0x68.图论 - 二分图的匹配
目录
- 二分图应用的几个重要定理
- 二分图
- - 概述
- 一、二分图的判定
- 1.P1155 双栈排序(二分图的染色判断+链式前向星)
- 2.luogu P1525 关押罪犯(并查集/二分图判定+二分)
- 二、二分图的最大匹配
- 1.匈牙利算法
- 2.luogu P3386 【模板】二分图最大匹配
- 三、二分图的多重匹配
- 四、二分图的带权匹配
声明:
本系列博客是《算法竞赛进阶指南》+《算法竞赛入门经典》+《挑战程序设计竞赛》的学习笔记,主要是因为我三本都买了按照《算法竞赛进阶指南》的目录顺序学习,包含书中的少部分重要知识点、例题解题报告及我个人的学习心得和对该算法的补充拓展,仅用于学习交流和复习,无任何商业用途。博客中部分内容来源于书本和网络(我尽量减少书中引用),由我个人整理总结(习题和代码可全都是我自己敲哒)部分内容由我个人编写而成,如果想要有更好的学习体验或者希望学习到更全面的知识,请于京东搜索购买正版图书:《算法竞赛进阶指南》——作者李煜东,强烈安利,好书不火系列,谢谢配合。
下方链接为学习笔记目录链接(中转站)
学习笔记目录链接
ACM-ICPC在线模板
这篇写的有些水,主要是好多内容都可以用网络流解决而且网络流更优
二分图应用的几个重要定理
最大匹配数:最大匹配的匹配边的数目
最小点覆盖数:选取最少的点,使任意一条边至少有一个端点被选择
最大独立数:选取最多的点,使任意所选两点均不相连
最小路径覆盖数:对于一个 DAG(有向无环图),选取最少条路径,使得每个顶点属于且仅属于一条路径。路径长可以为 0(即单个点)。
定理1:最大匹配数 = 最小点覆盖数(这是 Konig 定理)
定理2:最大匹配数 = 最大独立数
定理3:最小路径覆盖数 = 顶点数 - 最大匹配数
二分图
- 概述
二分图又称作二部图,是图论中的一种特殊模型。设G=(V,E)是一个无向图,如果顶点V可分割为两个互不相交的子集(A,B),并且图中的每条边(i,j)所关联的两个顶点i和j分别属于这两个不同的顶点集(i in A,j in B),则称图G为一个二分图。
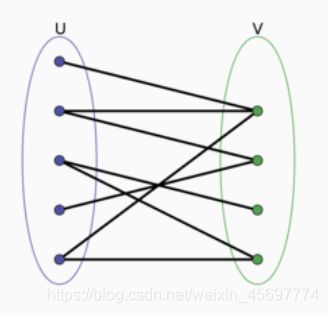
如上图就是一个标准的二分图
性质:
二分图不存在长度为奇数的环
一、二分图的判定
此题来源于《挑战程序设计竞赛》

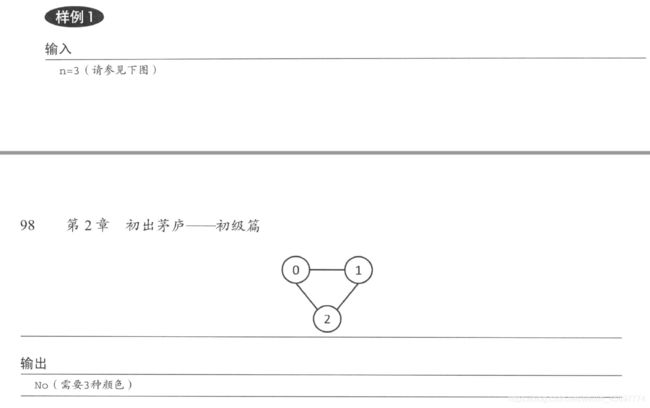

DFS
vector<int> G[MAX_V];//图的表示
int V;//顶点数
int color[MAX_V];//顶点i的颜色1或-1
//把顶点染成1或-1
bool dfs(int v,int c)
{
color[v]=c;//顶点v染成c
for (int i = 0; i < G[v].size(); ++i)
{
//相邻点同色,返回false
if(color[G[v][i]]==c)
return false;
//相邻点没有染色,就将其染色为-c,继续dfs,若最终仍为false,则返回false
if(color[G[v][i]]==0 && !dfs(G[v][i],-c))
return false;
}
//所有顶点染过色返回true
return true;
}
void solve()
{
//如果是连通图,则一次dfs即可访问所有位置
//但题目没有说明,故要依次检查各个顶点的情况
for (int i = 0; i < V; ++i)
{
if (color[i]==0)
{
//如果顶点还没有染色,染成1
if (!dfs(i,1))
{
cout<<"No"<<endl;
return;
}
}
}
cout<<"Yes"<<endl;
}
以及BFS
int n,m;
vector<int> g[MAXN];
int color[MAXN];
void init()
{
for(int i=0;i<n;i++){
g[i].clear();
color[i]=-1;
}
}
int bfs()
{
queue<int>q;
q.push(0);
color[0]=1;
while(!q.empty()){
int t = q.front();
q.pop();
for(int i=0;i<g[t].size();i++){
if(color[g[t][i]]==color[t])//相邻节点颜色相同,不是二分图
return 1;
else if(color[g[t][i]]==-1)//未染色
{
color[g[t][i]]=-color[t];
q.push(g[t][i]);
}
}
}
return 0;
}
1.P1155 双栈排序(二分图的染色判断+链式前向星)
P1155 双栈排序


P1155 双栈排序(二分图的染色判断+链式前向星)#
2.luogu P1525 关押罪犯(并查集/二分图判定+二分)
我哭了,以后遇见stl的各种返回值都先强转int再说
for (int i = 0; i <= (int)e[x].size()-1; i++) {
不然是真的找不到bug
#include二、二分图的最大匹配
1.匈牙利算法
时间复杂度为 O ( N M ) O(NM) O(NM) 。
算法步骤大致如下:
首先从任意一个未配对的点u开始,选择他的任意一条边( u - v ),如此时 还未配对,则配对成功,配对数加一,若 v 已经配对,则尝试寻找 v 的配对的另一个配对(该步骤可能会被递归的被执行多次),若该尝试成功,则配对成功,配对数加一。
若上一步配对不成功,那么重新选择一条未被选择过的边,重复上一步,直到点 的所有的边都被选择过为止。
对剩下每一个没有被配对的点执行步骤 1,直到所有的点都尝试完毕。

可以发现,当尝试对节点 3 进行匹配时,走过了一条路径(3-4-1-5-2-6),最后找到了新的匹配方案,我们把这样的道路叫做 增广路 ,其本质是一条起点和终点都是未匹配节点的路径。
匈牙利算法执行的过程也可以看作是不断寻找增广路的过程,当在当前匹配方案下再也找不到增广路,那么当前匹配方案便是最大匹配了。
2.luogu P3386 【模板】二分图最大匹配
P3386 【模板】二分图最大匹配
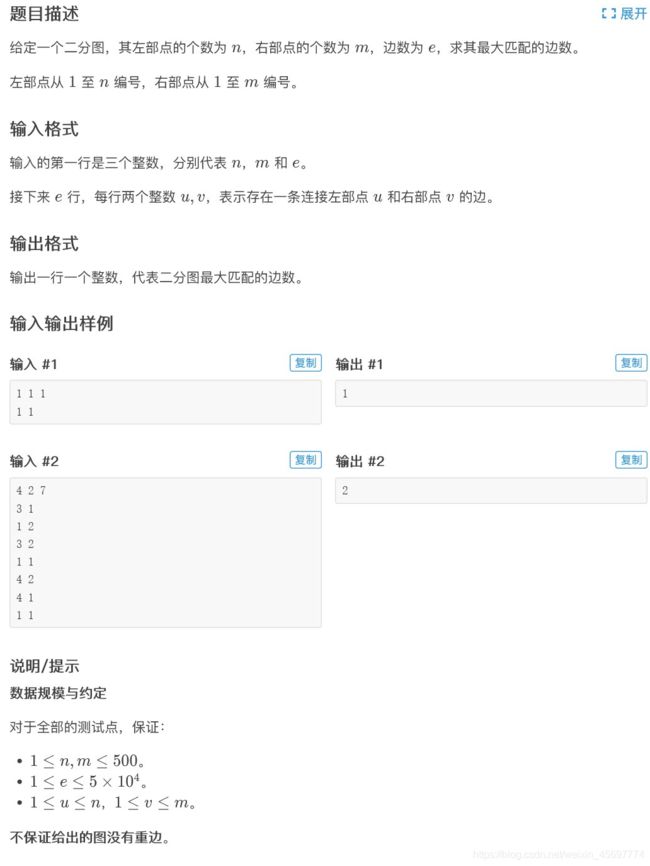
#include三、二分图的多重匹配
在二分图最大匹配中,每个点(不管是X方点还是Y方点)最多只能和一条匹配边相关联,然而,我们经常遇到这种问题,即二分图匹配中一个点可以和多条匹配边相关联,但有上限,或者说,Li表示点i最多可以和多少条匹配边相关联。
二分图多重匹配分为二分图多重最大匹配与二分图多重最优匹配两种,分别可以用最大流与最大费用最大流解决。
(1)二分图多重最大匹配:
在原图上建立源点S和汇点T,S向每个X方点连一条容量为该X方点L值的边,每个Y方点向T连一条容量为该Y方点L值的边,原来二分图中各边在新的网络中仍存在,容量为1(若该边可以使用多次则容量大于1),求该网络的最大流,就是该二分图多重最大匹配的值。
(2)二分图多重最优匹配:
在原图上建立源点S和汇点T,S向每个X方点连一条容量为该X方点L值、费用为0的边,每个Y方点向T连一条容量为该Y方点L值、费用为0的边,原来二分图中各边在新的网络中仍存在,容量为1(若该边可以使用多次则容量大于1),费用为该边的权值。求该网络的最大费用最大流,就是该二分图多重最优匹配的值。
四、二分图的带权匹配
设 G 为带边权的二分图,寻找 G 边权和最大的最大匹配称为最大权匹配问题。
首先要保证是最大匹配,然后再找最大边权。
有两种解法:费用流和KM算法。
我选择费用流。
然后就KM懒得写(学)了。