我的NLP实践之旅05
我的NLP实践之旅05
不好意思,因为自己周五过生日的缘故,鸽了一次的博客,时间一去不复返,经过了周六和周日,转眼这次的NLP组队学习也接近尾声了,于是我乖乖的来补发博客了!
一、Word2Vec
这次的NLP组队学习Task05为深度学习组队时间,分为Word2Vec,TextCNN,和TextRNN三个部分,下面介绍一下Word2Vec
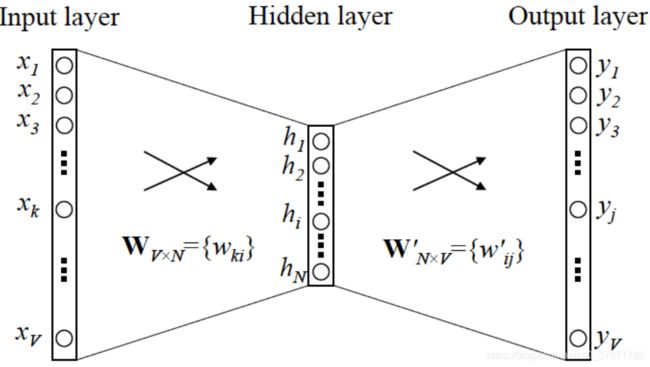
简单来说,Word2Vec实际上就是读单词的一次处理,通过神经网络的形式将单词转化为固定的维度,以此来达到增加特征以方便神经网络及其他模型训练的作用。
代码:
import logging
import random
import numpy as np
import torch
logging.basicConfig(level=logging.INFO, format='%(asctime)-15s %(levelname)s: %(message)s')
# set seed
seed = 666
random.seed(seed)
np.random.seed(seed)
torch.cuda.manual_seed(seed)
torch.manual_seed(seed)
logging.info('Start training...')
from gensim.models.word2vec import Word2Vec
num_features = 100 # Word vector dimensionality
num_workers = 8 # Number of threads to run in parallel
train_texts = list(map(lambda x: list(x.split()), train_texts))
model = Word2Vec(train_texts, workers=num_workers, size=num_features)
model.init_sims(replace=True)
# save model
model.save("./word2vec.bin")
# load model
model = Word2Vec.load("./word2vec.bin")
# convert format
model.wv.save_word2vec_format('./word2vec.txt', binary=False)
上述代码的作用为将文本中的每一个单词转化为100维的向量。其中,最后两行代码将训练好的Word2Vec模型进行了持久化!
二、TextCNN
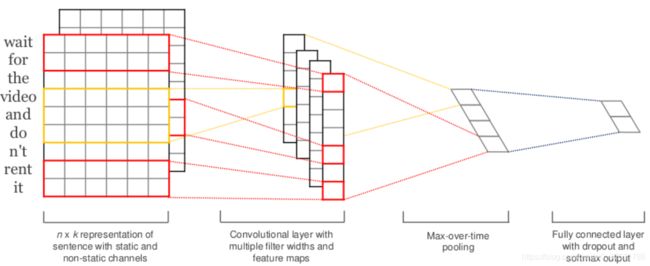
TextCNN的原理图如上图所示。在我们将单词向量通过Word2Vec的形式Embeding成相同维度后,我们通过自定义的卷积核对其进行卷积操作,以此来得到不同的输出,然后在将卷积层进行池化操作(可以理解为加和),最后对结果进行softMax处理得到分类结果,这就是运用TextCNN进行分类的基本原理。
代码:
import logging
import random
import numpy as np
import torch
logging.basicConfig(level=logging.INFO, format='%(asctime)-15s %(levelname)s: %(message)s')
# set seed
seed = 666
random.seed(seed)
np.random.seed(seed)
torch.cuda.manual_seed(seed)
torch.manual_seed(seed)
# set cuda
gpu = 0
use_cuda = gpu >= 0 and torch.cuda.is_available()
if use_cuda:
torch.cuda.set_device(gpu)
device = torch.device("cuda", gpu)
else:
device = torch.device("cpu")
logging.info("Use cuda: %s, gpu id: %d.", use_cuda, gpu)
# build model
class Model(nn.Module):
def __init__(self, vocab):
super(Model, self).__init__()
self.sent_rep_size = 300
self.doc_rep_size = sent_hidden_size * 2
self.all_parameters = {}
parameters = []
self.word_encoder = WordCNNEncoder(vocab)
parameters.extend(list(filter(lambda p: p.requires_grad, self.word_encoder.parameters())))
self.sent_encoder = SentEncoder(self.sent_rep_size)
self.sent_attention = Attention(self.doc_rep_size)
parameters.extend(list(filter(lambda p: p.requires_grad, self.sent_encoder.parameters())))
parameters.extend(list(filter(lambda p: p.requires_grad, self.sent_attention.parameters())))
self.out = nn.Linear(self.doc_rep_size, vocab.label_size, bias=True)
parameters.extend(list(filter(lambda p: p.requires_grad, self.out.parameters())))
if use_cuda:
self.to(device)
if len(parameters) > 0:
self.all_parameters["basic_parameters"] = parameters
logging.info('Build model with cnn word encoder, lstm sent encoder.')
para_num = sum([np.prod(list(p.size())) for p in self.parameters()])
logging.info('Model param num: %.2f M.' % (para_num / 1e6))
def forward(self, batch_inputs):
# batch_inputs(batch_inputs1, batch_inputs2): b x doc_len x sent_len
# batch_masks : b x doc_len x sent_len
batch_inputs1, batch_inputs2, batch_masks = batch_inputs
batch_size, max_doc_len, max_sent_len = batch_inputs1.shape[0], batch_inputs1.shape[1], batch_inputs1.shape[2]
batch_inputs1 = batch_inputs1.view(batch_size * max_doc_len, max_sent_len) # sen_num x sent_len
batch_inputs2 = batch_inputs2.view(batch_size * max_doc_len, max_sent_len) # sen_num x sent_len
batch_masks = batch_masks.view(batch_size * max_doc_len, max_sent_len) # sen_num x sent_len
sent_reps = self.word_encoder(batch_inputs1, batch_inputs2) # sen_num x sent_rep_size
sent_reps = sent_reps.view(batch_size, max_doc_len, self.sent_rep_size) # b x doc_len x sent_rep_size
batch_masks = batch_masks.view(batch_size, max_doc_len, max_sent_len) # b x doc_len x max_sent_len
sent_masks = batch_masks.bool().any(2).float() # b x doc_len
sent_hiddens = self.sent_encoder(sent_reps, sent_masks) # b x doc_len x doc_rep_size
doc_reps, atten_scores = self.sent_attention(sent_hiddens, sent_masks) # b x doc_rep_size
batch_outputs = self.out(doc_reps) # b x num_labels
return batch_outputs
model = Model(vocab)
# build optimizer
learning_rate = 2e-4
decay = .75
decay_step = 1000
class Optimizer:
def __init__(self, model_parameters):
self.all_params = []
self.optims = []
self.schedulers = []
for name, parameters in model_parameters.items():
if name.startswith("basic"):
optim = torch.optim.Adam(parameters, lr=learning_rate)
self.optims.append(optim)
l = lambda step: decay ** (step // decay_step)
scheduler = torch.optim.lr_scheduler.LambdaLR(optim, lr_lambda=l)
self.schedulers.append(scheduler)
self.all_params.extend(parameters)
else:
Exception("no nameed parameters.")
self.num = len(self.optims)
def step(self):
for optim, scheduler in zip(self.optims, self.schedulers):
optim.step()
scheduler.step()
optim.zero_grad()
def zero_grad(self):
for optim in self.optims:
optim.zero_grad()
def get_lr(self):
lrs = tuple(map(lambda x: x.get_lr()[-1], self.schedulers))
lr = ' %.5f' * self.num
res = lr % lrs
return res
# build trainer
import time
from sklearn.metrics import classification_report
clip = 5.0
epochs = 1
early_stops = 3
log_interval = 50
test_batch_size = 128
train_batch_size = 128
save_model = './cnn.bin'
save_test = './cnn.csv'
class Trainer():
def __init__(self, model, vocab):
self.model = model
self.report = True
self.train_data = get_examples(train_data, vocab)
self.batch_num = int(np.ceil(len(self.train_data) / float(train_batch_size)))
self.dev_data = get_examples(dev_data, vocab)
# criterion
self.criterion = nn.CrossEntropyLoss()
# label name
self.target_names = vocab.target_names
# optimizer
self.optimizer = Optimizer(model.all_parameters)
# count
self.step = 0
self.early_stop = -1
self.best_train_f1, self.best_dev_f1 = 0, 0
self.last_epoch = epochs
def train(self):
logging.info('Start training...')
for epoch in range(1, epochs + 1):
train_f1 = self._train(epoch)
dev_f1 = self._eval(epoch)
if self.best_dev_f1 <= dev_f1:
logging.info(
"Exceed history dev = %.2f, current dev = %.2f" % (self.best_dev_f1, dev_f1))
torch.save(self.model.state_dict(), save_model)
self.best_train_f1 = train_f1
self.best_dev_f1 = dev_f1
self.early_stop = 0
else:
self.early_stop += 1
if self.early_stop == early_stops:
logging.info(
"Eearly stop in epoch %d, best train: %.2f, dev: %.2f" % (
epoch - early_stops, self.best_train_f1, self.best_dev_f1))
self.last_epoch = epoch
break
def test(self):
self.model.load_state_dict(torch.load(save_model))
self._eval(self.last_epoch + 1, test=True)
def _train(self, epoch):
self.optimizer.zero_grad()
self.model.train()
start_time = time.time()
epoch_start_time = time.time()
overall_losses = 0
losses = 0
batch_idx = 1
y_pred = []
y_true = []
for batch_data in data_iter(self.train_data, train_batch_size, shuffle=True):
torch.cuda.empty_cache()
batch_inputs, batch_labels = self.batch2tensor(batch_data)
batch_outputs = self.model(batch_inputs)
loss = self.criterion(batch_outputs, batch_labels)
loss.backward()
loss_value = loss.detach().cpu().item()
losses += loss_value
overall_losses += loss_value
y_pred.extend(torch.max(batch_outputs, dim=1)[1].cpu().numpy().tolist())
y_true.extend(batch_labels.cpu().numpy().tolist())
nn.utils.clip_grad_norm_(self.optimizer.all_params, max_norm=clip)
for optimizer, scheduler in zip(self.optimizer.optims, self.optimizer.schedulers):
optimizer.step()
scheduler.step()
self.optimizer.zero_grad()
self.step += 1
if batch_idx % log_interval == 0:
elapsed = time.time() - start_time
lrs = self.optimizer.get_lr()
logging.info(
'| epoch {:3d} | step {:3d} | batch {:3d}/{:3d} | lr{} | loss {:.4f} | s/batch {:.2f}'.format(
epoch, self.step, batch_idx, self.batch_num, lrs,
losses / log_interval,
elapsed / log_interval))
losses = 0
start_time = time.time()
batch_idx += 1
overall_losses /= self.batch_num
during_time = time.time() - epoch_start_time
# reformat
overall_losses = reformat(overall_losses, 4)
score, f1 = get_score(y_true, y_pred)
logging.info(
'| epoch {:3d} | score {} | f1 {} | loss {:.4f} | time {:.2f}'.format(epoch, score, f1,
overall_losses,
during_time))
if set(y_true) == set(y_pred) and self.report:
report = classification_report(y_true, y_pred, digits=4, target_names=self.target_names)
logging.info('\n' + report)
return f1
def _eval(self, epoch, test=False):
self.model.eval()
start_time = time.time()
data = self.test_data if test else self.dev_data
y_pred = []
y_true = []
with torch.no_grad():
for batch_data in data_iter(data, test_batch_size, shuffle=False):
torch.cuda.empty_cache()
batch_inputs, batch_labels = self.batch2tensor(batch_data)
batch_outputs = self.model(batch_inputs)
y_pred.extend(torch.max(batch_outputs, dim=1)[1].cpu().numpy().tolist())
y_true.extend(batch_labels.cpu().numpy().tolist())
score, f1 = get_score(y_true, y_pred)
during_time = time.time() - start_time
if test:
df = pd.DataFrame({'label': y_pred})
df.to_csv(save_test, index=False, sep=',')
else:
logging.info(
'| epoch {:3d} | dev | score {} | f1 {} | time {:.2f}'.format(epoch, score, f1,
during_time))
if set(y_true) == set(y_pred) and self.report:
report = classification_report(y_true, y_pred, digits=4, target_names=self.target_names)
logging.info('\n' + report)
return f1
def batch2tensor(self, batch_data):
'''
[[label, doc_len, [[sent_len, [sent_id0, ...], [sent_id1, ...]], ...]]
'''
batch_size = len(batch_data)
doc_labels = []
doc_lens = []
doc_max_sent_len = []
for doc_data in batch_data:
doc_labels.append(doc_data[0])
doc_lens.append(doc_data[1])
sent_lens = [sent_data[0] for sent_data in doc_data[2]]
max_sent_len = max(sent_lens)
doc_max_sent_len.append(max_sent_len)
max_doc_len = max(doc_lens)
max_sent_len = max(doc_max_sent_len)
batch_inputs1 = torch.zeros((batch_size, max_doc_len, max_sent_len), dtype=torch.int64)
batch_inputs2 = torch.zeros((batch_size, max_doc_len, max_sent_len), dtype=torch.int64)
batch_masks = torch.zeros((batch_size, max_doc_len, max_sent_len), dtype=torch.float32)
batch_labels = torch.LongTensor(doc_labels)
for b in range(batch_size):
for sent_idx in range(doc_lens[b]):
sent_data = batch_data[b][2][sent_idx]
for word_idx in range(sent_data[0]):
batch_inputs1[b, sent_idx, word_idx] = sent_data[1][word_idx]
batch_inputs2[b, sent_idx, word_idx] = sent_data[2][word_idx]
batch_masks[b, sent_idx, word_idx] = 1
if use_cuda:
batch_inputs1 = batch_inputs1.to(device)
batch_inputs2 = batch_inputs2.to(device)
batch_masks = batch_masks.to(device)
batch_labels = batch_labels.to(device)
return (batch_inputs1, batch_inputs2, batch_masks), batch_labels
# train
trainer = Trainer(model, vocab)
trainer.train()
三、TextRNN
TextRNN与TextCNN的主要区别为在神经网络中间层采取了LSTM的形式,区别代码如下:
# build model
class Model(nn.Module):
def __init__(self, vocab):
super(Model, self).__init__()
self.sent_rep_size = word_hidden_size * 2
self.doc_rep_size = sent_hidden_size * 2
self.all_parameters = {}
parameters = []
self.word_encoder = WordLSTMEncoder(vocab)
self.word_attention = Attention(self.sent_rep_size)
parameters.extend(list(filter(lambda p: p.requires_grad, self.word_encoder.parameters())))
parameters.extend(list(filter(lambda p: p.requires_grad, self.word_attention.parameters())))
self.sent_encoder = SentEncoder(self.sent_rep_size)
self.sent_attention = Attention(self.doc_rep_size)
parameters.extend(list(filter(lambda p: p.requires_grad, self.sent_encoder.parameters())))
parameters.extend(list(filter(lambda p: p.requires_grad, self.sent_attention.parameters())))
self.out = nn.Linear(self.doc_rep_size, vocab.label_size, bias=True)
parameters.extend(list(filter(lambda p: p.requires_grad, self.out.parameters())))
if use_cuda:
self.to(device)
if len(parameters) > 0:
self.all_parameters["basic_parameters"] = parameters
logging.info('Build model with lstm word encoder, lstm sent encoder.')
para_num = sum([np.prod(list(p.size())) for p in self.parameters()])
logging.info('Model param num: %.2f M.' % (para_num / 1e6))
def forward(self, batch_inputs):
# batch_inputs(batch_inputs1, batch_inputs2): b x doc_len x sent_len
# batch_masks : b x doc_len x sent_len
batch_inputs1, batch_inputs2, batch_masks = batch_inputs
batch_size, max_doc_len, max_sent_len = batch_inputs1.shape[0], batch_inputs1.shape[1], batch_inputs1.shape[2]
batch_inputs1 = batch_inputs1.view(batch_size * max_doc_len, max_sent_len) # sen_num x sent_len
batch_inputs2 = batch_inputs2.view(batch_size * max_doc_len, max_sent_len) # sen_num x sent_len
batch_masks = batch_masks.view(batch_size * max_doc_len, max_sent_len) # sen_num x sent_len
batch_hiddens = self.word_encoder(batch_inputs1, batch_inputs2,
batch_masks) # sen_num x sent_len x sent_rep_size
sent_reps, atten_scores = self.word_attention(batch_hiddens, batch_masks) # sen_num x sent_rep_size
sent_reps = sent_reps.view(batch_size, max_doc_len, self.sent_rep_size) # b x doc_len x sent_rep_size
batch_masks = batch_masks.view(batch_size, max_doc_len, max_sent_len) # b x doc_len x max_sent_len
sent_masks = batch_masks.bool().any(2).float() # b x doc_len
sent_hiddens = self.sent_encoder(sent_reps, sent_masks) # b x doc_len x doc_rep_size
doc_reps, atten_scores = self.sent_attention(sent_hiddens, sent_masks) # b x doc_rep_size
batch_outputs = self.out(doc_reps) # b x num_labels
return batch_outputs
model = Model(vocab)