Hive concat函数和concat_ws函数和concat_group函数&row_number over()和sum() over()&列转行,行转列
concat函数,concat_ws函数,concat_group函数
hivesql中的concat函数,concat_ws函数,concat_group函数之间的区别
CONCAT()函数
CONCAT()函数用于将多个字符串连接成一个字符串。
使用数据表Info作为示例,其中
SELECT id,name FROM info LIMIT 1;的返回结果为
±—±-------+
| id | name |
±—±-------+
| 1 | BioCyc |
±—±-------+
1.1、语法及使用特点:
CONCAT(str1,str2,…)
返回结果为连接参数产生的字符串。如有任何一个参数为NULL ,则返回值为 NULL。可以有一个或多个参数。
使用示例:
SELECT CONCAT(id, ‘,’, name) AS con FROM info LIMIT 1;返回结果为
+----------+
| con |
+----------+
| 1,BioCyc |
+----------+
SELECT CONCAT(‘My’, NULL, ‘QL’);返回结果为
+--------------------------+
| CONCAT('My', NULL, 'QL') |
+--------------------------+
| NULL |
+--------------------------+
CONCAT_WS函数
如何指定参数之间的分隔符,使用函数CONCAT_WS()。使用语法为:CONCAT_WS(separator,str1,str2,…)
CONCAT_WS() 代表 CONCAT With Separator ,是CONCAT()的特殊形式。第一个参数是其它参数的分隔符。分隔符的位置放在要连接的两个字符串之间。分隔符可以是一个字符串,也可以是其它参数。如果分隔符为 NULL,则结果为 NULL。函数会忽略任何分隔符参数后的 NULL 值。但是CONCAT_WS()不会忽略任何空字符串。 (然而会忽略所有的 NULL)。
如SELECT CONCAT_WS('_',id,name) AS con_ws FROM info LIMIT 1;返回结果为
+----------+
| con_ws |
+----------+
| 1_BioCyc |
+----------+
SELECT CONCAT_WS(',','First name',NULL,'Last Name');返回结果为
+----------------------------------------------+
| CONCAT_WS(',','First name',NULL,'Last Name') |
+----------------------------------------------+
| First name,Last Name |
+----------------------------------------------+
GROUP_CONCAT()函数
GROUP_CONCAT函数返回一个字符串结果,该结果由分组中的值连接组合而成。
使用表info作为示例,其中语句SELECT locus,id,journal FROM info WHERE locus IN(‘AB086827’,‘AF040764’);的返回结果为
±---------±—±-------------------------+
| locus | id | journal |
±---------±—±-------------------------+
| AB086827 | 1 | Unpublished |
| AB086827 | 2 | Submitted (20-JUN-2002) |
| AF040764 | 23 | Unpublished |
| AF040764 | 24 | Submitted (31-DEC-1997) |
±---------±—±-------------------------+
1、使用语法及特点:
GROUP_CONCAT([DISTINCT] expr [,expr …]
[ORDER BY {unsigned_integer | col_name | formula} [ASC | DESC] [,col …]]
[SEPARATOR str_val])
在 MySQL 中,你可以得到表达式结合体的连结值。通过使用 DISTINCT 可以排除重复值。如果希望对结果中的值进行排序,可以使用 ORDER BY 子句。
SEPARATOR 是一个字符串值,它被用于插入到结果值中。缺省为一个逗号 (","),可以通过指定 SEPARATOR “” 完全地移除这个分隔符。
可以通过变量 group_concat_max_len 设置一个最大的长度。在运行时执行的句法如下: SET [SESSION | GLOBAL] group_concat_max_len = unsigned_integer;
如果最大长度被设置,结果值被剪切到这个最大长度。如果分组的字符过长,可以对系统参数进行设置:SET @@global.group_concat_max_len=40000;
2、使用示例:
语句 SELECT locus,GROUP_CONCAT(id) FROM info WHERE locus IN('AB086827','AF040764') GROUP BY locus; 的返回结果为
+----------+------------------+
| locus | GROUP_CONCAT(id) |
+----------+------------------+
| AB086827 | 1,2 |
| AF040764 | 23,24 |
+----------+------------------+
语句 SELECT locus,GROUP_CONCAT(distinct id ORDER BY id DESC SEPARATOR '_') FROM info WHERE locus IN('AB086827','AF040764') GROUP BY locus;的返回结果为
+----------+----------------------------------------------------------+
| locus | GROUP_CONCAT(distinct id ORDER BY id DESC SEPARATOR '_') |
+----------+----------------------------------------------------------+
| AB086827 | 2_1 |
| AF040764 | 24_23 |
+----------+----------------------------------------------------------+
语句SELECT locus,GROUP_CONCAT(concat_ws(', ',id,journal) ORDER BY id DESC SEPARATOR '. ') FROM info WHERE locus IN('AB086827','AF040764') GROUP BY locus;的返回结果为
+----------+--------------------------------------------------------------------------+
| locus | GROUP_CONCAT(concat_ws(', ',id,journal) ORDER BY id DESC SEPARATOR '. ') |
+----------+--------------------------------------------------------------------------+
| AB086827 | 2, Submitted (20-JUN-2002). 1, Unpublished |
| AF040764 | 24, Submitted (31-DEC-1997) . 23, Unpublished
窗口函数 row_number over()和sum() over()
row_number over()的使用:
假如我们有这样一组数据,我们需要求出不同性别的年龄top2的人的信息。这个时候怎么做?
可能我们会首先想到分组,但是分组只能值top1,怎么样能求出top2,top3呢?这时候我们想如果分组后能够按照年龄排序然后标出来序号就好了!
id age name sex
1,18,xiaoli,male
2,19,wang,male
3,22,liu,female
4,16,dawei,male
5,30,erbao,male
6,26,xiao,female
7,18,chengua,male
下面就介绍一个非常有用的函数:row_number() over()他的作用就是分组排序加上序号标记
比如以上求解不同性别的年龄top2,我们可以这样做:
建表导入数据:
create table rownumber(id string,age int,name string,sex string)
row format delimited
fields terminated by ‘,’;
load data local inpath ‘xxx’ into table rownumber;
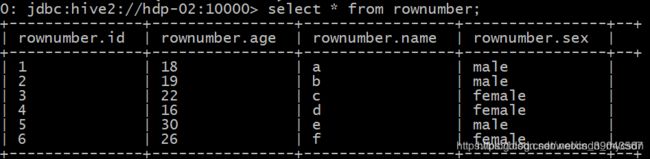
select id,age,name,sex,
row_number() over(partition by sex order by age desc) as rownumber
from rownumber;
我们可以清楚的看到 row_number() over(partition by sex order by age desc) as rownumber
就相当于增加了一列序号,over()中partition by sex是按照sex分组,order by age desc按照年龄降序排序,然后row_number()在加上序号。
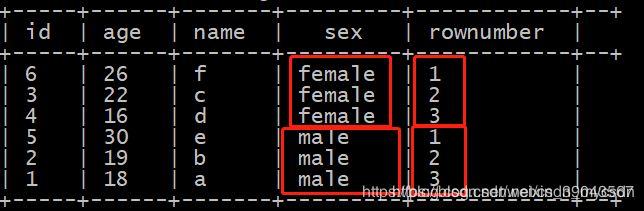
select id,age,name,sex
from
(select id,age,name,sex,
row_number() over(partition by sex order by age desc) as rownumber
from rownumber ) temp
where rownumber<3;
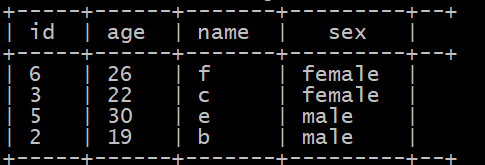
这样就求出分组topn了,很方便!
sum() over()
有这样的数据:第一列name,第二列月份mon,第三列金额jine
A,2015-01,5
A,2015-01,15
B,2015-01,5
A,2015-01,8
B,2015-01,25
A,2015-01,5
C,2015-01,10
C,2015-01,20
A,2015-02,4
A,2015-02,6
C,2015-02,30
C,2015-02,10
B,2015-02,10
B,2015-02,5
A,2015-03,14
A,2015-03,6
B,2015-03,20
B,2015-03,25
C,2015-03,10
C,2015-03,20
我们需要求出对于每个人的一个月的总额和累计到当前月的总额。
传统方法非常的麻烦,具体思路是;先求出月总额表(name,mon,amount),然后讲月总额表自联结,在过滤当前月份后面的月份,最终在求和。
使用sum() over()可以轻松给解决,sum()首先我们都知道是求和,加上over()就是针对某个窗口求和了,具体哪个窗口呢?
具体实现:
求出每月的总额 放到表中,先将数据加载到表中,在求月总额
create table monsum(name string,mon string,jine string)
row format delimited
fields terminated by ',';
load data local inpath '/root/mytest/sumreport.dat' into table monsum;
--求出月总额
create table monamount
as
select name,mon,sum(jine) as amount
from monsum
group by name,mon;
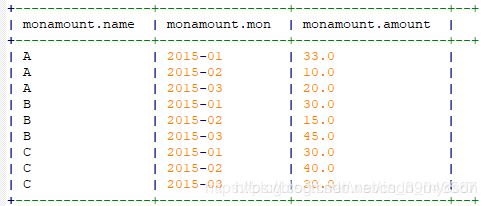
然后使用窗口函数求出累计当前月总额,
select name,mon,amount,
sum(amount) over(partition by name order by mon rows between unbounded preceding and current row) as account
from monamount;
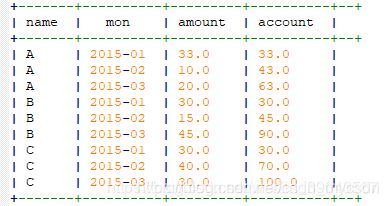
sum(amount)的求和是针对后面over()窗口的求和,
over中partition by name order by mon 针对name这一组按照月份排序,
rows between unbounded preceding and current 限定了行是按照在当前行不限定的往前处理,通俗就是处理当前以及之前的所有行的sum,即3月时sum(amount)求的时123月的和,2月时sum(amount)求的是12月的和。
unbounded意思无限的 preceding在之前的,current row当前行。
Hive之列转行,行转列
列转行
测试数据
hive> select * from col_lie limit 10;
OK
col_lie.user_id col_lie.order_id
104399 1715131
104399 2105395
104399 1758844
104399 981085
104399 2444143
104399 1458638
104399 968412
104400 1609001
104400 2986088
104400 1795054
把相同user_id的order_id按照逗号转为一行
select user_id,
concat_ws(',',collect_list(order_id)) as order_value
from col_lie
group by user_id
limit 10;
//结果(简写)
user_id order_value
104399 1715131,2105395,1758844,981085,2444143
总结
使用函数:concat_ws(’,’,collect_set(column))
说明:collect_list 不去重,collect_set 去重。 column的数据类型要求是string
行转列
测试数据
hive> select * from lie_col;
OK
lie_col.user_id lie_col.order_value
104408 2909888,2662805,2922438,674972,2877863,190237
104407 2982655,814964,1484250,2323912,2689723,2034331,1692373,677498,156562,2862492,338128
104406 1463273,2351480,1958037,2606570,3226561,3239512,990271,1436056,2262338,2858678
104405 153023,2076625,1734614,2796812,1633995,2298856,2833641,3286778,2402946,2944051,181577,464232
104404 1815641,108556,3110738,2536910,1977293,424564
104403 253936,2917434,2345879,235401,2268252,2149562,2910478,375109,932923,1989353
104402 3373196,1908678,291757,1603657,1807247,573497,1050134,3402420
104401 814760,213922,2008045,3305934,2130994,1602245,419609,2502539,3040058,2828163,3063469
104400 1609001,2986088,1795054,429550,1812893
104399 1715131,2105395,1758844,981085,2444143,1458638,968412
Time taken: 0.065 seconds, Fetched: 10 row(s)
将order_value的每条记录切割为单元素
select user_id,order_value,order_id
from lie_col
lateral view explode(split(order_value,',')) num as order_id
limit 10;
//结果
user_id order_value order_id
104408 2909888,2662805,2922438,674972,2877863,190237 2909888
104408 2909888,2662805,2922438,674972,2877863,190237 2662805
104408 2909888,2662805,2922438,674972,2877863,190237 2922438
104408 2909888,2662805,2922438,674972,2877863,190237 674972
104408 2909888,2662805,2922438,674972,2877863,190237 2877863
104408 2909888,2662805,2922438,674972,2877863,190237 190237
104407 2982655,814964,1484250,2323912,2689723,2034331,1692373,677498,156562,2862492,338128 2982655
104407 2982655,814964,1484250,2323912,2689723,2034331,1692373,677498,156562,2862492,338128 814964
104407 2982655,814964,1484250,2323912,2689723,2034331,1692373,677498,156562,2862492,338128 1484250
104407 2982655,814964,1484250,2323912,2689723,2034331,1692373,677498,156562,2862492,338128 2323912
Time taken: 0.096 seconds, Fetched: 10 row(s)