我的NLP实践之旅06
我的NLP实践之旅06
经历了这些日子的组队学习,这次的NLP实践之路也逐渐接近尾声了,在以后的日子里,我也要努力学习,多多加油啊,扯远了,下面进入正题
Bert
通过这次的组队学习,我终于接触到了目前最热门的自然语言处理模型之一的Bert,起初我听到Bert的概念时是完全懵逼的,不过后来在看了李宏毅在YouTube上的视频后自己逐渐理解了其中的具体含义,下面对Bert进行介绍。
BERT的全称是Bidirectional Encoder Representation from Transformers,即双向Transformer的Encoder,其实它是TransFormer模型的一部分,TransFormer模型的示意图如下:
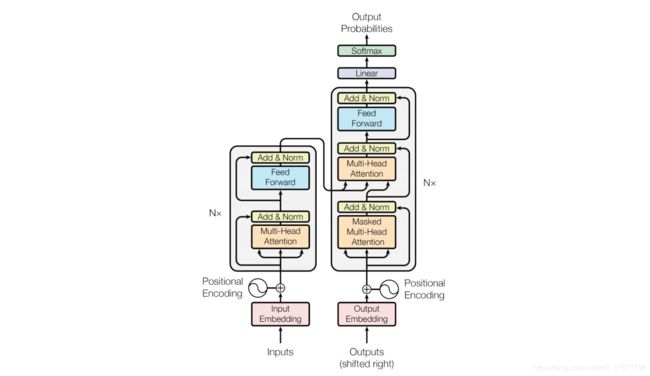
简单来说,Bert模型为TransFormer模型的左半部分,TransFromer模型训练时需要提供输入和输出数据,其中要输入的输出数据在预测下一段文本的情况下可以理解为下一个词,而Transformer的参数十分的庞大,故大多数情况只运用模型的左边来进行数据的预处理。
从上图中大家应该注意到了模型有一个结构叫Attention,这个结构可以理解为一个特殊的神经网络,在文本预测的场景中,我们通常需要基于上一段文本预测下一段话,因此需要模型有一定的记忆能力;已知的模型如LSTM等可以一定程度上解决这个问题,然而由于在神经网络中会对之前的信息进行削减,而且,关键的信息也可能隔字符出现,以此Attention机制应运而生。
Attention主要通过在神经网络隐层中将k、v、q矩阵进行相乘转换后输出的结果,其中k为键矩阵,v为值矩阵,q为问题矩阵。
bert代码如下:
# build module
import torch.nn as nn
import torch.nn.functional as F
class Attention(nn.Module):
def __init__(self, hidden_size):
super(Attention, self).__init__()
self.weight = nn.Parameter(torch.Tensor(hidden_size, hidden_size))
self.weight.data.normal_(mean=0.0, std=0.05)
self.bias = nn.Parameter(torch.Tensor(hidden_size))
b = np.zeros(hidden_size, dtype=np.float32)
self.bias.data.copy_(torch.from_numpy(b))
self.query = nn.Parameter(torch.Tensor(hidden_size))
self.query.data.normal_(mean=0.0, std=0.05)
def forward(self, batch_hidden, batch_masks):
# batch_hidden: b x len x hidden_size (2 * hidden_size of lstm)
# batch_masks: b x len
# linear
key = torch.matmul(batch_hidden, self.weight) + self.bias # b x len x hidden
# compute attention
outputs = torch.matmul(key, self.query) # b x len
masked_outputs = outputs.masked_fill((1 - batch_masks).bool(), float(-1e32))
attn_scores = F.softmax(masked_outputs, dim=1) # b x len
# 对于全零向量,-1e32的结果为 1/len, -inf为nan, 额外补0
masked_attn_scores = attn_scores.masked_fill((1 - batch_masks).bool(), 0.0)
# sum weighted sources
batch_outputs = torch.bmm(masked_attn_scores.unsqueeze(1), key).squeeze(1) # b x hidden
return batch_outputs, attn_scores
# build word encoder
bert_path = '../bert-mini/'
dropout = 0.15
from transformers import BertModel
class WordBertEncoder(nn.Module):
def __init__(self):
super(WordBertEncoder, self).__init__()
self.dropout = nn.Dropout(dropout)
self.tokenizer = WhitespaceTokenizer()
self.bert = BertModel.from_pretrained(bert_path)
self.pooled = False
logging.info('Build Bert encoder with pooled {}.'.format(self.pooled))
def encode(self, tokens):
tokens = self.tokenizer.tokenize(tokens)
return tokens
def get_bert_parameters(self):
no_decay = ['bias', 'LayerNorm.weight']
optimizer_parameters = [
{'params': [p for n, p in self.bert.named_parameters() if not any(nd in n for nd in no_decay)],
'weight_decay': 0.01},
{'params': [p for n, p in self.bert.named_parameters() if any(nd in n for nd in no_decay)],
'weight_decay': 0.0}
]
return optimizer_parameters
def forward(self, input_ids, token_type_ids):
# input_ids: sen_num x bert_len
# token_type_ids: sen_num x bert_len
# sen_num x bert_len x 256, sen_num x 256
sequence_output, pooled_output = self.bert(input_ids=input_ids, token_type_ids=token_type_ids)
if self.pooled:
reps = pooled_output
else:
reps = sequence_output[:, 0, :] # sen_num x 256
if self.training:
reps = self.dropout(reps)
return reps
class WhitespaceTokenizer():
"""WhitespaceTokenizer with vocab."""
def __init__(self):
vocab_file = bert_path + 'vocab.txt'
self._token2id = self.load_vocab(vocab_file)
self._id2token = {v: k for k, v in self._token2id.items()}
self.max_len = 256
self.unk = 1
logging.info("Build Bert vocab with size %d." % (self.vocab_size))
def load_vocab(self, vocab_file):
f = open(vocab_file, 'r')
lines = f.readlines()
lines = list(map(lambda x: x.strip(), lines))
vocab = dict(zip(lines, range(len(lines))))
return vocab
def tokenize(self, tokens):
assert len(tokens) <= self.max_len - 2
tokens = ["[CLS]"] + tokens + ["[SEP]"]
output_tokens = self.token2id(tokens)
return output_tokens
def token2id(self, xs):
if isinstance(xs, list):
return [self._token2id.get(x, self.unk) for x in xs]
return self._token2id.get(xs, self.unk)
@property
def vocab_size(self):
return len(self._id2token)
# build sent encoder
sent_hidden_size = 256
sent_num_layers = 2
class SentEncoder(nn.Module):
def __init__(self, sent_rep_size):
super(SentEncoder, self).__init__()
self.dropout = nn.Dropout(dropout)
self.sent_lstm = nn.LSTM(
input_size=sent_rep_size,
hidden_size=sent_hidden_size,
num_layers=sent_num_layers,
batch_first=True,
bidirectional=True
)
def forward(self, sent_reps, sent_masks):
# sent_reps: b x doc_len x sent_rep_size
# sent_masks: b x doc_len
sent_hiddens, _ = self.sent_lstm(sent_reps) # b x doc_len x hidden*2
sent_hiddens = sent_hiddens * sent_masks.unsqueeze(2)
if self.training:
sent_hiddens = self.dropout(sent_hiddens)
return sent_hiddens
# build model
class Model(nn.Module):
def __init__(self, vocab):
super(Model, self).__init__()
self.sent_rep_size = 256
self.doc_rep_size = sent_hidden_size * 2
self.all_parameters = {}
parameters = []
self.word_encoder = WordBertEncoder()
bert_parameters = self.word_encoder.get_bert_parameters()
self.sent_encoder = SentEncoder(self.sent_rep_size)
self.sent_attention = Attention(self.doc_rep_size)
parameters.extend(list(filter(lambda p: p.requires_grad, self.sent_encoder.parameters())))
parameters.extend(list(filter(lambda p: p.requires_grad, self.sent_attention.parameters())))
self.out = nn.Linear(self.doc_rep_size, vocab.label_size, bias=True)
parameters.extend(list(filter(lambda p: p.requires_grad, self.out.parameters())))
if use_cuda:
self.to(device)
if len(parameters) > 0:
self.all_parameters["basic_parameters"] = parameters
self.all_parameters["bert_parameters"] = bert_parameters
logging.info('Build model with bert word encoder, lstm sent encoder.')
para_num = sum([np.prod(list(p.size())) for p in self.parameters()])
logging.info('Model param num: %.2f M.' % (para_num / 1e6))
def forward(self, batch_inputs):
# batch_inputs(batch_inputs1, batch_inputs2): b x doc_len x sent_len
# batch_masks : b x doc_len x sent_len
batch_inputs1, batch_inputs2, batch_masks = batch_inputs
batch_size, max_doc_len, max_sent_len = batch_inputs1.shape[0], batch_inputs1.shape[1], batch_inputs1.shape[2]
batch_inputs1 = batch_inputs1.view(batch_size * max_doc_len, max_sent_len) # sen_num x sent_len
batch_inputs2 = batch_inputs2.view(batch_size * max_doc_len, max_sent_len) # sen_num x sent_len
batch_masks = batch_masks.view(batch_size * max_doc_len, max_sent_len) # sen_num x sent_len
sent_reps = self.word_encoder(batch_inputs1, batch_inputs2) # sen_num x sent_rep_size
sent_reps = sent_reps.view(batch_size, max_doc_len, self.sent_rep_size) # b x doc_len x sent_rep_size
batch_masks = batch_masks.view(batch_size, max_doc_len, max_sent_len) # b x doc_len x max_sent_len
sent_masks = batch_masks.bool().any(2).float() # b x doc_len
sent_hiddens = self.sent_encoder(sent_reps, sent_masks) # b x doc_len x doc_rep_size
doc_reps, atten_scores = self.sent_attention(sent_hiddens, sent_masks) # b x doc_rep_size
batch_outputs = self.out(doc_reps) # b x num_labels
return batch_outputs
model = Model(vocab)
# build optimizer
learning_rate = 2e-4
bert_lr = 5e-5
decay = .75
decay_step = 1000
from transformers import AdamW, get_linear_schedule_with_warmup
class Optimizer:
def __init__(self, model_parameters, steps):
self.all_params = []
self.optims = []
self.schedulers = []
for name, parameters in model_parameters.items():
if name.startswith("basic"):
optim = torch.optim.Adam(parameters, lr=learning_rate)
self.optims.append(optim)
l = lambda step: decay ** (step // decay_step)
scheduler = torch.optim.lr_scheduler.LambdaLR(optim, lr_lambda=l)
self.schedulers.append(scheduler)
self.all_params.extend(parameters)
elif name.startswith("bert"):
optim_bert = AdamW(parameters, bert_lr, eps=1e-8)
self.optims.append(optim_bert)
scheduler_bert = get_linear_schedule_with_warmup(optim_bert, 0, steps)
self.schedulers.append(scheduler_bert)
for group in parameters:
for p in group['params']:
self.all_params.append(p)
else:
Exception("no nameed parameters.")
self.num = len(self.optims)
def step(self):
for optim, scheduler in zip(self.optims, self.schedulers):
optim.step()
scheduler.step()
optim.zero_grad()
def zero_grad(self):
for optim in self.optims:
optim.zero_grad()
def get_lr(self):
lrs = tuple(map(lambda x: x.get_lr()[-1], self.schedulers))
lr = ' %.5f' * self.num
res = lr % lrs
return res
# build trainer
import time
from sklearn.metrics import classification_report
clip = 5.0
epochs = 1
early_stops = 3
log_interval = 50
test_batch_size = 16
train_batch_size = 16
save_model = './bert.bin'
save_test = './bert.csv'
class Trainer():
def __init__(self, model, vocab):
self.model = model
self.report = True
self.train_data = get_examples(train_data, model.word_encoder, vocab)
self.batch_num = int(np.ceil(len(self.train_data) / float(train_batch_size)))
self.dev_data = get_examples(dev_data, model.word_encoder, vocab)
self.test_data = get_examples(test_data, model.word_encoder, vocab)
# criterion
self.criterion = nn.CrossEntropyLoss()
# label name
self.target_names = vocab.target_names
# optimizer
self.optimizer = Optimizer(model.all_parameters, steps=self.batch_num * epochs)
# count
self.step = 0
self.early_stop = -1
self.best_train_f1, self.best_dev_f1 = 0, 0
self.last_epoch = epochs
def train(self):
logging.info('Start training...')
for epoch in range(1, epochs + 1):
train_f1 = self._train(epoch)
dev_f1 = self._eval(epoch)
if self.best_dev_f1 <= dev_f1:
logging.info(
"Exceed history dev = %.2f, current dev = %.2f" % (self.best_dev_f1, dev_f1))
torch.save(self.model.state_dict(), save_model)
self.best_train_f1 = train_f1
self.best_dev_f1 = dev_f1
self.early_stop = 0
else:
self.early_stop += 1
if self.early_stop == early_stops:
logging.info(
"Eearly stop in epoch %d, best train: %.2f, dev: %.2f" % (
epoch - early_stops, self.best_train_f1, self.best_dev_f1))
self.last_epoch = epoch
break
def test(self):
self.model.load_state_dict(torch.load(save_model))
self._eval(self.last_epoch + 1, test=True)
def _train(self, epoch):
self.optimizer.zero_grad()
self.model.train()
start_time = time.time()
epoch_start_time = time.time()
overall_losses = 0
losses = 0
batch_idx = 1
y_pred = []
y_true = []
for batch_data in data_iter(self.train_data, train_batch_size, shuffle=True):
torch.cuda.empty_cache()
batch_inputs, batch_labels = self.batch2tensor(batch_data)
batch_outputs = self.model(batch_inputs)
loss = self.criterion(batch_outputs, batch_labels)
loss.backward()
loss_value = loss.detach().cpu().item()
losses += loss_value
overall_losses += loss_value
y_pred.extend(torch.max(batch_outputs, dim=1)[1].cpu().numpy().tolist())
y_true.extend(batch_labels.cpu().numpy().tolist())
nn.utils.clip_grad_norm_(self.optimizer.all_params, max_norm=clip)
for optimizer, scheduler in zip(self.optimizer.optims, self.optimizer.schedulers):
optimizer.step()
scheduler.step()
self.optimizer.zero_grad()
self.step += 1
if batch_idx % log_interval == 0:
elapsed = time.time() - start_time
lrs = self.optimizer.get_lr()
logging.info(
'| epoch {:3d} | step {:3d} | batch {:3d}/{:3d} | lr{} | loss {:.4f} | s/batch {:.2f}'.format(
epoch, self.step, batch_idx, self.batch_num, lrs,
losses / log_interval,
elapsed / log_interval))
losses = 0
start_time = time.time()
batch_idx += 1
overall_losses /= self.batch_num
during_time = time.time() - epoch_start_time
# reformat
overall_losses = reformat(overall_losses, 4)
score, f1 = get_score(y_true, y_pred)
logging.info(
'| epoch {:3d} | score {} | f1 {} | loss {:.4f} | time {:.2f}'.format(epoch, score, f1,
overall_losses,
during_time))
if set(y_true) == set(y_pred) and self.report:
report = classification_report(y_true, y_pred, digits=4, target_names=self.target_names)
logging.info('\n' + report)
return f1
def _eval(self, epoch, test=False):
self.model.eval()
start_time = time.time()
data = self.test_data if test else self.dev_data
y_pred = []
y_true = []
with torch.no_grad():
for batch_data in data_iter(data, test_batch_size, shuffle=False):
torch.cuda.empty_cache()
batch_inputs, batch_labels = self.batch2tensor(batch_data)
batch_outputs = self.model(batch_inputs)
y_pred.extend(torch.max(batch_outputs, dim=1)[1].cpu().numpy().tolist())
y_true.extend(batch_labels.cpu().numpy().tolist())
score, f1 = get_score(y_true, y_pred)
during_time = time.time() - start_time
if test:
df = pd.DataFrame({'label': y_pred})
df.to_csv(save_test, index=False, sep=',')
else:
logging.info(
'| epoch {:3d} | dev | score {} | f1 {} | time {:.2f}'.format(epoch, score, f1,
during_time))
if set(y_true) == set(y_pred) and self.report:
report = classification_report(y_true, y_pred, digits=4, target_names=self.target_names)
logging.info('\n' + report)
return f1
def batch2tensor(self, batch_data):
'''
[[label, doc_len, [[sent_len, [sent_id0, ...], [sent_id1, ...]], ...]]
'''
batch_size = len(batch_data)
doc_labels = []
doc_lens = []
doc_max_sent_len = []
for doc_data in batch_data:
doc_labels.append(doc_data[0])
doc_lens.append(doc_data[1])
sent_lens = [sent_data[0] for sent_data in doc_data[2]]
max_sent_len = max(sent_lens)
doc_max_sent_len.append(max_sent_len)
max_doc_len = max(doc_lens)
max_sent_len = max(doc_max_sent_len)
batch_inputs1 = torch.zeros((batch_size, max_doc_len, max_sent_len), dtype=torch.int64)
batch_inputs2 = torch.zeros((batch_size, max_doc_len, max_sent_len), dtype=torch.int64)
batch_masks = torch.zeros((batch_size, max_doc_len, max_sent_len), dtype=torch.float32)
batch_labels = torch.LongTensor(doc_labels)
for b in range(batch_size):
for sent_idx in range(doc_lens[b]):
sent_data = batch_data[b][2][sent_idx]
for word_idx in range(sent_data[0]):
batch_inputs1[b, sent_idx, word_idx] = sent_data[1][word_idx]
batch_inputs2[b, sent_idx, word_idx] = sent_data[2][word_idx]
batch_masks[b, sent_idx, word_idx] = 1
if use_cuda:
batch_inputs1 = batch_inputs1.to(device)
batch_inputs2 = batch_inputs2.to(device)
batch_masks = batch_masks.to(device)
batch_labels = batch_labels.to(device)
return (batch_inputs1, batch_inputs2, batch_masks), batch_labels
# train
trainer = Trainer(model, vocab)
trainer.train()