| mean | 5.843333 | 3.057333 | 3.758000 | 1.199333 |
| std | 0.828066 | 0.435866 | 1.765298 | 0.762238 |
| min | 4.300000 | 2.000000 | 1.000000 | 0.100000 |
| 25% | 5.100000 | 2.800000 | 1.600000 | 0.300000 |
| 50% | 5.800000 | 3.000000 | 4.350000 | 1.300000 |
| 75% | 6.400000 | 3.300000 | 5.100000 | 1.800000 |
| max | 7.900000 | 4.400000 | 6.900000 | 2.500000 |
iris_features.isnull() #检查缺失值
| sepal length (cm) | sepal width (cm) | petal length (cm) | petal width (cm) | |
|---|---|---|---|---|
| 0 | False | False | False | False |
| 1 | False | False | False | False |
| 2 | False | False | False | False |
| 3 | False | False | False | False |
| 4 | False | False | False | False |
| ... | ... | ... | ... | ... |
| 145 | False | False | False | False |
| 146 | False | False | False | False |
| 147 | False | False | False | False |
| 148 | False | False | False | False |
| 149 | False | False | False | False |
150 rows × 4 columns
Step4:可视化描述
## 合并标签和特征信息
iris_all = iris_features.copy() ##进行浅拷贝,防止对于原始数据的修改
iris_all['target'] = iris_target
iris_all
| sepal length (cm) | sepal width (cm) | petal length (cm) | petal width (cm) | target | |
|---|---|---|---|---|---|
| 0 | 5.1 | 3.5 | 1.4 | 0.2 | 0 |
| 1 | 4.9 | 3.0 | 1.4 | 0.2 | 0 |
| 2 | 4.7 | 3.2 | 1.3 | 0.2 | 0 |
| 3 | 4.6 | 3.1 | 1.5 | 0.2 | 0 |
| 4 | 5.0 | 3.6 | 1.4 | 0.2 | 0 |
| ... | ... | ... | ... | ... | ... |
| 145 | 6.7 | 3.0 | 5.2 | 2.3 | 2 |
| 146 | 6.3 | 2.5 | 5.0 | 1.9 | 2 |
| 147 | 6.5 | 3.0 | 5.2 | 2.0 | 2 |
| 148 | 6.2 | 3.4 | 5.4 | 2.3 | 2 |
| 149 | 5.9 | 3.0 | 5.1 | 1.8 | 2 |
150 rows × 5 columns
## 特征与标签组合的散点可视化
sns.pairplot(data=iris_all, #载入数据
diag_kind='hist', #选择直方图
hue= 'target')
plt.show()

上图可以发现,在2D情况下不同的特征组合对于不同类别的花的散点分布,以及大概的区分能力。
for col in iris_features.columns:
sns.boxplot(x='target', y=col, saturation=0.5, #为每一列绘制基于target的箱线图
palette='pastel', data=iris_all)
plt.title(col)
plt.show()

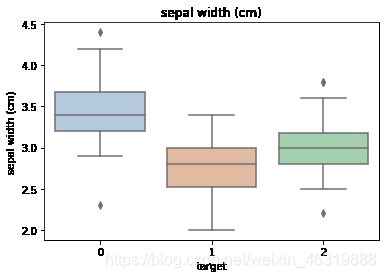
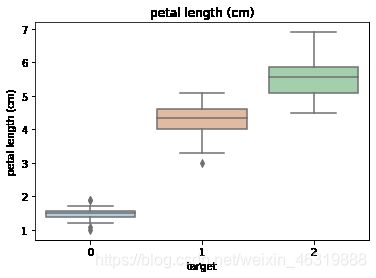

# 选取其前三个特征绘制三维散点图
from mpl_toolkits.mplot3d import Axes3D
fig = plt.figure(figsize=(10,8))
ax = fig.add_subplot(111, projection='3d')
iris_all_class0 = iris_all[iris_all['target']==0].values
iris_all_class1 = iris_all[iris_all['target']==1].values
iris_all_class2 = iris_all[iris_all['target']==2].values
# 'setosa'(0), 'versicolor'(1), 'virginica'(2)
ax.scatter(iris_all_class0[:,0], iris_all_class0[:,1], iris_all_class0[:,2],label='setosa')
ax.scatter(iris_all_class1[:,0], iris_all_class1[:,1], iris_all_class1[:,2],label='versicolor')
ax.scatter(iris_all_class2[:,0], iris_all_class2[:,1], iris_all_class2[:,2],label='virginica')
plt.legend()
plt.show()
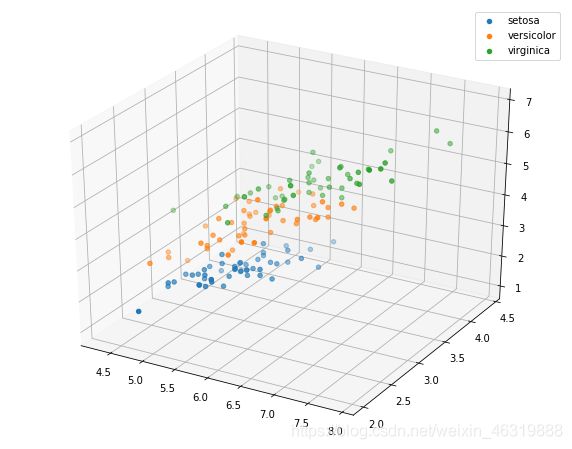
Step5:利用逻辑回归模型在二分类上进行训练和预测
##为了正确评估模型性能,将数据划分为训练集和测试集,并在训练集上训练模型,在测试集上验证模型性能。
from sklearn.model_selection import train_test_split
##选择其类别为0和1的样本(不包括类别为2的样本)
iris_features_part=iris_features.iloc[:100]
iris_target_part=iris_target[:100]
##测试集大小为20%,80%/20%分
x_train,x_test,y_train,y_test=train_test_split(iris_features_part, #训练数据集
iris_target_part, #测试数据集
test_size=0.2, #分割比例
random_state=2020) #随机
##从sklearn中导入逻辑回归模型
from sklearn.linear_model import LogisticRegression
##定义逻辑回归模型
clf=LogisticRegression(random_state=0,solver='lbfgs')
##在训练集上训练逻辑回归模型
clf.fit(x_train,y_train)
LogisticRegression(C=1.0, class_weight=None, dual=False, fit_intercept=True,
intercept_scaling=1, l1_ratio=None, max_iter=100,
multi_class='auto', n_jobs=None, penalty='l2',
random_state=0, solver='lbfgs', tol=0.0001, verbose=0,
warm_start=False)
##查看其对应的w
print('the weight of Logistic Regression:',clf.coef_)
##查看其对应的w0
print('the intercept(w0) of Logistic Regression:',clf.intercept_)
the weight of Logistic Regression: [[ 0.45181973 -0.81743611 2.14470304 0.89838607]]
the intercept(w0) of Logistic Regression: [-6.53367714]
##在训练集和测试集上分布利用训练好的模型进行预测
train_predict=clf.predict(x_train)
test_predict=clf.predict(x_test)
from sklearn import metrics
##利用accuracy(准确度)【预测正确的样本数目占总预测样本数目的比例】评估模型效果
print('The accuracy of the Logistic Regression is:',metrics.accuracy_score(y_train,train_predict))
print('The accuracy of the Logistic Regression is:',metrics.accuracy_score(y_test,test_predict))
##查看混淆矩阵(预测值和真实值的各类情况统计矩阵)
confusion_matrix_result=metrics.confusion_matrix(test_predict,y_test)
print('The confusion matrix result:\n',confusion_matrix_result)
##利用热力图对于结果进行可视化
plt.figure(figsize=(8,6))
sns.heatmap(confusion_matrix_result,annot=True,cmap='Blues')
plt.xlabel('Predictedlabels')
plt.ylabel('Truelabels')
plt.show()
##The accuracy of the Logistic Regressionis:1.0
##The accuracy of the Logistic Regressionis:1.0
##The confusion matrix result:
##[[9 0]
##[0 11]]
The accuracy of the Logistic Regression is: 1.0
The accuracy of the Logistic Regression is: 1.0
The confusion matrix result:
[[ 9 0]
[ 0 11]]

Step6:利用逻辑回归模型 在三分类(多分类)上进行训练和预测
##测试集大小为20%,80%/20%分
x_train,x_test,y_train,y_test=train_test_split(iris_features,iris_target,test_size=0.2,random_state=2020)
##定义逻辑回归模型
clf=LogisticRegression(random_state=0,solver='lbfgs')
##在训练集上训练逻辑回归模型
clf.fit(x_train,y_train)
LogisticRegression(C=1.0, class_weight=None, dual=False, fit_intercept=True,
intercept_scaling=1, l1_ratio=None, max_iter=100,
multi_class='auto', n_jobs=None, penalty='l2',
random_state=0, solver='lbfgs', tol=0.0001, verbose=0,
warm_start=False)
##查看其对应的w
print('the weight of Logistic Regression:\n',clf.coef_)
##查看其对应的w0
print('the intercept(w0) of Logistic Regression:\n',clf.intercept_)
##由于这个是3分类,所有我们这里得到了三个逻辑回归模型的参数,其三个逻辑回归组合起来即可实现三分类
the weight of Logistic Regression:
[[-0.45928925 0.83069887 -2.26606531 -0.99743981]
[ 0.33117319 -0.72863424 -0.06841147 -0.9871103 ]
[ 0.12811606 -0.10206464 2.33447678 1.98455011]]
the intercept(w0) of Logistic Regression:
[ 9.4388067 3.93047364 -13.36928034]
##在训练集和测试集上分布利用训练好的模型进行预测
train_predict=clf.predict(x_train)
test_predict=clf.predict(x_test)
##由于逻辑回归模型是概率预测模型(前文介绍的p=p(y=1|x,\theta)),所有我们可以利用predict_proba函数预测其概率
train_predict_proba=clf.predict_proba(x_train)
test_predict_proba=clf.predict_proba(x_test)
print('The test predict Probability of each class:\n',test_predict_proba)
##其中第一列代表预测为0类的概率,第二列代表预测为1类的概率,第三列代表预测为2类的概率。
##利用accuracy(准确度)【预测正确的样本数目占总预测样本数目的比例】评估模型效果
print('The accuracy of the Logistic Regression is:',metrics.accuracy_score(y_train,train_predict))
print('The accuracy of the Logistic Regression is:',metrics.accuracy_score(y_test,test_predict))
The test predict Probability of each class:
[[1.03461737e-05 2.33279477e-02 9.76661706e-01]
[9.69926591e-01 3.00732874e-02 1.21677000e-07]
[2.09992549e-02 8.69156616e-01 1.09844129e-01]
[3.61934872e-03 7.91979966e-01 2.04400686e-01]
[7.90943209e-03 8.00605299e-01 1.91485269e-01]
[7.30034956e-04 6.60508053e-01 3.38761912e-01]
[1.68614211e-04 1.86322045e-01 8.13509341e-01]
[1.06915331e-01 8.90815532e-01 2.26913671e-03]
[9.46928071e-01 5.30707288e-02 1.20016060e-06]
[9.62346385e-01 3.76532228e-02 3.91897297e-07]
[1.19533386e-04 1.38823469e-01 8.61056998e-01]
[8.78881880e-03 6.97207359e-01 2.94003822e-01]
[9.73938143e-01 2.60617342e-02 1.22613839e-07]
[1.78434056e-03 4.79518177e-01 5.18697483e-01]
[5.56924345e-04 2.46776840e-01 7.52666235e-01]
[9.83549842e-01 1.64500666e-02 9.13617272e-08]
[1.65201476e-02 9.54672748e-01 2.88071041e-02]
[8.99853722e-03 7.82707575e-01 2.08293888e-01]
[2.98015029e-05 5.45900069e-02 9.45380192e-01]
[9.35695863e-01 6.43039522e-02 1.85301368e-07]
[9.80621190e-01 1.93787398e-02 7.00125265e-08]
[1.68478817e-04 3.30167227e-01 6.69664294e-01]
[3.54046168e-03 4.02267804e-01 5.94191734e-01]
[9.70617284e-01 2.93824735e-02 2.42443971e-07]
[2.56895209e-04 1.54631583e-01 8.45111521e-01]
[3.48668493e-02 9.11966140e-01 5.31670110e-02]
[1.47218849e-02 6.84038113e-01 3.01240002e-01]
[9.46510460e-04 4.28641987e-01 5.70411502e-01]
[9.64848137e-01 3.51516747e-02 1.87917886e-07]
[9.70436779e-01 2.95624021e-02 8.18591621e-07]]
The accuracy of the Logistic Regression is: 0.9833333333333333
The accuracy of the Logistic Regression is: 0.8666666666666667
##查看混淆矩阵
confusion_matrix_result=metrics.confusion_matrix(test_predict,y_test)
print('The confusion matrix result:\n',confusion_matrix_result)
##利用热力图对于结果进行可视化
plt.figure(figsize=(8,6))
sns.heatmap(confusion_matrix_result,annot=True,cmap='Blues')
plt.xlabel('Predicted labels')
plt.ylabel('True labels')
plt.show()
##The confusion matrix result:
##[[10 0 0]
##[0 8 2]
##[0 2 8]]
The confusion matrix result:
[[10 0 0]
[ 0 8 2]
[ 0 2 8]]

逻辑回归原理
当z≥0 时,y≥0.5,分类为1,当 z<0时,y<0.5,分类为0,其对应的y值我们可以视为类别1的概率预测值。Logistic回归虽然名字里带“回归”,但是它实际上是一种分类方法,主要用于两分类问题(即输出只有两种,分别代表两个类别),所以利用了Logistic函数(或称为Sigmoid函数),函数形式为:
x = np.arange(-5,5,0.01)
y = 1/(1+np.exp(-x))
plt.plot(x,y)
plt.xlabel('z')
plt.ylabel('y')
plt.grid()
plt.show()
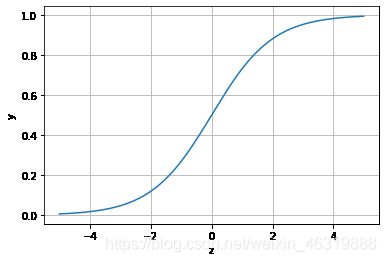
通过上图我们可以发现 Logistic 函数是单调递增函数,并且在z=0,而回归的基本方程:
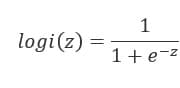
将回归方程写入其中为:
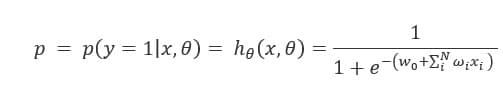
所以,
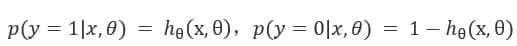
逻辑回归从其原理上来说,逻辑回归其实是实现了一个决策边界:对于函数,当z≥0 时,y≥0.5,分类为1,当 z<0时,y<0.5,分类为0,其对应的y值我们可以视为类别1的概率预测值。
对于模型的训练而言:实质上来说就是利用数据求解出对应的模型的特定的ω。从而得到一个针对于当前数据的特征逻辑回归模型。
而对于多分类而言,将多个二分类的逻辑回归组合,即可实现多分类。