IBM秀出并行训练肌肉:256个GPU还能有95%的拓展效率,顺便刷新ImageNet-22K记录
雷锋网(公众号:雷锋网) AI 科技评论按:IBM 研究院上传了一篇论文到 arXiv,介绍了自己几乎能够达到理想性能的分布式深度学习软件,它不仅带来了优秀的沟通开销,让64台IBM服务器上的256个英伟达GPU发挥出了95%的拓展效率,训练时间和模型准确率也分别创下了新纪录。完成这项研究的团队负责人 IBM Fellow Hillery Hunter 也为此撰写了一篇文章,介绍了这个软件的更多信息。雷锋网 AI 科技评论编译如下。
深度学习是一种广泛使用的人工智能方法,它可以让计算机理解和提取画面和声音中的含义,人类世界对世界的大多数体验也就是来自这两种感官的。这样的技术有潜力给生活中的方方面面带来突破,小到手机上的app,大到医学图像诊断。但是如何提升深度学习的准确率和如何构建大规模的实用深度学习系统这两个技术问题一直横亘在人们面前,比如大型的、复杂的深度学习模型所需的训练时间就需要几天甚至几周。
IBM 研究院中的一支团队就一直专注于解决这样的问题,他们的目标是降低用大规模数据集训练大型模型所需的时间,最好能把训练时间从几天、几小时,缩短到几分钟、几秒,同时还要提高模型的准确率。这是非常宏大的挑战,他们依靠在数量众多的服务器和英伟达GPU上运行分布式深度学习来应对挑战。
大多数热门的深度学习框架都可以方便地从单个GPU拓展到同一个服务器内的多个GPU上,但是继续拓展到多个服务器之间就不行了。IBM团队(Minsik Cho, Uli Finkler, David Kung等人)就在这里施展拳脚,他们重新编写了软件和算法,让大规模、复杂的计算任务可以在几十个服务器中的上百个GPU之间自动并行并优化。

IBM Fellow Hillery Hunter主导开发的新软件让GPU的处理速度提升到了前所未有的水平
在 ImageNet-22K 中比微软更快、更强
IBM 的软件除了能够让不同服务器之间的训练过程完全同步之外,它们的沟通开销也非常小。从结果上看,当深度学习算法拓展到了超过100个英伟达GPU上以后,它在具有750万图像的 ImageNet-22K 数据集的图像识别测试中创造了33.8%准确率的新纪录,这项测试此前的最好结果是来自微软的29.8%。在这项测试中得到4%的准确率提升是非常难得的,以往的各项研究所能带来的提升往往都不到1%。IBM 开发出的分布式深度学习(distributed deep learning,DDL)方法不仅让他们在准确率上得到了惊人的提升,在装着上百个英伟达GPU的几十台服务器上训练一个 ResNet-101 神经网络需要的时间也只需要不到7个小时;微软训练同一个模型花了10天。正是靠着 DDL 代码和算法解决了本来强大的深度学习框架在拓展性方面的诸多问题,IBM 才能够达成这样的成果。
模型训练之后的测试就是在极限状况下考察模型的表现,即便 33.8% 的准确率乍一听不是很诱人,它也比以往的结果有着显著提高。对于任意一张测试图像,这个训练后的人工智能模型从在2万2千个物体种类中选出它判断的可能性最高的类别,所选结果的准确率就是这个33.8%。IBM 的这项技术可以让其它用来执行具体任务的人工智能模型,比如医学图像的癌细胞检测,拥有更精确的诊断,而且可以在短短几个小时内重新训练完毕。
“盲人摸象”
Facebook 2017年6月的一篇论文中介绍了他们用较小的模型(ResNet 50)在较小的数据集(ImageNet-1k)上取得的优异成绩。文中他们也这样描述了所遇到的问题:“深度学习需要大规模的神经网络和大规模的数据集。然而它们带来的结果是更长的训练时间,这就对研究和开发过程都造成了很大阻碍。”
但是滑稽的是,在多个服务器上对深度学习问题做协作计算和优化,随着GPU越来越快变得越来越难。这种现象给深度学习系统带来的功能损失就推动着 IBM 团队开发新的 DDL 软件,来让热门开源软件 Tensorflow、Caffe、Torch、Chainer 上的大规模神经网络也可以高速、高准确率地处理大规模数据集。
IBM 的研究员用盲人摸象的故事来形容他们要解决的问题:“每个盲人都摸到了大象身上的一小部分,但只能摸到一个部分,比如肚子或者象牙。然后他们就根据自己那一小部分的经验来描述整个大象,他们的意见也就完全统一不起来”。现在,在最初的意见冲突之后,如果给他们足够的时间,他们其实可以互相之间分享信息,足够多的小块信息拼起来就可以对整个大象有不错的整体感知。
并行训练就跟这个类似,如果用一组 GPU 分别处理深度学习训练问题中的一部分,目前来讲整个并行训练过程还是要花几天或者几个星期,那么把这些训练结果同步起来并不算难。但是随着 GPU 变得越来越快,它们学习的速度也快多了,每个GPU和其它GPU分享学习结果的所需的速度已经不是传统软件可以提供的了。这就对系统网络带来了很大的压力,同时也是一个麻烦的技术问题。简单点说,更聪明、更快的学习者(GPU们)需要更好的沟通方式,不然它们之间无法同步,大多数的时间就会浪费在等待别人的学习结果中——这样一来更多、更快的GPU可能就不会带来更高的性能,性能降低都是有可能的。
IBM 通过 DDL 软件近乎完美地解决了这种拓展带来的性能损失问题,最显著的体现指标就是拓展效率,换句话说就是随着GPU数目的增加,实际系统和理想系统之间的差距有多大。这个指标也从侧面反映了学习过程中这256个GPU之间互相沟通得到底好不好。
在 ImageNet-1K 中比 Facebook 更高效
此前256个GPU协作的最好结果是 Facebook AI 研究院中的一支团队达成的,他们用了一个较小的深度学习模型 ResNet 50,用到的数据集也是较小的 ImageNet-1K,其中有大概一百三十万张图像;更小的模型和更少的数据都可以降低计算复杂度。选择了较大的8192的batch size之后,在一个具有256块英伟达P100 GPU的服务器集群上通过Caffe2深度学习软件达到了89%的拓展效率。IBM 用同样的数据集也训练了一个 ResNet 50 模型,通过 DDL 软件,他们用 Caffe 获得了高达95%的拓展效率,如下图。它运行在一个有64台“Minsky” Power S822LC服务器的集群上,每个服务器上有4块P100 GPU。
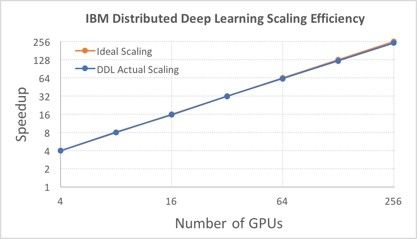
在大模型、大数据集的 ImageNet-22K 中的750万张图像训练 ResNet 101模型任务中,在选择了 5120的batch size以后,IBM 也达到了88%的拓展效率。
IBM 的团队还创造了一项新纪录,此前 Facebook 保持了用 ImageNet-1K 数据集训练 ResNet 50 模型只需要1个小时的记录,IBM 借助 DDL 把基于 Torch 的模型拓展到了256块GPU上,训练所需时间随之刷新到了50分钟。Facebook 的模型是基于 Caffe2的。
对开发者和数据科学家来说,IBM 研究团队的 DDL 软件提供了整套的 API 可供各种深度学习框架调用,以便拓展到多台服务器上。在 PowerAI 企业级深度学习软件第4版中就会带有一个 DDL 的技术预览版,从而给任何需要训练深度学习模型的企业提供这样的集群拓展特性。在给人工智能大家庭提供了这样的 DDL特性以后,IBM 的研究团队希望更多的人在掌握了计算机集群的力量以后也可以达成更高的模型准确率。
论文地址:https://arxiv.org/abs/1708.02188
via IBM Research Blog,雷锋网 AI 科技评论编译
相关文章:
腾讯正式开源高性能分布式计算平台Angel1.0,追赶同行脚步
Keras 之父讲解 Keras:几行代码就能在分布式环境训练模型 | Google I/O 2017
分布式机器学习时代即将来临?谷歌推出“Federated Learning”
本文作者:杨晓凡
本文转自雷锋网禁止二次转载,原文链接