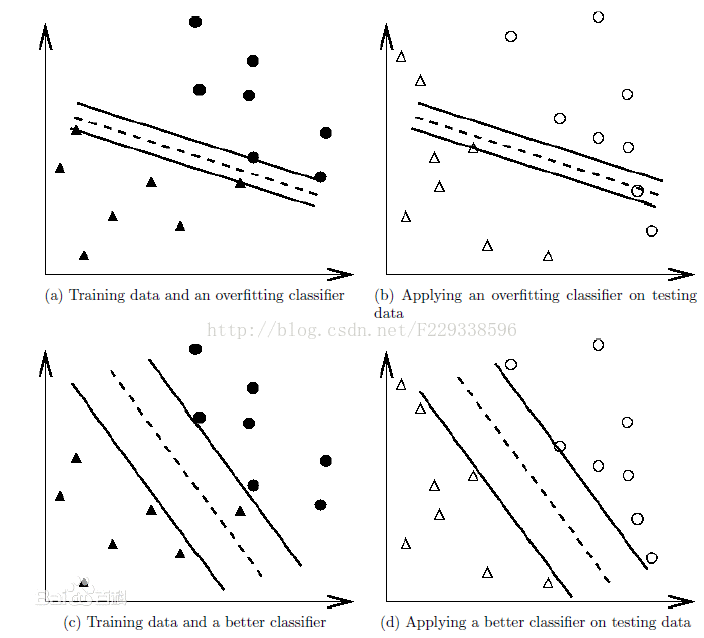
过度拟合
最近学习《机器学习》这门课程涉及到了Overfitting。上网查了一些资料,可以简单的理解了,所以就摘录下来。
为了得到一致假设而使假设变得过度复杂称为过拟合。想像某种学习算法产生了一个过拟合的分类器,这个分类器能够百分之百的正确分类样本数据(即再拿样本中的文档来给它,它绝对不会分错),但也就为了能够对样本完全正确的分类,使得它的构造如此精细复杂,规则如此严格,以至于任何与样本数据稍有不同的文档它全都认为不属于这个类别。
可以看出在a中虽然完全的拟合了样本数据,但对于b中的测试数据分类准确度很差。而c虽然没有完全拟合样本数据,但在d中对于测试数据的分类准确度却很高。过拟合问题往往是由于训练数据少等原因造成的。
由于刚接触理解不到位,就一并附上其他人的见解如下。
http://blog.csdn.net/fengzhe0411/article/details/7165549
http://blog.sina.com.cn/s/blog_6622f5c30101bt7n.html