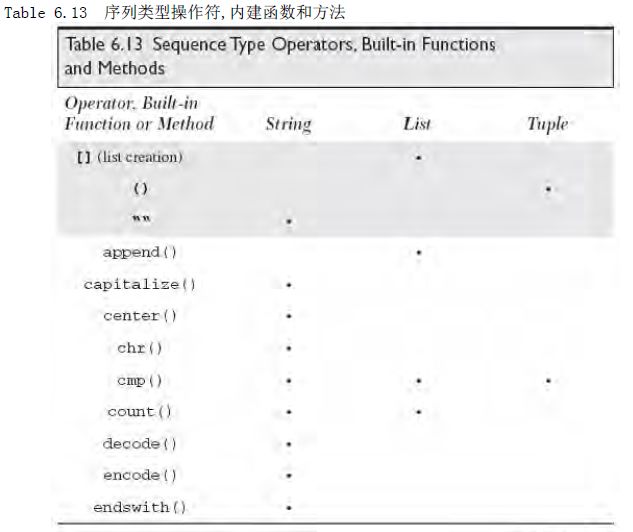
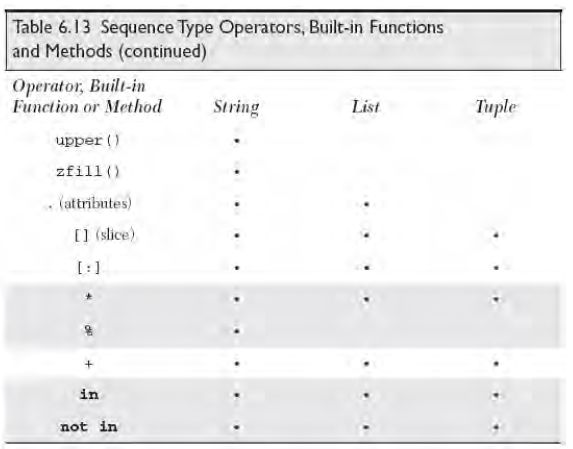
1.序列
序列类型有着相同的访问模式:它的每一个元素可以通过指定一个偏移量的方式得到。而多个元素可以通过切片操作的方式一次得到。下标偏移量是从0 开始到 总元素数-1 结束 -- 之所以要减一是因为我们是从0 开始计数的。
| 序列类型操作符 | |
| 序列操作符 | 作用 |
| seq[ind] | 获得下标为ind 的元素 |
| seq[ind1:ind2] | 获得下标从ind1 到ind2 间的元素集合 |
| seq * expr | 序列重复expr 次 |
| seq1 + seq2 | 连接序列seq1 和seq2 |
| obj in seq | 判断obj 元素是否包含在seq 中 |
| obj not in seq | 判断obj 元素是否不包含在seq 中 |
成员关系操作符 (in, not in):成员关系操作符使用来判断一个元素是否属于一个序列的。in/not in 操作符的返回值一般来讲就是True/False,满足成员关系就返回True,否则返回False。该操作符的语法如下:obj [not] in sequence
连接操作符(+):这个操作符允许我们把一个序列和另一个相同类型的序列做连接。语法如下:sequence1 + sequence2。该表达式的结果是一个包含sequence1 和sequence2 的内容的新序列。
重复操作符(*):当你需要需要一个序列的多份拷贝时,重复操作符非常有用,它的语法如下:sequence * copies_int。该操作符返回一个新的包含多份原对象拷贝的对象。
切片操作符([],[:],[::]):所谓序列类型就是包含一些顺序排列的对象的一个结构。你可以简单的用方括号加一个下标的方式访问它的每一个元素,或者通过在方括号中用冒号把开始下标和结束下标分开的方式来访问一组连续的元素。
序列类型是其元素被顺序放置的一种数据结构类型,这种方式允许通过指定下标的方式来获得某一个数据元素,或者通过指定下标范围来获得一组序列的元素.这种访问序列的方式叫做切片,我们通过切片操作符就可以实现我们上面说到的操作。访问某一个数据元素的语法如下:sequence[index]。sequence 是序列的名字,index 是想要访问的元素对应的偏移量。偏移量可以是正值,范围从0 到偏移最大值(比序列长度少一),用len()函数,可以得到序列长度,实际的范围是 0 <= inde <= len(sequece)-1 。另外,也可以使用负索引,范围是 -1 到序列的负长度,-len(sequence), -len(sequence) <= index <= -1。正负索引的区别在于正索引以序列的开始为起点,负索引以序列的结束为起点。
因为Python 是面向对象的,所以你可以像下面这样直接访问一个序列的元素(不用先把它赋值给一个变量):
>>> print ('Faye', 'Leanna', 'Daylen')[1]
Leanna
若想一次得到多个元素呢?只要简单的给出开始和结束的索引值,并且用冒号分隔就可以了,其语法如下:sequence[starting_index:ending_index]。通过这种方式我们可以得到从起始索引到结束索引(不包括结束索引对应的元素)之间的一"片"元素.起始索引和结束索引都是可选的,如果没有提供或者用None 作为索引值,切片操作会从序列的最开始处开始,或者直到序列的最末尾结束。序列的最后一个切片操作是扩展切片操作,它多出来的第三个索引值被用做步长参数。
内建函数list(),str()和tuple()被用做在各种序列类型之间转换。
| 序列类型转换工厂函数 | |
| 函数 | 含义 |
| list(iter) | 把可迭代对象转换为列表 |
| str(obj) | 把obj 对象转换成字符串(对象的字符串表示法) |
| unicode(obj) | 把对象转换成Unicode 字符串(使用默认编码) |
| basestring() | 抽象工厂函数,其作用仅仅是为str 和unicode 函数提供父类,所以不能被 |
| tuple(iter) | 把一个可迭代对象转换成一个元组对象 |
| 序列类型可用的内建函数 | |
| 函数名 | 功能 |
| enumerate(iter) | 接受一个可迭代对象作为参数,返回一个enumerate 对象(同时也是一个迭代器),该对象生成由iter 每个元素的index 值和item 值组成的元组(PEP 279) |
| len(seq) | 返回seq 的长度 |
| max(iter,key=None) 0r max(arg0,arg1……,key=None) |
返回iter 或(arg0,arg1,...)中的最大值,如果指定了key,这个key 必须是一个可以传给sort()方法的,用于比较的回 |
| min(iter,key=None) or min(arg0,arg1……,key=None) |
返回iter 里面的最小值;或者返回(arg0,arg2,...)里面 的最小值;如果指定了key,这个key 必须是一个可以传给 |
| reversed(seq) | 接受一个序列作为参数,返回一个以逆序访问的迭代器(PEP 322) |
| sorted(iter,func=None,key=None,reverse=False) | 接受一个可迭代对象作为参数,返回一个有序的列表;可选参数func,key 和reverse 的含义跟list.sort()内建函数的参数含义一 |
| sum(seq,init=0) | 返回seq 和可选参数init 的总和, 其效果等同于reduce(operator.add,seq,init) |
| zip([it0,it1,……itN]) | 返回一个列表,其第一个元素是it0,it1,...这些元素的第一个元素组成的一个元组,第二个...,类推. |
2.字符串
字符串类型是Python 里面最常见的类型.我们可以简单地通过在引号间包含字符的方式创建它。Python 里面单引号和双引号的作用是相同的。字符串是不可变类型,就是说改变一个字符串的元素需要新建一个新的字符串.字符串是由独立的字符组成的,并且这些字符可以通过切片操作顺序地访问。
创建一个字符串就像使用一个标量一样简单,在字符串后用方括号加一个或者多于一个索引的方式来获得子串。通过给一个变量赋值(或者重赋值)的方式“更新”一个已有的字符串.新的值可能与原有值差不多,也可能跟原有串完全不同。跟数字类型一样,字符串类型也是不可变的,所以你要改变一个字符串就必须通过创建一个新串的方式来实现。也就是说你不能只改变一个字符串的一个字符或者一个子串,然而,通过拼凑一个旧串的各个部分来得到一个新串是被允许的。
字符串是不可变的,所以你不能仅仅删除一个字符串里的某个字符,你能做的是通过赋一个空字符串或者使用del 语句来清空或者删除一个字符串。
3.字符串和操作符
正向索引时,索引值开始于0,结束于总长度减1(因为我们是从0 开始索引的)。在这个范围内,我们可以访问任意的子串。用一个参数来调用切片操作符结果是一个单一字符,而使用一个数值范围(用':')作为参数调用切片操作的参数会返回一串连续地字符。再强调一遍,对任何范围[start:end],我们可以访问到包括start 在内到end(不包括end)的所有字符,换句话说,假设x 是[start:end]中的一个索引值,那么有: start<= x < end。
在进行反向索引操作时,是从-1 开始,向字符串的开始方向计数,到字符串长度的负数为索引的结束(-len(str))。如果开始索引或者结束索引没有被指定,则分别以字符串的第一个和最后一个索引值为默认值。
注:起始/结束索引都没有指定的话会返回整个字符串。
成员操作符(in ,not in):成员操作符用于判断一个字符或者一个子串(中的字符)是否出现在另一个字符串中。出现则返回True,否则返回False。
注:成员操作符不是用来判断一个字符串是否包含另一个字符串的,这样的功能由find()或者index()(还有它们的兄弟:rfind()和rindex())函数来完成。
连接符( + ):运行时刻字符串连接。通过连接操作符来从原有字符串获得一个新的字符串。
编译时字符串连接,Python 的语法允许你在源码中把几个字符串连在一起写,以此来构建新字符串。可以在一行里面混用两种引号,这种写法的好处是你可以把注释也加进来。
若把一个普通字符串和一个Unicode 字符串做连接处理,Python 会在连接操作前先把普通字符串转化为Unicode 字符串。
重复操作符创建一个包含了原有字符串的多个拷贝的新串。
4.只适用于字符串的操作符
格式化操作符(%):只适用于字符串类型。ex:print("str %s %d" % (name,20)) =》str name 20
| 字符串格式化符号 | |
| 格式化字符 | 转换方式 |
| %c | 转换成字符(ASCII 码值,或者长度为一的字符串) |
| %r | 优先用repr()函数进行字符串转换 |
| %s | 优先用str()函数进行字符串转换 |
| %d %i | 转成有符号十进制数 |
| %u | 转成无符号十进制数 |
| %o | 转成无符号八进制数 |
| %x %X | (Unsigned)转成无符号十六进制数(x/X 代表转换后的十六进制字符的大小写) |
| %e %E | 转成科学计数法(e/E 控制输出e/E) |
| %f %F | 转成浮点数(小数部分自然截断) |
| %g %G | %e 和%f/%E 和%F 的简写 |
| %% | 输出% |
格式字符串既可以跟print 语句一起用来向终端用户输出数据,又可以用来合并字符串形成新字符串,而且还可以直接显示到GUI(Graphical User Interface)界面上去。
| 格式化操作符辅助指令 | |
| 符号 | 作用 |
| * | 定义宽度或者小数点精度 |
| - | 用做左对齐 |
| + | 在正数前面显示加号( + ) |
| 在正数前面显示空格 | |
| # | 在八进制数前面显示零('0'),在十六进制前面显示'0x'或者'0X'(取决于用的是'x'还是'X') |
| 0 | 显示的数字前面填充‘0’而不是默认的空格 |
| % | '%%'输出一个单一的'%' |
| (var) | 映射变量(字典参数) |
| m.n | m 是显示的最小总宽度,n 是小数点后的位数(如果可用的话) |
Template 对象有两个方法,substitute()和safe_substitute()。前者更为严谨,在key 缺少的情况下它会报一
个KeyError 的异常出来,而后者在缺少key 时,直接原封不动的把字符串显示出来。
原始字符串操作符(r/R):在原始字符串里,所有的字符都是直接按照字面的意思来使用,没有转义特殊或不能打印的字符。正则表达式是一些定义了高级搜索匹配方式的字符串,通常是由代表字符,分组、匹配信息、变量名、和字符类等的特殊符号组成。这个'r'可以是小写也可以是大写,唯一的要求是必须紧靠在第一个引号前。
Unicode字符串操作符(u/U):把标准字符串或者是包含Unicode 字符的字符串转换成完全地Unicode 字符串对象。Unicode 操作符必须出现在原始字符串操作符前面
5.内建函数
cmp():同比较操作符一样,内建的cmp()函数也根据字符串的ASCII 码值进行比较。
len():内建函数len()返回字符串的字符数。
max() and min(): 对于string 类型它们能很好地运行,返回最大或者最小的字符,(按照ASCII 码值排列)。
enumerate():>>> s = 'foobar'
>>> for i, t in enumerate(s):
... print i, t
...
0 f
1 o
2 o
3 b
4 a
5 r
zip():>>> s, t = 'foa', 'obr'
>>> zip(s, t)
[('f', 'o'), ('o', 'b'), ('a', 'r')]
raw_input():内建的raw_input()函数使用给定字符串提示用户输入并将这个输入返回。
str() and unicode():str()和unicode()函数都是工厂函数,就是说产生所对应的类型的对象。它们接受一个任意类型的对象,然后创建该对象的可打印的或者Unicode 的字符串表示。它们和basestring 都可以作为参数传给isinstance()函数来判断一个对象的类型。
chr(),unichr(), and ord():chr()函数用一个范围在range(256)内的(就是0 到255)整数做参数,返回一个对应的字符。unichr()跟它一样,只不过返回的是Unicode 字符,ord()函数是chr()函数(对于8 位的ASCII 字符串)或unichr()函数(对于Unicode 对象)的配对函数,它以一个字符(长度为1 的字符串)作为参数,返回对应的ASCII 数值,或者Unicode数值,如果所给的Unicode 字符超出了你的Python 定义范围,则会引发一个TypeError 的异常。
6.字符串内建函数
| 字符串类型内建方法 | |
| 方法 | 描述 |
| string.capitalize() | 把字符串的第一个字符大写 |
| string.center(width) | 返回一个原字符串居中,并使用空格填充至长度width 的新字符串 |
| string.count(str, beg=0, |
返回str 在string 里面出现的次数,如果beg 或者end 指定则返回指定范围内str 出现的次数 |
| string.decode(encoding='UTF-8',errors='strict') |
以encoding 指定的编码格式解码string,如果出错默认报一个ValueError 的异常, 除非errors 指定的是'ignore' 或者'replace' |
| string.encode(encoding='UTF-8',errors='strict') |
以encoding 指定的编码格式编码string,如果出错默认报一个 |
| string.endswith(obj, beg=0, |
检查字符串是否以obj 结束,如果beg 或者end 指定则检查指 |
| string.expandtabs(tabsize=8) | 把字符串string 中的tab 符号转为空格,默认的空格数tabsize 是8. |
| string.find(str, beg=0, end=len(string)) |
检测str 是否包含在string 中,如果beg 和end 指定范围,则检查是否包含在指定范围内,如果是返回开始的索引值,否则返回-1 |
| string.index(str, beg=0, |
跟find()方法一样,只不过如果str 不在string 中会报一个异常. |
| string.isalnum() | R 如果string 至少有一个字符并且所有字符都是字母或数字则返回True,否则返回False |
| string.isalpha() | 如果string 至少有一个字符并且所有字符都是字母则返回True, |
| string.isdecimal() | 如果string 只包含十进制数字则返回True 否则返回False. |
| string.isdigit() | 如果string 只包含数字则返回True 否则返回False. |
| string.islower() | 如果string 中包含至少一个区分大小写的字符,并且所有这些(区分 |
| string.isnumeric() | 如果string 中只包含数字字符,则返回True,否则返回False |
| string.isspace() | 如果string 中只包含空格,则返回True,否则返回False. |
| string.istitle() | 如果string 是标题化的(见title())则返回True,否则返回False |
| string.isupper() | 如果string 中包含至少一个区分大小写的字符,并且所有这些(区分 |
| string.join(seq) | Merges (concatenates)以string 作为分隔符,将seq 中所有的元素 |
| string.ljust(width) | 返回一个原字符串左对齐,并使用空格填充至长度width 的新字符串 |
| string.lower() | 转换string 中所有大写字符为小写 |
| string.lstrip() | 截掉string 左边的空格 |
| string.partition(str) | 有点像find()和split()的结合体,从str 出现的第一个位置起,把字符串string 分成一个3 元素的元组(string_pre_str,str,string_post_str),如果string 中不包含str 则string_pre_str == string. |
| string.replace(str1, str2, |
把string 中的str1 替换成str2,如果num 指定,则替换不超过num 次. |
| string.rfind(str, beg=0,end=len(string)) | 类似于find()函数,不过是从右边开始查找. |
| string.rindex( str, beg=0,end=len(string)) | 类似于index(),不过是从右边开始. |
| string.rjust(width) | 返回一个原字符串右对齐,并使用空格填充至长度width 的新字符串 |
| string.rpartition(str) | 类似于partition()函数,不过是从右边开始查找. |
| string.rstrip() | 删除string 字符串末尾的空格. |
| string.split(str="", num=string.count(str)) | 以str 为分隔符切片string,如果num有指定值,则仅分隔num 个子字符串 |
| string.splitlines(num=string.count('\n')) | 按照行分隔,返回一个包含各行作为元素的列表,如果num 指定则仅切片num 个行. |
| string.startswith(obj, beg=0,end=len(string)) | 检查字符串是否是以obj 开头,是则返回True,否则返回False。如果beg 和end 指定值,则在指定范围内检查. |
| string.strip([obj]) | 在string 上执行lstrip()和rstrip() |
| string.swapcase() | 翻转string 中的大小写 |
| string.title() | 返回"标题化"的string,就是说所有单词都是以大写开始,其余字母均为小写(见istitle()) |
| string.translate(str, del="") | 根据str 给出的表(包含256 个字符)转换string 的字符, |
| string.upper() | 转换string 中的小写字母为大写 |
| string.zfill(width) | 返回长度为width 的字符串,原字符串string 右对齐,前面填充0 |
7. 字符串的独特特性
除了通常用的特殊字符,比如换行符(\n),tab 符(\t)之外,也可以直接用ASCII 码值来标示特殊字符:\000 或者\xXX,分别对应字符的八进制和十六进制ASCII 码值。
| 反斜杠开头的转义字符 | |||||
| /X | 八进制 | 十进制 | 十六进制 | 字符 | 说明 |
| \0 | 000 | 0 | 0x00 | NUL | 空字符Nul |
| \a | 007 | 7 | 0x07 | BEL | 响铃字符 |
| \b | 010 | 8 | 0x08 | BS | 退格 |
| \t | 011 | 9 | 0x09 | HT | 横向制表符 |
| \n | 012 | 10 | 0x0A | LF | 换行 |
| \v | 013 | 11 | 0x0B | VT | 纵向制表符 |
| \f | 014 | 12 | 0x0C | FF | 换页 |
| \r | 015 | 13 | 0x0D | CR | 回车 |
| \e | 033 | 27 | 0x1B | ESC | 转义 |
| \" | 042 | 34 | 0x22 | " | 双引号 |
| \' | 047 | 39 | 0x27 | ' | 单引号 |
| \\ | 134 | 92 | 0x5C | \ | 反斜杠 |
| \000 | 八进制值(范围是000 到0177) | ||||
| \xXX | x 打头的十六进制值(范围是0x00 到0xFF) | ||||
| \ | 连字符,将本行和下一行的内容连接起来. | ||||
控制字符的一个作用是用做字符串里面的定界符,在数据库或者web 应用中,大多数的可打印字符都是被允许用在数据项里面的,就是说可打印的字符不适合做定界符。一个通常的解决方案是,使用那些不经常使用的,不可打印的ASCII 码值来作为定界符,它们是非常完美的定界符,这样一来诸如冒号这样的可打印字符就可以解脱出来用在数据项中了。
Python 的三引号允许一个字符串跨多行,字符串中可以包含换行符、制表符以及其他特殊字符。三引号的语法是一对连续的单引号或者双引号(通常都是成对的用)。
8.Unicode
| Unicode 术语 | |
| 名词 | 意思 |
| ASCII | 美国标准信息交换码 |
| BMP | 基本多文种平面(第零平面) |
| BOM | 字节顺序标记(标识字节顺序的字符) |
| CJK/CJKV | 中文-日文-韩文(和越南语)的缩写 |
| Code point | 类似于ASCII 值,代表Unicode 字符的值,范围在range(1114112)或者说0x000000 到0x10FFFF. |
| Octet | 八位二进制数的位组 |
| UCS | 通用字符集 |
| UCS2 | UCS 的双字节编码方式(见UTF-16) |
| UCS4 | UCS 的四字节编码方式. |
| UTF | Unicode 或者UCS 的转换格式. |
| UTF-8 | 八位UTF 转换格式(无符号字节序列, 长度为一到四个字节) |
| UTF-16 | 16 位UTF 转换格式(无符号字节序列,通常是16 位长[两个字节],见UCS2) |
在Unicode 之前,用的都是ASCII,ASCII 码非常简单,每个英文字符都是以七位二进制数的方式存贮在计算机内,其范围是32 到126。内建的str()函数和chr()函数并没有升级成可以处理Unicode。它们只能处理常规的ASCII 编码字符串,如果一个Unicode 字符串被作作为参数传给了str()函数,它会首先被转换成ASCII 字符串然后在交给str()函数。新的内建函数unicode()和unichar()可以看成Unicode 版本的str()和chr().Unicode()函数可以把任何Python 的数据类型转换成一个Unicode 字符串,如果是对象,并且该对象定义了__unicode__()方法,它还可以把该对象转换成相应的Unicode 字符串。
codec 是COder/DECoder 的首字母组合,它定义了文本跟二进制值的转换方式。
只要你遵守以下的规则,处理Unicode 就是这么简单:
? 程序中出现字符串时一定要加个前缀 u.
? 不要用 str()函数,用unicode()代替.
? 不要用过时的 string 模块 -- 如果传给它的是非ASCII 字符,它会把一切搞砸。
? 不到必须时不要在你的程序里面编解码 Unicod 字符。只在你要写入文件或数据库或者网络时,才调用encode()函数;相应地,只在你需要把数据读回来的时候才调用decode()函数。
Python 标准库里面的绝大部分模块都是兼容Unicode 的.除了pickle 模块!pickle 模块只支持ASCII 字符串。
为了支持Unicode,你必须确保以下方面对Unicode 的支持:
? 数据库服务器(MySQL,PostgreSQL,SQL Server,等等)
? 数据库适配器(MySQLdb 等等)
? Web 开发框架(mod_python,cgi,Zope,Plane,Django 等等)
例如:说MySQLdb,它并不是默认就支持Unicode 模式,你必须在connect()方法里面用一个特殊的关键字use_unicode来确保你得到的查询结果是Unicode 字符串。mod_python 里面开启对Unicode 的支持相当简单,只要在request 对象里面把text-encoding 一项设成"utf-8"就行了,剩下的mod_python 都会替你完成,Zope 等其他复杂的系统可能需要更多的工作来支持Unicode。
现实教训总结:使应用程序完全支持Unicode,兼容其他的语言本身就是一个工程。
Python 的 Unicode支持:
内建函数unicode()函数,它接受一个string 做参数,返回一个Unicode 字符串;
内建的decode()/encode()方法,decode()和encode()内建函数接受一个字符串做参数返回该字符串对应的解码后/编码后的字符串。decode()和encode()都可以应用于常规字符串和Unicode 字符串。decode()方法是在Python2.2 以后加入的;
Unicode 类型,Unicode 字符串对象是basestring 的子类、用Unicode()工厂方法或直接在字符串前面加一个u 或者U 来创建实例。支持Unicode 原始字符串,只要在你的字符串前面加一个ur 或者UR就可以了;
强制类型转换,混合类型字符串操作需要把普通字符串转换成Unicode 对象;
异常,UnicodeError 异常是在exceptions 模块中定义的,ValueError 的子类.所有关于Unicode编解码的异常都要继承自UnicodeError。
| 常用Unicode 编辑码 | |
| 编码 | 描述 |
| utf-8 | 变量长度为8 的编码(默认编码) |
| utf-16 | 变量长度为16 的编码(大/小端) |
| utf-16-le | 小端UTF-16 编码 |
| utf-16-be | 大端UTF-16 编码 |
| ascii | 7-bit 7 位ASCII 码表 |
| iso-8859-1 | ISO 8859-1 (Latin-1) 码表 |
| unicode-escape | (定义见Python Unicode 构造函数) |
| raw-unicode-escape | (定义见Python Unicode 构造函数) |
| native | Python 用的内部格式 |
字符串格式化操作符:对于Python 的格式化字符串的操作符,%s 把Python 字符串中的Unicode 对象执行了str(u)操作,所以,输出的应该是u.encode(默认编码)。如果格式化字符串是Unicode 对象,所有的参数都将首先强制转换成Unicode 然后根据对应的格式串一起进行格式转换。数字首先被转换成普通字符串, 然后在转换成Unicode。Python 字符串通过默认编码格式转化成Unicode。Unicode 对象不变,所有其他格式字符串都需要像上面这样转化,如u"%s %s" % (u"abc", "abc") u"abc abc"。
9.相关模块
| 与字符串类型有关的模块 | |
| 模块 | 描述 |
| string | 字符串操作相关函数和工具,比如Template 类. |
| re | 正则表达式:强大的字符串模式匹配模块 |
| struct | 字符串和二进制之间的转换 |
| c/StringIO | 字符串缓冲对象,操作方法类似于file 对象. |
| base64 | Base 16,32,64 数据编解码 |
| codecs | 解码器注册和基类 |
| crypt | 进行单方面加密 |
| difflib | 找出序列间的不同 |
| hashlib | 多种不同安全哈希算法和信息摘要算法的API |
| hma | HMAC 信息鉴权算法的Python 实现 |
| md5 | RSA 的MD5 信息摘要鉴权 |
| rotor | 提供多平台的加解密服务 |
| sha | NIAT 的安全哈希算法SHA |
| stringprep | 提供用于IP 协议的Unicode 字符串 |
| textwrap | 文本打包和填充 |
| unicodedata | Unicode 数据库 |
核心模块: re
正则表达式(RE)提供了高级的字符串模式匹配方案。通过描述这些模式的语法,你可以像使用“过滤器”一样高效地查找传进来的文本。这些过滤器允许你基于自定义的模式字符串抽取匹配模式、执行查找-替换或分割字符串。该模块中包含的关键函数有:compile() - 将一个RE 表达式编译成一个可重用的RE 对象;match() - 试图从字符串的开始匹配一个模式;search() - 找出字符串中所有匹配的项,sub() - 进行查找替换操作。其中的一些函数返回匹配到的对象,你可以通过组匹配来访问(如果找到的话)。
10.字符串关键点总结
可以把字符串看成是Python 的一种数据类型,在Python 单引号或者双引号之间的字符数组或者是连续的字符集合.在Python 中最常用两个引号是单引号(')和双引号(")。字符串的实际内容是这些单引号(')或者双引号(")之间的字符,不包括引号本身.可以用两种引号来创建字符串是很有益处的,因为是当你的字符串中包含单引号时,如果用单引号创建字符串,那么字符串中的双引号就不需要转义。反之亦然.
字符串是字符存储操作的最基本单位,字符应该视为长度为1 的字符串。字符串格式化操作符 ( % )提供类似于printf()那样的功能。
三引号字符串是用两边各三个单引号(''')或者两边各三个双引号(""")来定义的。
11.列表
列表不仅可以包含Python 的标准类型,而且可以用用户定义的对象作为自己的元素.列表可以包含不同类型的对象,而且要比C 或者Python 自己的数组类型(包含在array 扩展包中)都要灵活.因为数组类型所有的元素只能是一种类型.列表可以执行pop,empt,sort,reverse 等操作.列表也可以添加或者减少元素.还可以跟其他的列表结合或者把一个列表分成几个.可以对单独一个元素或者多个元素执行insert,update,或者remove 操作.
创建一个列表就像给一个变量赋值一样的简单.你手工写一个列表(空的或者有值的都行)然后赋给一个变量,列表是由方括号([])来定义的,当然,你也可以用工厂方法来创建它。列表的切片操作就像字符串中一样;切片操作符([])和索引值或索引值范围一起使用;可以通过在等号的左边指定一个索引或者索引范围的方式来更新一个或几个元素,你也可以用append()方法来追加元素到列表中去;要删除列表中的元素,如果你确切的知道要删除元素的索引可以用del 语句,否则可以用remove(列表元素)方法;还可以通过pop()方法来删除并从列表中返回一个特定对象。若删除一整个列表,你可以用del 语句:del 列表名。
12.操作符
比较列表时也是用的内建的cmp()函数,基本的比较逻辑是这样的:两个列表的元素分别比较,直到有一方的元素胜出。列表的切片操作也遵从正负索引规则,也有开始索引值,结束索引值,如果这两个值为空,默认也会分别指到序列的开始和结束位置。
如果你想以子列表的形式得到一个列表中的一个切片,那需要确保在赋值时等号的左边也是一个列表而不是一个列表的元素。
连接操作符允许我们把多个列表对象合并在一起.注意,列表类型的连接操作也只能在同类型之间进行,换句话说,你不能把两个不同类型的对象连接在一起,即便他们都是序列类型也不行。
从Python1.5.2 起,我们可以用extend()方法来代替连接操作符把一个列表的内容添加到另一个中去.使用extend()方法比连接操作的一个优点是它实际上是把新列表添加到了原有的列表里面,而不是像连接操作那样新建一个列表。list.extend()方法也被用来做复合赋值运算,也就是Python2.0 中添加的替换连接操作(+=)。
13.内建函数
对两个列表的元素进行比较:
1. 如果比较的元素是同类型的,则比较其值,返回结果。
2. 如果两个元素不是同一种类型,则检查它们是否是数字。
a. 如果是数字,执行必要的数字强制类型转换,然后比较。
b. 如果有一方的元素是数字,则另一方的元素"大"(数字是"最小的")
c. 否则,通过类型名字的字母顺序进行比较。
3. 如果有一个列表首先到达末尾,则另一个长一点的列表"大"。
4. 如果我们用尽了两个列表的元素而且所有元素都是相等的,那么结果就是个平局,就是说返回一个0。
对字符串来说len()返回字符串的长度,就是字符串包含的字符个数。对列表或者元组来说,它会像你想像的那样返回列表或者元组的元素个数,容器里面的每个对象被作为一个项来处理。
max()和min()函数在字符串操作里面用处不大,因为它们能对字符串做的只能是找出字符串中"最大"和"最小"的字符(按词典序),而对列表和元组来说,它们被定义了更多的用处.比如对只包含数字和字符串对象的列表,max()和min()函数就非常有用,重申一遍,混合对象的结构越复杂返回的结构准确性就越差.然而,在有些情况下(虽然很少),这样的操作可以返回你需要的结果。
sorted() and reversed(),初学者使用字符串,应该注意是如何把单引号和双引号的使用矛盾和谐掉.同时还要注意字符串排序使用的是字典序,而不是字母序(字母'T'的ASCII 码值要比字母'a'的还要靠前)。
enumerate() and zip(),sum()
list() and tuple(),list()函数和tuple()函数接受可迭代对象(比如另一个序列)作为参数,并通过浅拷贝数据来创建一个新的列表或者元组.虽然字符串也是序列类型的,但是它们并不是经常用于list()和tuple(). 更多的情况下,它们用于在两种类型之间进行转换,比如你需要把一个已有的元组转成列表类型的(然后你就可以修改它的元素了),或者相反。
如果你不考虑range()函数的话,Python 中没有特定用于列表的内建函数.range()函数接受一个数值作为输入,输出一个符合标准的列表.
14.列表类型的内建函数
用点号的方式访问对象的属性:object.attribute.列表的方法也是这样:list.method().我们用点号来访问一个对象的属性(在这里是一个函数),然后用函数操作符( () )来调用这个方法。可以在一个列表对象上应用dir()方法来得到它所有的方法和属性。
| 列表类型内建函数 | |
| List Method | Operation |
| list.append(obj) | 向列表中添加一个对象obj |
| list.count(obj) | 返回一个对象obj 在列表中出现的次数 |
| list.extend(seq) | 把序列seq 的内容添加到列表中 |
| list.index(obj,i=0,j=len(list)) | 返回list[k] == obj 的k 值,并且k 的范围在 i<=k |
| list.insert(index,obj) | 在索引量为index 的位置插入对象obj. |
| list.pop(index=-1) | 删除并返回指定位置的对象,默认是最后一个对象 |
| list.remove(obj) | 从列表中删除对象obj |
| list.reverse() | 原地翻转列表 |
| list.sort(func=None,key=None,reverse=False) | 以指定的方式排序列表中的成员,如果func 和key 参数指定, |
核心笔记:那些可以改变对象值的可变对象的方法是没有返回值的!
15.列表的特殊特性
堆栈:堆栈是一个后进先出(LIFO)的数据结构。
队列:队列是一种先进先出(FIFO)的数据类型,它的工作原理类似于超市中排队交钱或者银行里面的排队,队列里的第一个人首先接受服务(满心想第一个出去).新的元素通过"入队"的方式添加进队列的末尾,"出队"就是从队列的头部删除.
16.元组
实际上元组是跟列表非常相近的另一种容器类型.元组和列表看起来不同的一点是元组用的是圆括号而列表用的是方括号。而功能上,元组和列表相比有一个很重要的区别,元组是一种不可变类型.另外当处理一组对象时,这个组默认是元组类型.
创建一个元组并给他赋值实际上跟创建一个列表并给它赋值完全一样,除了一点,只有一个元素的元组需要在元组分割符里面加一个逗号(,)用以防止跟普通的分组操作符混淆.不要忘了它是一个工厂方法!元组的切片操作跟列表一样,用方括号作为切片操符([]),里面写上索引值或者索引范围.跟数字和字符串一样,元组也是不可变类型,就是说你不能更新或者改变元组的元素,通过现有字符串的片段再构造一个新字符串的方式解决的,对元组同样需要这样.
删除一个单独的元组元素是不可能的,当然,把不需要的元素丢弃后, 重新组成一个元组是没有问题的.要显示地删除一整个元组,只要用del 语句减少对象引用计数.当这个引用计数达到0 的时候,该对象就会被析构.记住,大多数时候,我们不需要显式的用del 删除一个对象,一出它的作用域它就会被析构,Python 编程里面用到显式删除元组的情况非常之少.del aTuple
17.元组操作符和内建函数
元组的对象和序列类型操作符还有内建函数跟列表的完全一样.你仍然可以对元组进行切片操作,合并操作,以及多次拷贝一个元组,还可以检查一个对象是否属于一个元组,进行元组之间的比较等.
18.元组的特殊特性
因为元组是容器对象,很多时候你想改变的只是这个容器中的一个或者多个元素,不幸的是这是不可能的,切片操作符不能用作左值进行赋值。这和字符串没什么不同,切片操作只能用于只读的操作。如果我们操作从一个函数返回的元组,可以通过内建list()函数把它转换成一个列表.虽然元组对象本身是不可变的,但这并不意味着元组包含的可变对象也不可变了。
元组可以使用连接操作、重复操作,所有的多对象的,逗号分隔的,没有明确用符号定义的,比如说像用方括号表示列表和用圆括号表示元组一样,等等这些集合默认的类型都是元组。所有函数返回的多对象(不包括有符号封装的)都是元组类型。注意,有符号封装的多对象集合其实是返回的一个单一的容器对象。
创建一个只有一个元素的元组?在元组上试验,你都不能得到想要的结果。因为圆括号被重载了,它也被用作分组操作符。由圆括号包裹的一个单一元素首先被作为分组操作,而不是作为元组的分界符。一个变通的方法是在第一个元素后面添一个逗号(,)来表明这是一个元组而不是在做分组操作.
核心笔记:列表 VS 元组,最好使用不可变类型变量的一个情况是,如果你在维护一些敏感的数据,并且需要把这些数据传递给一个并不了解的函数(或许是一个根本不是你写的API),作为一个只负责一个软件某一部分的工程师,如果你确信你的数据不会被调用的函数篡改,你会觉得安全了许多。一个需要可变类型参数的例子是,如果你在管理动态数据集合时。你需要先把它们创建出来,逐渐地或者不定期的添加它们,或者有时还要移除一些单个的元素。这是一个必须使用可变类型对象的典型例子。幸运的是,通过内建的list()和tuple()转换函数,你可以非常轻松的在两者之间进行转换.list()和tuple()函数允许你用一个列表来创建一个元组,反之亦然.如果你有一个元组变量,但你需要一个列表变量因为你要更新一下它的对象,这时list()函数就是你最好的帮手.如果你有一个列表变量,并且想把它传递给一个函数,或许一个API,而你又不想让任何人弄乱你的数据,这时tuple()函数就非常有用。
19.相关模块
| 与序列类型相关的模块 | |
| 模块 | 内容 |
| 数组 | 一种受限制的可变序列类型,要求所有的元素必须都是相同的类型。 |
| copy | 提供浅拷贝和深拷贝的能力 |
| operator | 包含函数调用形式的序列操作符,比如operator.concat(m,n)就相当于连接操作(m+n)。 |
| re | Perl 风格的正则表达式查找(和匹配) |
| StringIO/cStringIO |
把长字符串作为文件来操作,比如read(),seek()函数等,C 版的更快一些,但是它不能被继承. |
| Textwrap | 用作包裹/填充文本的函数,也有一个类 |
| types | 包含Python 支持的所有类型 |
| collections | 高性能容器数据类型 |
operator 模块除了提供与数字操作符相同的功能外,还提供了与序列类型操作符相同的功能.types 模块是代表python 支持的全部类型的type 对象的引用。最后,UserList 模块包含了list 对象的完全的类实现。因为Python 类型不能作为子类,所以这个模块允许用户获得类似list 的类,也可以派生出新的类或功能。
20.拷贝Python对象(浅拷贝和深拷贝)
浅拷贝:对一个对象进行浅拷贝其实是新创建了一个类型跟原对象一样,其内容是原来对象元素的引用,换句话说,这个拷贝的对象本身是新的,但是它的内容不是.
深拷贝:创建一个新的容器对象,包含原有对象元素(引用)全新拷贝的引用--需要copy.deepcopy()函数(需先导入copy模块)。
序列类型对象的浅拷贝是默认类型拷贝,并可以以下几种方式实施:
(1)完全切片操作[:],
(2)利用工厂函数,比如list(),dict()等,
(3)使用copy 模块的copy 函数.
拷贝操作的警告:第一,非容器类型(比如数字,字符串和其他"原子"类型的对象,像代码,类型和xrange 对象等)没有被拷贝一说,浅拷贝是用完全切片操作来完成的.第二,如果元组变量只包含原子类型对象,对它的深拷贝将不会进行.
核心模块: copy,浅拷贝和深拷贝操作都可以在copy 模块中找到.其实copy 模块中只有两个函数可用:copy()进行浅拷贝操作,而deepcopy()进行深拷贝操作.
21.序列类型小结