算法设计与分析:动态规划(2) - 序列联配问题(最优对齐方案)
文章目录
- 前言
- 序列联配问题
- 问题描述与分析
- 解决思路
- 问题的最优是否最好?
- 总结
本文参考UCAS卜东波老师算法设计与分析课程撰写
前言
本文依然围绕动态规划问题展开,会详细描述动态规划在序列联配问题中的应用,通过这个问题引出高级动态规划,以及以算代存的方式减少动态规划占用的内存。
序列联配问题
问题描述与分析
-
给你两个字符串序列 x = x 1 x 2 . . . x n x = x_1x_2...x_n x=x1x2...xn, y = y 1 y 2 . . . y n y = y_1y_2...y_n y=y1y2...yn,计算联配 ( x ′ , y ′ ) (x',y') (x′,y′),使得编辑操作数目 s ( x ′ , y ′ ) s(x',y') s(x′,y′)最小
首先解读一下问题,想象这样一个场景,我们拥有一个字典词库,对于用户输入的单词S(可能输错),我们需要尽快地找到词库中与它最像的单词(动态规划保证这一过程尽可能快),修正用户的输入。为此我们引入“对齐”的概念。拿到两个字符串T&S,我们对字符串每个对应位置的元素做以下判断:
- S ′ [ i ] S'[i] S′[i]=’-’: S [ i ] S[i] S[i]相比于 T [ i ] T[i] T[i] 少了一个字母,称作删除
- T ′ [ i ] T'[i] T′[i]= ‘-’: S ′ [ i ] S'[i] S′[i]相比于 T [ i ] T[i] T[i]多了一个字母,称作插入
- S [ i ] S[i] S[i]与 T [ i ] T[i] T[i]位置元素相同,称作匹配
简而言之,就是给了 ( S , T ) (S,T) (S,T)要转换到 ( S ′ , T ′ ) (S',T') (S′,T′),使得 ( S ′ , T ′ ) (S',T') (S′,T′)是对齐的。这里给出一个例子,给定 S = O C U R R A N C E S=OCURRANCE S=OCURRANCE, T = O C C U R R E N C E T=OCCURRENCE T=OCCURRENCE,则一种对齐操作如下:
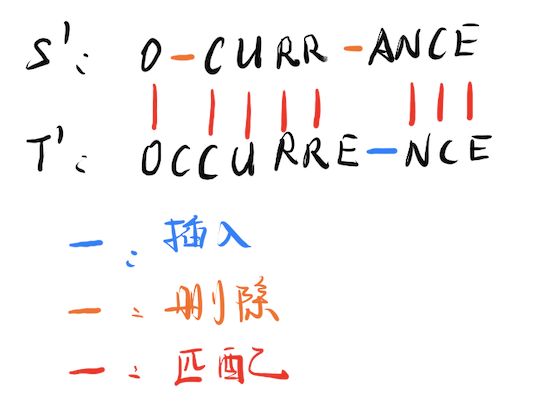
有了对齐的概念,我们就可以计算两个字符串之间的相似度(如果对齐需要的操作越少,理论相似度越高),作出如下定义:
s ( T ′ , S ′ ) = ∑ i = 1 ∣ S ∣ s ( T ′ [ i ] , S ′ [ i ] ) s ( T ′ [ i ] , S ′ [ i ] ) = { + 1 if T ′ [ i ] = S ′ [ i ] − 1 if T ′ [ i ] ≠ S ′ [ i ] − 3 else s(T',S') = \sum_{i=1}^{|S|}s(T'[i],S'[i])\\ s(T'[i],S'[i]) = \begin{cases} +1 &\text{if } T'[i] =S'[i] \\ -1 &\text{if } T'[i] \ne S'[i] \\ -3 &\text{else } \end{cases} s(T′,S′)=i=1∑∣S∣s(T′[i],S′[i])s(T′[i],S′[i])=⎩⎪⎨⎪⎧+1−1−3if T′[i]=S′[i]if T′[i]=S′[i]else s ( T ′ , S ′ ) s(T',S') s(T′,S′)表示T’,S’字符串是字符串间相似度(也可以理解为对齐所需成本), s ( T ′ [ i ] , S ′ [ i ] ) s(T'[i],S'[i]) s(T′[i],S′[i])则是对单个字符对齐的成本,例如 s ( ′ C ′ , ‘ C ’ ) = 1 s('C',‘C’) = 1 s(′C′,‘C’)=1, s ( ′ C ′ , ′ A ′ ) = − 1 s('C','A') = -1 s(′C′,′A′)=−1, s ( ′ C ′ , ′ − ′ ) = − 3 s('C','-') = -3 s(′C′,′−′)=−3,这里的分数是认为规定的,一般性我们认为两个字符如果匹配上了应该加分,如果匹配不上应该扣分,但是如果是遗漏字符或者多余了字符,这种严重性我们认为比输错字符更大,所以这里暂时规定分别为+1,-1,-3
有了上面的定义之后,我们就可以计算两个字符串之间的相似度,下面是两种情况需要考虑:
-
对于同一个单词不同对齐方式相似度
同样是一个单词,如果采用不同的对齐方式,就会导致相似度不一样,如上文的例子中和下面展示的都是OCCURRENCE对齐的一种方式,然而依据定义计算两者与用户输入的相似度却不一样,如下:- 对齐方式1

- 对齐方式2

有了这种比较方式,我们就可以得到同一单词其针对用户输入的最好对齐方式
- 对齐方式1
-
对于两个不同单词对比相似度
当我们获取到用户的输入OCURRANCE,词库里的两个单词OCCURRENCE,OCCUPATION,我们想知道这两者哪个与输入相似度更高,计算如下(假设两个单词都采用了最好对齐):- T =
OCCURRENCE

- T =
OCCUPATION

可以发现,
OCCURRENCE的相似度更高,因此我们可以猜测用户的输入为OCCURRENCE - T =
上面两种方法实际上定义了一个定量的权衡字符串相似度的标准,同时将原问题转化为,有那么多的对齐方案,我该如何找出最优的对齐方案(即使得 s ( T ′ , S ′ ) s(T',S') s(T′,S′)分数最高)。
解决思路
根据上面的分析,可以发现这也是一个优化问题,我们描述S是如何从T产生。将上述问题转换成多步决策:S的一个字母如何从T产生(一步)
对于S中的一个字母,它可能有以下三种情况(我们从后往前对比S,T):
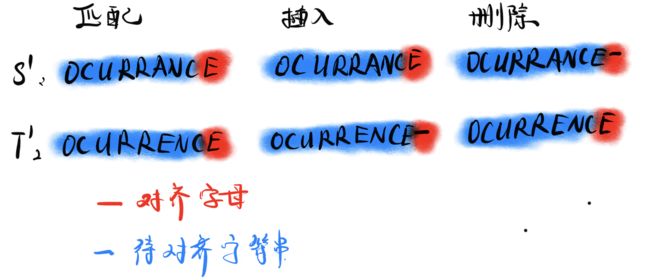
为了方便叙述,我们记最优的 S m S_m Sm与 T n T_n Tn对齐方案分数为 O P T ( m , n ) OPT(m,n) OPT(m,n),注意区别于上文的 s ( S ′ , T ′ ) s(S',T') s(S′,T′),前者是最优情况,后者是任意情况。注意不要被上图中匹配部分弄混,我们划分这三种情况的依据是,我们要看字母的对齐是否应该和对应字符串的当前字母对齐。简单来说,匹配时,E与E可以匹配,E与A也可以匹配,只不过一个结果是+1,一个结果是-1,而插入时,我们认为S中的E不应该在此时和T中字母对齐,而是和一个空格对齐,这种策略会导致得分-3,但是有可能这样子做剩下部分的对齐会非常完美,导致得分反而高了,删除的时候同理。
有了上面的讨论,我们就可以给出OPT的推导公式,如下:
O P T ( i , j ) = max { s ( T i , S j ) + O P T ( i − 1 , j − 1 ) s ( ′ − ′ , S j ) + O P T ( i , j − 1 ) s ( T i , ′ − ′ ) + O P T ( i − 1 , j ) OPT(i,j)= \max \begin{cases} s(T_i,S_j) +OPT(i-1,j-1)&\text{} \\ s('-',S_j) + OPT(i,j-1) &\text{} \\ s(T_i,'-')+OPT(i-1,j) \end{cases} OPT(i,j)=max⎩⎪⎨⎪⎧s(Ti,Sj)+OPT(i−1,j−1)s(′−′,Sj)+OPT(i,j−1)s(Ti,′−′)+OPT(i−1,j)
其中 s ( x , y ) s(x,y) s(x,y)在上文已经给出,如果遗忘,可以上翻回顾一下。
在设计伪代码之前,我们先做一张表来方便理解,这里直接沿用课件的图:
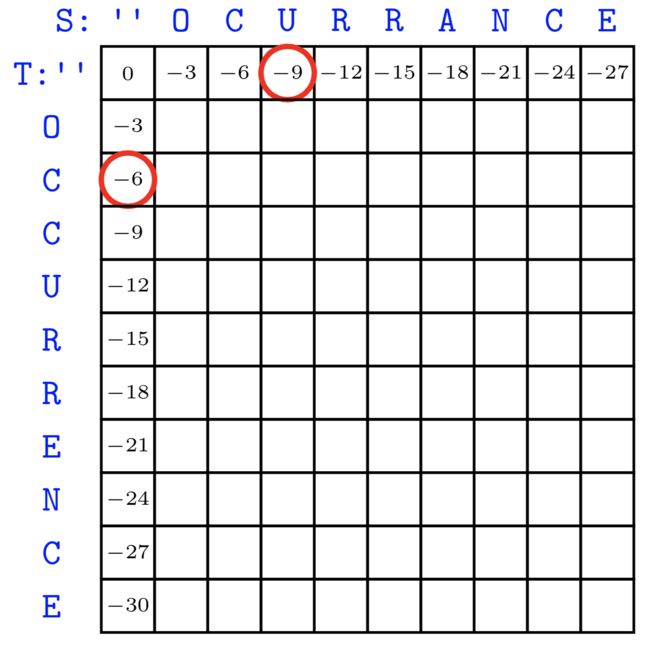
首先解释一下任一方格的意义,以红圈-9的位置为例,代表 O P T ( " " , " O C U " ) OPT("","OCU") OPT("","OCU"),即T为空,S为 O C U OCU OCU,这个值为什么为-9?因为T为空,S中每一个值只能和空格对齐,而和一次空格对齐就是-3,最终得分-9。对于其他的格子,如最右下角就是OPT(“OCCURRENCE”,“OCURRANCE”),我们可以清楚的计算第0行和第0列的元素,他们只能和空格对齐,因此都是-3的倍数。
有了这个基础,我们就能递归查询结果了。
如当我们求OPT(“OCCURRENCE”,“OCURRANCE”),它是 max { 1 + O P T ( " O C C U R R E N C " , " O C U R R A N C " − 3 + O P T ( " O C C U R R E N C " , " O C U R R A N C E " ) − 3 + O P T ( " O C C U R R E N C E " , " O C C U R R A N C " ) \max \begin{cases} 1+OPT("OCCURRENC","OCURRANC" \\ -3+OPT("OCCURRENC","OCURRANCE") \\ -3 + OPT("OCCURRENCE","OCCURRANC") \end{cases} max⎩⎪⎨⎪⎧1+OPT("OCCURRENC","OCURRANC"−3+OPT("OCCURRENC","OCURRANCE")−3+OPT("OCCURRENCE","OCCURRANC"),接着就可以不断递归下去(可以看出任意一个格子是由其做上角三个格子变化过来的),但实际上我们在前面将动态规划的时候还有另一种办法替换递归,就是迭代。
因此,我们可以设计得到伪代码如下:
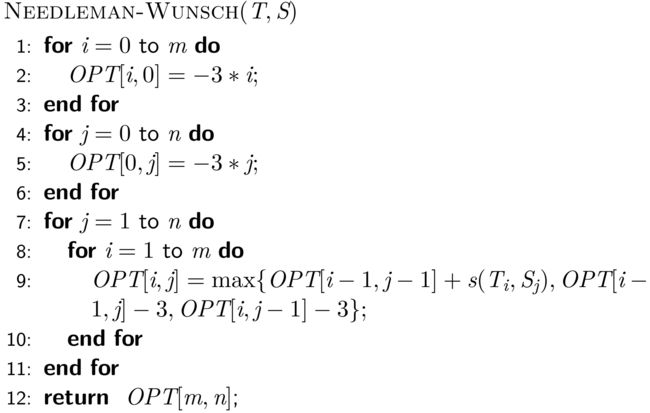
这个伪代码应该很好理解,前6行初始化DP数组0行0列,后面就是迭代递推的过程。下面是一个递推迭代得到的例子(来源课件):
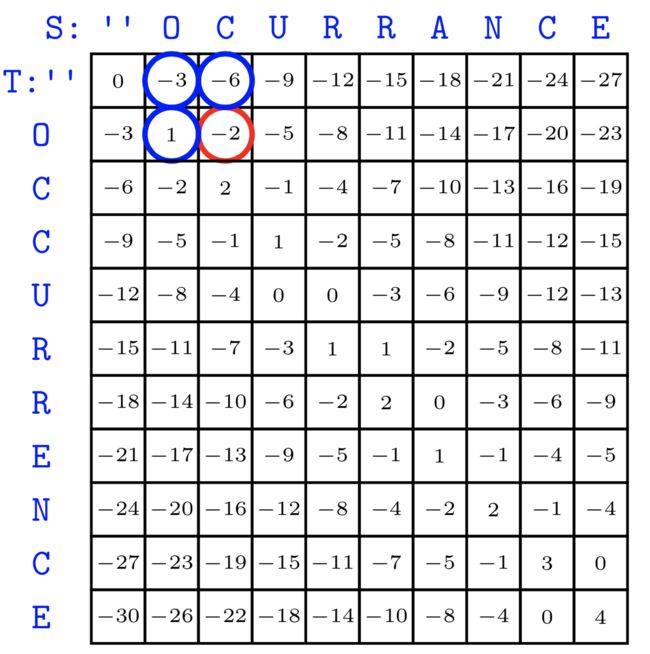
我们可以轻松获得最好的对齐分数是4。当然这并非是我们的重点,我们需要知道实际的对齐方案是怎么样的,换句话说,即从右下角到左上角的路径(这个路径告诉我们S’与T’是如何生成的)。
这个过程用回溯方法即可解决,我们从4开始考虑,它是左上角三个格子通过加上一个得分得到,那么我们也很容易通过让4扣除这个得分回到原来的格子,看其是否与格子实际分数相同,如果相同,则说明4是从该格子而来。下面是一个例子:
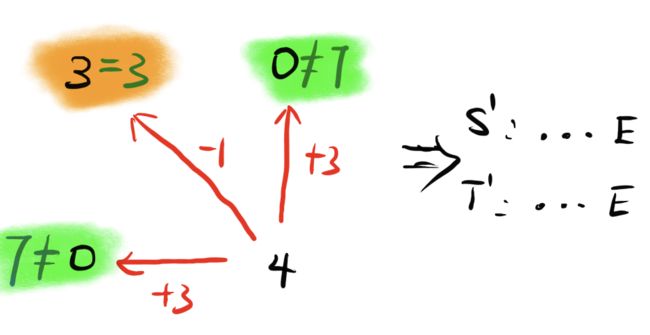
解释一下这个图,我们从4出发回溯到三个格子,斜对角-1是因为E与E相同,匹配得分+1,回溯回去就是-1,同样可知往上和往左走是+3(想想原因),而显然得到的结果中3是符合格子实际结果的,其余两个均不符合,因此可以断定4是由3这个格子来的。因此从后往前,S’与T‘均打印E字母。以此类推,下一个考虑的格子就是3。
至此,我们已经较为完善地解决了这个决策问题,当然这属于基本的动态规划思想,用一个动态数组存储当前最优情况,不断更新决策,在当前状态下找到下一步最优。
问题的最优是否最好?
老师在课上还指出了在实际应用中,我们不一定按照最优的方案回溯,我们依据分数给每个决策方向设定一个概率,依据概率随机进行回溯。这样找到的解不一定是最优解,但是一个不错(次优)的解。以考试为例,考100分的同学未必比考95的同学好,因为存在考题错误的情况。在一个有问题的打分方案下,寻找最优并没有意义。我们依据概率对回溯做多次决策进行聚类,聚类的中心则是最优的联配方案。
- 一个简单的例子
我们考虑表格中下面的结果:
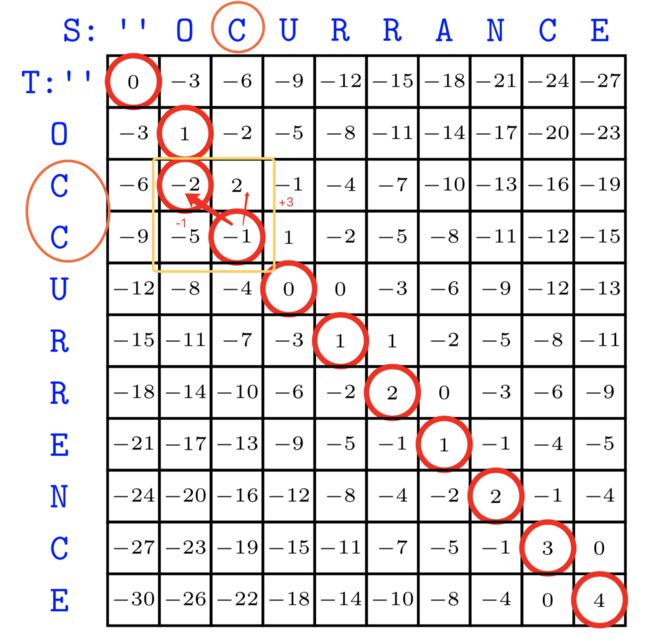
注意我黄色框出的部分,从-1回溯上去,我们发现斜着走和向上走都是可以的,体现在字符串上就是S中的C字母可以和T中“CC“第一个对齐,也可以和第二个对齐,两者分数是相同的,这种时候如果有概率选择,就可以帮助我们更好作出决策。更一般地,假设两个方向分差很小,一个是1.001,一个是1,这种时候分数高的优势就没有了,就要借助概率。
总结
本来后面还有一大部分高级动态规划的内容(讲述如何减少动态规划的空间复杂度),但是光写到这感觉内容已经很多了,因此我将其拆做两部分,后一部分在文末给出。这里先总结上面的内容:
- 1、对于动态规划中的序列联配问题,第一点先思考如何将其转换成一个多步决策问题。本文中采用将原问题将S与T对齐转换成S如何从T中得出,分别列举了三种可能情况,这三种情况的划分是依据S和T递归下标的变化得出的,同时-1(匹配),S-1(插入),T-1(删除)。
- 2、划分好依据后,你就有三种不同的决策方向,如何选择决策方向是动态规划的特点,它充分考虑了当前状态和转换到下一状态成本的整体结果,就像文中例子,可能OPT(i,j)从OPT(i-1,j)过来要耗费-3的成本,但是说不定OPT(i-1,j)本身就是一个很大的分数,这使得OPT(i,j)很好;而OPT(i,j)从OPT(i-1,j-1)过来可能只耗费-1的成本(甚至+1),但可能OPT(i-1,j-1)本身很差,导致OPT(i,j)很差,这是动态规划能够做到找到最优策略的原因。
- 3、剩下的部分就是如何初始化,和写好状态边界的问题了。
总体来说,核心就是构建多步决策
如果你觉得文章对你有用,不妨顺手点个赞哦~
- 上一篇:算法设计与分析:动态规划 - 矩阵链式相乘问题
- 下一篇:算法设计与分析:动态规划(3)-序列联配问题(以算代存)
- 目录