百度飞桨架构师手把手带你零基础实践深度学习——VisualDL
百度飞桨架构师手把手带你零基础实践深度学习——打卡计划
- 总目录
- VisualDL 2.0应用升级--基于「手写数字识别」模型的全功能展示
- VisualDL2.0使用步骤
- 搭建LeNet网络
- 训练网络并使用VisualDL2.0可视化训练过程
- 训练及可视化代码如下:
- 多组实验对比--使用VisualDL对比不同学习率下的模型效果:
- 启动VisualDL查看「手写数字识别」可视化结果
- 使用Audio组件试听音频样本
- 启动VisualDL试听音频样本
下面给出课程链接,欢迎各位小伙来来报考!本帖将持续更新。我只是飞桨的搬运工

话不多说,这么良心的课程赶快扫码上车!https://aistudio.baidu.com/aistudio/education/group/info/1297?activityId=5&directly=1&shared=1
总目录
VisualDL 2.0应用升级–基于「手写数字识别」模型的全功能展示
本项目将基于「手写数字识别」任务,介绍如何运用全新升级版飞桨可视化分析工具–VisualDL 2.0对模型训练过程进行可视化分析。
VisualDL是深度学习模型可视化分析工具,以丰富的图表呈现训练参数变化趋势、模型结构、数据样本、PR曲线等,帮助用户清晰直观地理解模型训练过程及模型结构,进而实现高效的模型调优。
VisualDL 2.0版本新增四大功能:
- 图结构可视化
- 音频样本播放
- 直方图
- PR 曲线
VisualDL的具体介绍及本地使用指南请参考:GitHub、VisualDL使用指南。
下面我们将详细介绍如何在AI Studio上使用VisualDL进行:
- 日志文件的创建
- 实时训练参数可视化
- 多组实验对比
- 样本数据(图片/音频)可视化
- Tensor数据参数变化趋势可视化
- PR Curve展示
- 模型网络结构可视化
VisualDL2.0使用步骤
- 创建日志文件
LogWriter,设置实验结果存放路径,默认上一级路径为’./home/aistudio’ - 训练过程中插入数据打点语句,将结果储存至日志文件中
- 切换到「可视化」页签,指定日志文件与模型文件(不指定日志文件无法启动VisualDL)
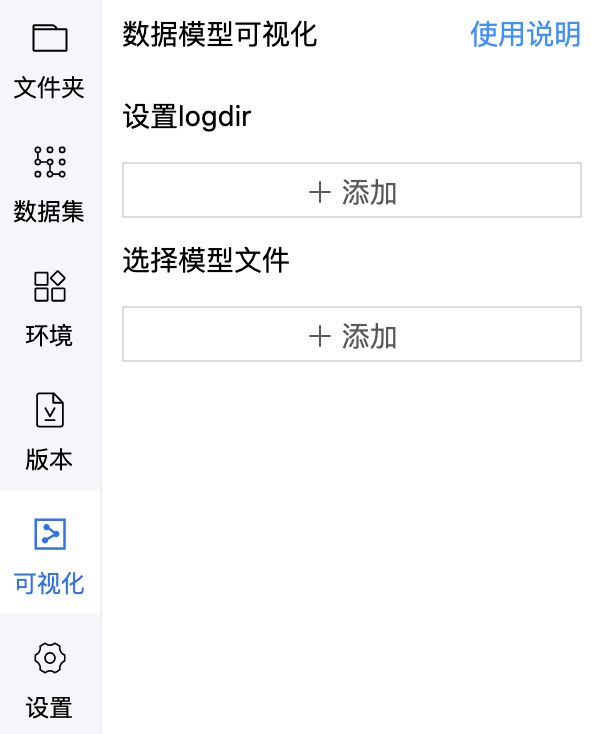
*注意:VisualDL启动中不可删除或替换日志/模型文件;日志文件可多选,模型文件一次只能上传一个,且模型文件暂只支持模型网络结构,不支持展示各层参数
- 选择日志文件

- 选择模型文件

- 点击「启动VisualDL」后,再点击「打开VisualDL」即可打开可视化界面
*注意:使用VisualDL2.0需要Paddle版本1.8及以上
现在让我们正式开始「手写数字识别」模型训练及可视化吧!
搭建LeNet网络
- LeNet网络实现代码如下:
import paddle
import paddle.fluid as fluid
import numpy as np
import cv2
from visualdl import LogWriter
# define a LeNet-5 nn
def lenet_5(img, label):
conv1 = fluid.nets.simple_img_conv_pool(
input=img,
filter_size=5,
num_filters=20,
pool_size=2,
pool_stride=2,
act="relu")
conv1_bn = fluid.layers.batch_norm(input=conv1)
conv2 = fluid.nets.simple_img_conv_pool(
input=conv1_bn,
filter_size=5,
num_filters=50,
pool_size=2,
pool_stride=2,
act="relu")
predictions = fluid.layers.fc(input=conv2, name="fc", size=10, act="softmax")
cost = fluid.layers.cross_entropy(input=predictions, label=label)
avg_cost = fluid.layers.mean(cost)
acc = fluid.layers.accuracy(input=predictions, label=label)
return avg_cost, acc, predictions
训练网络并使用VisualDL2.0可视化训练过程
- 创建LeNet日志文件:
writer = LogWriter("./log/lenet")
- 训练过程中插入作图语句,展示accuracy和loss的变化趋势:
writer.add_scalar(tag="train/loss", step=step, value=cost)
writer.add_scalar(tag="train/acc", step=step, value=accuracy)
- 创建多组子日志文件,以相同tag名记录同一类参数,实现多组实验对比:
writer=LogWriter('paddle_lenet_log/lr0.001')
writer1=LogWriter('paddle_lenet_log/lr0.01')
writer2=LogWriter('paddle_lenet_log/lr0.05')
writer3=LogWriter('paddle_lenet_log/lr0.1')
writer.add_scalar(tag="train/loss", step=step, value=cost)
writer.add_scalar(tag="train/acc", step=step, value=accuracy)
writer1.add_scalar(tag="train/loss", step=step, value=cost)
writer1.add_scalar(tag="train/acc", step=step, value=accuracy)
writer2.add_scalar(tag="train/loss", step=step, value=cost)
writer2.add_scalar(tag="train/acc", step=step, value=accuracy)
writer3.add_scalar(tag="train/loss", step=step, value=cost)
writer3.add_scalar(tag="train/acc", step=step, value=accuracy)
- 记录每一批次中的第一张图片:
img = np.reshape(batch[0][0], [28, 28, 1]) * 255
writer.add_image(tag="train/input", step=step, img=img)
- 记录训练过程中每一层网络权重(weight)、偏差(bias)的变化趋势:
writer.add_histogram(tag='train/{}'.format(param), step=step, values=values)
- 记录分类效果–precision & recall曲线:
writer.add_pr_curve(tag='train/class_{}_pr_curve'.format(i),
labels=label_i,
predictions=prediction_i,
step=step,
num_thresholds=20)
- 保存模型结构:
fluid.io.save_inference_model(dirname='./model', feeded_var_names=['img'],target_vars=[predictions], executor=exe)
训练及可视化代码如下:
# train the nn
def train():
with LogWriter(logdir="paddle_lenet_log/lr0.001") as writer:
# 使用scalar组件记录一个标量数据
img = fluid.data(name="img", shape=[-1, 1, 28, 28], dtype="float32")
label = fluid.data(name="label", shape=[-1, 1], dtype="int64")
avg_cost, acc, predictions = lenet_5(img, label)
batch_size = 64
# get the mnist dataset
train_reader = paddle.batch(paddle.dataset.mnist.train(), batch_size=batch_size)
# define the loss
optimizer = fluid.optimizer.Adam(learning_rate=0.001)
optimizer.minimize(avg_cost)
# running on cpu
place = fluid.CPUPlace()
feeder = fluid.DataFeeder(feed_list=[img, label], place=place)
exe = fluid.Executor(place)
# init all param
exe.run(fluid.default_startup_program())
step = loss_sum = acc_sum = num_example = 0
params = [param.name for param in fluid.default_main_program().all_parameters()]
# start to train
for i in range(1):
for batch in train_reader():
data = np.array(batch)
cost, accuracy, pred = exe.run(
feed=feeder.feed(batch),
fetch_list=[avg_cost.name, acc.name, predictions.name])
step += 1
num_example += len(batch[0])
loss_sum += cost[0] * len(batch[0])
acc_sum += accuracy[0] * len(batch[0])
if step % 10 == 0:
# add scalar
writer.add_scalar(tag="train/loss", step=step, value=cost)
writer.add_scalar(tag="train/acc", step=step, value=accuracy)
# record first image in each batch
img = np.reshape(batch[0][0], [28, 28, 1]) * 255
writer.add_image(tag="train/input", step=step, img=img)
# record all param
for param in params:
values = fluid.global_scope().find_var(param).get_tensor()
writer.add_histogram(tag='train/{}'.format(param), step=step, values=values)
print("Step {}: loss {} accuracy {}".format(step, loss_sum / num_example, acc_sum / num_example))
loss_sum = acc_sum = num_example = 0
# record pr-curve
labels = np.array(batch)[:, 1]
for i in range(10):
label_i = np.array(labels == i, dtype='int32')
prediction_i = pred[:, i]
writer.add_pr_curve(tag='train/class_{}_pr_curve'.format(i),
labels=label_i,
predictions=prediction_i,
step=step,
num_thresholds=20)
fluid.io.save_inference_model(dirname='./model', feeded_var_names=['img'],target_vars=[predictions], executor=exe)
if __name__ == "__main__":
train()
多组实验对比–使用VisualDL对比不同学习率下的模型效果:
#多组实验对比
writer1=LogWriter('paddle_lenet_log/lr0.01')
writer2=LogWriter('paddle_lenet_log/lr0.05')
writer3=LogWriter('paddle_lenet_log/lr0.1')
# train the nn
def train():
# 使用scalar组件记录一个标量数据
img = fluid.data(name="img", shape=[-1, 1, 28, 28], dtype="float32")
label = fluid.data(name="label", shape=[-1, 1], dtype="int64")
avg_cost, acc, predictions = lenet_5(img, label)
batch_size = 64
# get the mnist dataset
train_reader = paddle.batch(paddle.dataset.mnist.train(), batch_size=batch_size)
for j in [0.01,0.05,0.1]:
# define the loss
optimizer = fluid.optimizer.Adam(learning_rate=j)
optimizer.minimize(avg_cost)
# running on cpu
place = fluid.CPUPlace()
feeder = fluid.DataFeeder(feed_list=[img, label], place=place)
exe = fluid.Executor(place)
# init all param
exe.run(fluid.default_startup_program())
step = loss_sum = acc_sum = num_example = 0
params = [param.name for param in fluid.default_main_program().all_parameters()]
# start to train
for i in range(1):
for batch in train_reader():
data = np.array(batch)
cost, accuracy, pred = exe.run(
feed=feeder.feed(batch),
fetch_list=[avg_cost.name, acc.name, predictions.name])
step += 1
num_example += len(batch[0])
loss_sum += cost[0] * len(batch[0])
acc_sum += accuracy[0] * len(batch[0])
if step % 10 == 0:
# add scalar
if j==0.01:
writer1.add_scalar(tag="train/loss", step=step, value=cost)
writer1.add_scalar(tag="train/acc", step=step, value=accuracy)
elif j==0.05:
writer2.add_scalar(tag="train/loss", step=step, value=cost)
writer2.add_scalar(tag="train/acc", step=step, value=accuracy)
elif j==0.1:
writer3.add_scalar(tag="train/loss", step=step, value=cost)
writer3.add_scalar(tag="train/acc", step=step, value=accuracy)
if __name__ == "__main__":
train()
启动VisualDL查看「手写数字识别」可视化结果
启动步骤:
-
切换到「可视化」指定可视化日志 & 模型文件
- 日志文件选择 ‘paddle_lenet_log’
- 模型文件选择 'model’文件中的__model__(VisualDL暂时只支持可视化网络结构)
-
点击「启动VisualDL」后点击「打开VisualDL」,即可查看可视化结果:
-
Accuracy和Loss的实时变化趋势

在训练过程中,我们可以监测到实时的accuracy以及loss的变化趋势,便于及时发现问题,提前终止训练,提高训练效率。 -
不同学习率下的模型结果对比(多组实验对比)

通过对比,我们可以看到,当初始学习率设置为0.001时,Loss呈现优美的下降趋势且后续渐渐收敛,Accuracy呈现逐渐上升并趋于平稳,因此,将初始学习率设置为0.001时,模型效果达到最佳。
- 每一批次的第一张图片在不同训练步数下的展示

-
Weight和Bias在训练过程中的展示

从上图可以看出,Histogram记录了每一层网络的weight与bias在训练过程中的变化,我们可以通过观察了解每一层的训练情况,便于快速定位问题,优化模型。 -
每一分类的Precision & Recall

Precision是指正样本的数量除以所有被选中样本的数量,而Recall是指所有正样本中被推理正确的比例,因此Precision和Recall越高,代表我们的模型就越好。通过观察PR曲线,便于权衡精度与召回率,确定最佳阈值。 -
LeNet模型结构展示

使用Audio组件试听音频样本
针对语音技术相关任务,VisualDL提供Audio组件,支持开发者们在训练中试听音频样本,掌握音频的训练情况。
接下来,以飞桨语音合成套件–Parakeet中的音频数据为例,展示如何使用Audio组件播放音频样本,完整代码如下:
from visualdl import LogWriter
import numpy as np
import wave
#音频处理--转为ndarray格式
def read_audio_data(audio_path):
"""
Get audio data.
"""
CHUNK = 4096
f = wave.open(audio_path, "rb")
wavdata = []
chunk = f.readframes(CHUNK)
while chunk:
data = np.frombuffer(chunk, dtype='uint8')
wavdata.extend(data)
chunk = f.readframes(CHUNK)
# 8k sample rate, 16bit frame, 1 channel
shape = [22000, 2, 1]
return shape, wavdata
#创建日志记录音频数据
writer=LogWriter(logdir="./audio")
for i in ['./testing1.wav', './testing2.wav', './testing3.wav', './testing4.wav', './testing5.wav']:
audio_shape, audio_data = read_audio_data(i)
audio_data = np.array(audio_data)
#使用「Audio」组件写入音频数据
writer.add_audio(tag="audio_tag"+i,
audio_array=audio_data,
step=0,
sample_rate=22000) #采样率必须对应原音频的采样率,才能正常播放
启动VisualDL试听音频样本
启动步骤:
-
切换到「可视化」指定可视化日志文件
- 日志文件选择 ‘audio’
-
点击「启动VisualDL」后点击「打开VisualDL」,即可查看可视化结果:

至此,我们向大家展示了如何在AI Studio上使用VisualDL进行:
- 实时训练参数可视化
- 多组实验结果对比
- 训练样本(Image & Audio)中间状态可视化
- 训练过程中每层weights & bias实时可视化
- 每一类别的Precision & Recall的展示
- 网络结构可视化
当然,VisualDL不止支持记录案例中的参数(Accuracy/Loss/Weight/Bias),任何训练中产生的参数都可以被记录下来并可视化,欢迎大家尝试各类玩法,激发VisualDL的潜能,并在AI Studio上进行分享,与更多的小伙伴分享告别「黑盒炼丹」的经历~