Tomcat7源码分析-Digester
最近研究了一段时间的Tomcat,还是有不少收获,首先对Digester做一个小的总结。
想必看过struts 和 tomcat 源码的童鞋对Digester都不会陌生,Digester是基于SAX解析将dom节点转换成java对象的一个可重用的组件。
下面是我对Digester在tomcat以及于它本身的一些理解!
1、Digester在tomcat中的作用?
解析server.xml,context.xml 和web.xml等xml,并实例化tomcat中各组件对象,建立各组件关联关系,并将配置在xml上信息注射到各组件对象中。
2、Digester在tomcat哪几个环节有用到?
(1)Catalina加载阶段,即该类的load方法中会调用到,对应解析xml为server.xml。
(2)StandardHost在启动的过程中,更新状态从而会触发其监听器HostConfig发布war,目录等,进而解析对应工程下面的context.xml,调用栈如下:

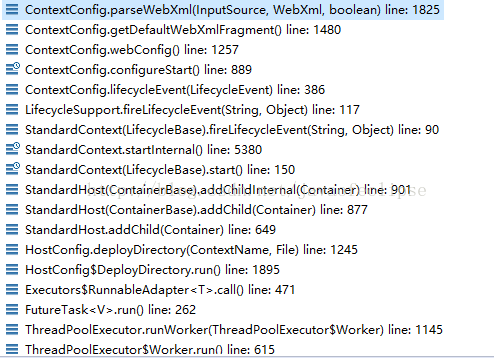
(3)StandardContext在启动的过程中,也会触发其监听器ContextConfig进而解析web.xml,调用栈如下:
3、类图结构

补充:org.apache.tomcat.util.digester.Digester父类为org.xml.sax.ext.DefaultHandler2,而DefaultHandler2又有一层父类DefaultHandler,而该类实现了多个接口,其中的一个接口为ContentHandler,Digester中其中两个重要的重写方法实则是来自于该接口定义的。
4、规则设置说明
(1)、
ObjectCreateRule规则:需指定pattern,类名信息,其中pattern是不能随便乱设置的,需和对应xml标签名一样,是有一定规则的,并且pattern相同的rule为一组规则,digester是按匹配到的一组规则依次对每个规则做处理的 很多规则处理逻辑都与digester栈中元素的位置相关,因此设置规则时,一组规则中的不同规则顺序也不是随意的,具体参考Catalina中的createStartDigester()方法即可知道,该规则的含义是初始化指定实例 。
(2)、SetPropertiesRule规则:设置规则时只需指定pattern即可,该规则的含义是会根据xml标签属性名去匹配该组规则定义的类中的属性,如果匹配成功,将xml标签属性值赋给该类实例对应的字段。
(3)、SetNextRule规则:设置规则时需指定pattern,方法名以及方法参数类型,参数类型往往是这组规则中定义的类实现的接口,该规则的功能往往是让父标签对应的实例调用指定的方法维护当前实例之间的关系。
其他规则在此就必一一列举了。
5、规则实现简要说明
读取流完毕后,
sax
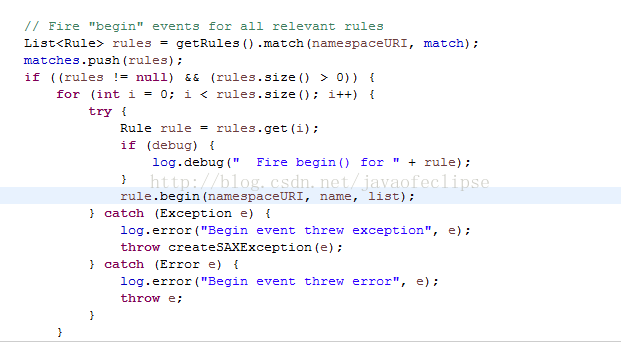
开始扫描dom节点,会根据是否是根节点做不同的逻辑,可通过方法调用栈可知。当解析开始标签时,则会回调Digester中的startElement方法,startElement方法会根据当前解析的标签名匹配一组规则,Digester中定义了一个matches的栈结构用于存放已匹配每组规则,在解析开始标签时则会把这组规则入栈,之后在依次执行这组规则中每个规则的begin方法,核心代码如下:
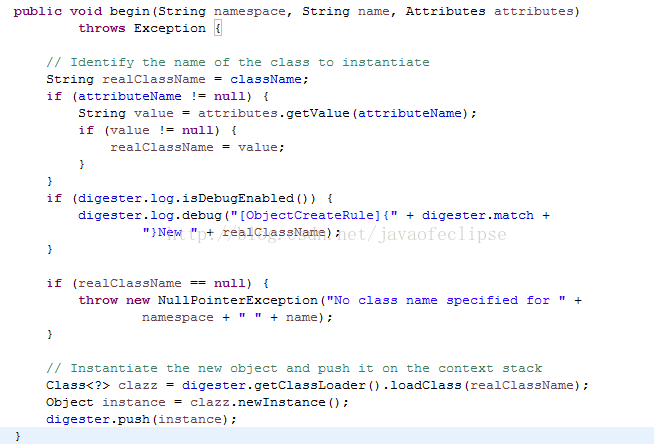
当规则是ObjectCreateRule时, 看指定的标签属性名在对应xml中有无设置值,有则取该值作为真正的类名,否则取在规则中设置的类名,并初始化该实例,Digester还维护了另外一个栈结构stack,用于存放对象实例的,因此还需将该实例压入到stack栈中,核心代码如下:
当规则是SetPropertiesRule时, 返回(不是弹出)Digester维护的栈stack中最顶层的对象,对标签属性名做一些逻辑检查,如该标签属性名代表的含义是类的话,则不往下进行, 检查符合条件后根则据set+标签属性名等逻辑和类中的方法名做匹配,匹配上了把标签属性值通过反射方式把值注射到对应属性上去。
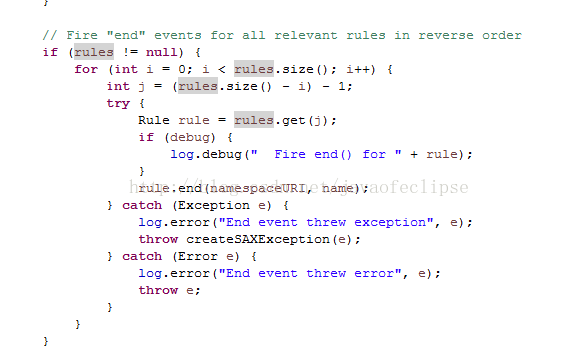
当规则是SetNextRule时,在解析开始标签时,该规则并没有真正做逻辑处理,该规则是没有重写父类中的begin方法的,而在解析结束标签时,则会回调Digester中的endElement方法,此时会弹出Digester维护的栈matches中最顶层的一组规则,倒序依次调用这组规则中的end方法,核心代码如下:
因此在解析结束标签时,最先调用的是SetNextRule中的end方法,在该方法中,首先从Digester维护好的栈stack返回最顶层两个对象,并根据指定规则中的设置方法反射调用该方法,从而维护这两个方法的关系,核心代码如下:
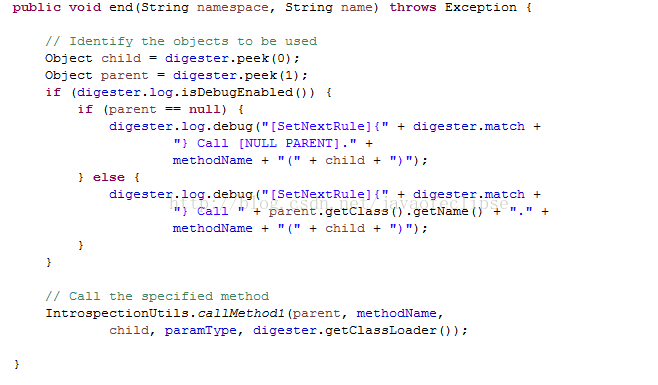
解析结束标签时,
SetPropertiesRule也没有做逻辑处理,该规则并没有重写父类中的end方法,规则ObjectCreateRule则是在结束时弹出Digester维护的栈stack中最顶层的对象,实则弹出该组规则中对应的对象。
在此,其他规则具体逻辑的就不在赘述了。
根据dom节点的特点,从上往下解析下来,通过反复的入栈出栈等操作最终实现了各个组件对象的实例化,赋值,与关系的建立。
6、what's more???
I think Digester运用了 解释器模式 的设计模式,定义了一个抽象的规则,具体规则的解释任务由子类完成,Digester本身则是一个上下文,为解释执行提供环境和存放一些全局信息,而客户角色则是Catalina和HostConfig等。 因此在解析一个新的xml时,只需要在客户端重新设置相应的规则并定义这些类,方法和属性即可,帮我们省掉了重复解析和注射的过程。