MultiNet: Real-time Joint Semantic Reasoning for AutonomousDriving
摘要
当大部分语义推理的方法聚焦在提升性能的时候,在这篇文章中我们认为在一些实时应用比如自动驾驶中计算时间非常重要。为了实现这个目标,我们提出了一种联合进行分类、检测和语义分割的方法,形成一个统一的架构,在这种架构中,三个任务的编码器阶段是共享的。我们的方法比较简单,在非常具有挑战性的KITTI数据集上性能也非常好,超过了很多路面分割任务中目前的最好性能。我们的方法非常有效,可以让我们以大于每秒23帧的速率来进行推理。
复现我们结构的训练脚本和训练权重可以在这里找到:https://github.com/MarvinTeichmann/MultiNet
1.介绍
计算机视觉的最新发展让我们越来越清楚了视觉感知在自动驾驶汽车中扮演了一个重要的角色。这最主要是从2012年AlexNet网络【29】引进到深度学习中.从那时起,新的方法的准确率就以一个令人惊讶的速度在增加。主要原因就是更多的数据,更强的计算能力,更好的算法产生了。现在的趋势是,尽可能地增加更多的网络层、创造更深的网络【22】。
尽管性能已经很好了,但是当处理实时应用时,运行时间就会变得很重要。新的硬件加速和(软件加速)压缩,降低准确率,蒸馏等方法都已经被用来加速现在的网络了。
在这篇论文中我们采用了一种非传统的方法,设计了一个能同时完成分类、检测、语义分割网络结构。这是将三个任务包含到一个统一的编码-解码结构中。我们将我们的方法命名为MultiNet。
编码器是一个深层的CNN,产生能够在所有任务中产生丰富的共享特征。这些特征再被以任务为导向的解码器使用,解码器实时产生结果。尤其检测编码器联合了Yolo【45】中快速的回归设计,Faster-RCNN【17】和Mask-RCNN【21】调整尺寸的ROI对齐,从而达到了一个更好的速度-精度。
我们在具有挑战性的KITTI【15】任务中验证了我们方法的有效性,在路面分割任务中展示我们的最新性能。更为重要的是,我们的ROI-align实施显著地提升了检测性能,它不需要一个明显的提议生成网络(RPN)。这就使得我们的解码器相对于Faster-RCNN【46】有一个很大的速度提升。我们的方法受益于共享计算,使得我们在45ms以内完成所有任务的推理。
2.相关工作
在这一部分,我们回顾了MultiNet所处理任务(检测、分类、语义分割)的当前方法。我们将我们的注意力集中在这些深度学习方法。
分类: 在AlexNet【29】提出之后,大部分现代的图像分类方法都是使用深度学习。残差网络【22】是这方面的最新成果,它允许我们训练深度网络,消除了梯度消失梯度爆炸的问题。在路面分类的场景中,深度神经网络已经被广泛地应用了【37】。传感器融合在这种场景中也被应用地很多【50】。在这篇文章中,我们使用分类来引导其他语义任务,比如分割和检测。
检测: 传统的完成物体检测的深度学习方法遵循两步:第一步生成区域提议【31, 25, 24】,第二步用卷积网络对这些区域进行评分挑选【18, 46】。使用卷积神经网络或者是3D推理【6, 5】来生成区域提议可以提升性能【10,46】。最近提出来一些使用单个端到端训练、直接检测的深度网络【51,33,53,33】.它们对于区域提议的方法的优势在于它们的训练和推理时间更快,因此对实时应用来说更合适。但是,到目前为止它们在性能方面还差的很远。在这篇文章中,我们提出一个端到端训练的检测器,显著减少了区域提议方法和单个深度网络方法之间性能差距。我们认为区域提议方法的主要优势在于它们有尺寸可调整的特征图。这启发了我们进行ROI 池化步骤。
分割: 受深度学习方法的成功所启发,基于CNN的分类器也被用到语义分割任务中去。早期的方法使用一个CNNs的天生的高效性(稀疏连接,参数共享,局部相关)来完成一个隐式的滑动窗口(逐块分类或逐像素分类)【19,32】。FCN被提出来后,使用一种深度学习的pipeline对语义分割进行建模,可以端到端地进行训练(???)。转置卷积【58,9,26】被用来对低分辨率的特征图进行上采样。多种多样的网络层次更深的FCN在【1, 40, 47, 42】中被提出来了。联合FCN和条件随机场(CRFs)可以达到一个很好的结果【60,3,4】。【60,49】显示CRF中的mean-field 推理可以实现一个端到端训练的循环网络。Dialted convolutions在【56】(???)中引入,可以增强感受野大小,却不丢失分辨率。前面所提及的这些技术和残差网络【22】结合在一起往往能达到目前的最好结果。
多任务学习:多任务学习技术目的是在多个任务中学到一个更好的representation。一些多任务场景中的CNNs被提出来了【36,34】。多任务学习的一个重要应用就是人脸识别【59,55,44】.
为了完成检测或者是实例分割,学习语义分割在【16,7,43】中已经被研究了。在这些系统中,主要的目标是实例级别的任务。语义标注只是被看做是中间结果。很多系统可以fine-tuned来完成分类、检测、语义分割【51,54】.在这些(51,54)方法中,对于每一个任务去学习一个不同的参数组。因此,在这些模型中共同推理就不可能。【20】中描述的系统最接近我们的模型【20】.但是【20】依赖现有的目标检测器,也没有全面利用在分割阶段学习到的丰富特征。我们觉的我们的系统是第一个能这样做到的系统。
3.共同完成语义推理的MultiNet
在这篇文章中我们提出了一个高效并且有效的前馈网络,我们称之为MultiNet,来完成与语义分割、图像分类和物体识别。我们的方法在三个任务上和三个分支上共享编码器,但是对每一个任务上有一个单独的解码器。Figure2展示了我们的网络结构。
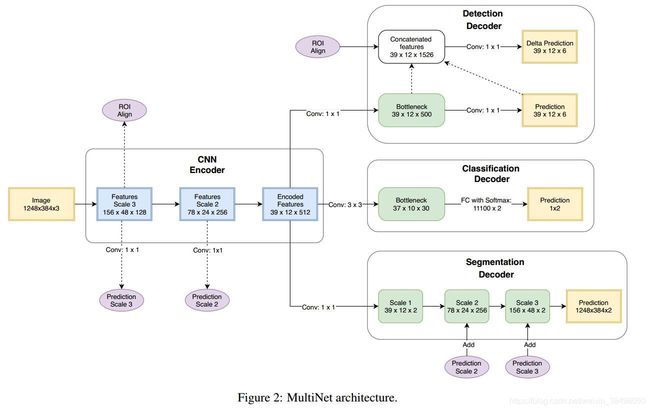
MultiNet可以端到端地进行训练,在所有任务上进行一次推理时间是45ms以内。我们接下来讨论我们的共享编码器,之后是特定任务的解码器。
3.1 编码器
编码器的任务是去处理一张图片,提取丰富抽象的特征,这些特征包含所有完成精确的分割、检测和图像分类的信息。编码器包含分类网络的卷积和池化层。编码器的权重使用在ImageNet分类数据上预训练的权重来进行初始化【48】.在编码阶段,任何现代的分类网络都可以使用。
我们使用VGG16【57】和ResNet【22】网络来进行实验。VGG编码器使用了VGG16的所有卷积和池化层,没有用全连接层和softmax层。我们称这个为版本的网络为VGG-pool5,因为pool5是从VGG16中用到的最后一层。第二个版本值舍弃了最后一个全连接softmax层。我们称这个结构为VGG-fc7,因为fc7是从VGG16中用到的最后一层。VGG-fc7用了VGG16的两个全连接层fc6,fc7。我们用在【51,35】讨论的等价的11卷积来代替这两层。这个trick使得我们的编码器可以处理任意输入尺寸的图片。我们不再需要原始的=VGG网络的输入224224,这个输入对于街道场景预测来说太小。
对于ResNet,我们使用了这个网络的50层和101层的版本。作为编码器,我们使用除了全连接soft-max之外的所有层。
3.2分类解码器
我们实施了两个分类解码器。一个版本是一个vanilla型的带有softmax激活函数的全连接层(解码器),解码器的输入尺寸是224*224.因此,整体网络和原始的VGG或ResNet网络相同,当它们(的一部分)作为相应的编码器(一部分作为解码器)的时候。编码器的意图是作为一个high quality baseline来展示我们场景分类网络的有效性(????)。第一个分类编码器(????)不能用来和分割、检测来进行联合推理。两种任务(分割、检测)都要求一个更大的输入尺寸。但是对分类编码器来说增加输入尺寸会使得最后一层的参数数量得到一个不合理的增加。
第二个分类解码器是被设计来充分利用编码阶段生成的高分辨率特征。在典型的图像分类任务比如【48, 28】,输入的特点是只有一个物体,通常非常显著地(该物体)位于图像中央。对于这种任务来说,使用小尺寸的输入是合理的。街道场景就是另一方面了,包含大量的小尺寸的物体。我们认为为了利用那些物体提供的特征,使用高分辨率的输入很重要。通过将输入尺寸增加到1248348,我们可以有效地在图像的每一个空间位置上使用我们的特征生成器【51,35】.结果就是一个3912的特征网格,每一个网格与一个尺寸是3232像素的空间区域相关。为了利用这些特征,我们使用一个带有30个通道的11卷积。这个(卷积)层称为BottleNeck。主要的意图是进行降维。
3.3检测解码器
检测解码器是设计为一个类似于ReInspect【53】,Yolo【45】和Overfeat【51】一样的无区域(提议阶段)的方法。通过去除设计智能区域生成器,可以获得一个更快的推理时间。这对于我们构建一个实时检测系统来说很重要。
基于区域的检测系统相对于非区域的来说,有一个很大的优势。它们在内部放缩用来检测的特征(图)。这使得CNN在内部对放缩具有不变性。这是一个很重要的特征,因为CNN本质上对不同的尺寸来说是不能泛化地很好的。我们认为尺寸不变性是基于区域提议系统的主要优势。
我们的检测解码器尽力去结合基于区域提议的检测系统的优越检测性能和非区域提议系统的快速性。为了实现这个,我们在解码器内部使用了一个放缩层。放缩层包含一个ROI对齐【21】,提供了基于提议系统的主要优点。不像基于提议的系统,no non-differential operations are done and the rescaling can be computed very effciently(?????)所有操作都是可微的,重新放缩也可以高效地进行计算.
解码器的第一步是产生一个大致边界框的估计。为了实现这个,我们首先将编码好的特征传递给一个有500个卷积核的11卷积层,产生一个尺寸为3912500的张量。这些特征被称为bottleneck块。这个张量再被一个11的卷积层处理,输出6通道分辨率为3912的特征图。我们称这个张量为prediction块,张量的各个值有不同的实际意义。张量的前两个通道值形成了对图像的粗糙的分割。它们的值代表了在3912网格上一个ROI是否出现。其余的 四个通道代表在这个单元格(所代表)区域的坐标。Figure3展示了一个带有cells的图像。

这种预测再被用来引入尺度不变性。A Rescaling Approach,和基于区域提议的系统里的方法有点类似,被用在这比较粗糙的预测上。The rescaling layer用到了【21】中的ROI align方法。实际上它是使用每一个单元格的预测来产生一个RoI align.这使得这些操作都是可微的(???)。再之后进行CNN池化。最终的结果就是一个可训练的端到端快速系统。通过RoI align池化之后的特征与原来的预测串联在一起,用来产生一个更准确的预测。第二个预测用来对边界框的offset进行建模预测,它的输出被加到原来的预测上。
3.4分割解码器
分割解码器遵循FCN的主体结构【35】.在编码器产生的特征的基础上,我们再使用一个11卷积层已经得到了一个低分辨率尺寸为3912的分割。输出再使用三个转置卷积层进行上采样【9】. skip connections被用来从低层中提取高分辨率的特征。这些高分辨率的特征先用一个1*1卷积层进行处理,再加到the partially unsampled results.
4.训练
在这一部分我们描述我们用到的损失函数,训练过程中的细节,包括初始化。
MultiNet训练策略:MultiNet训练用的是一个fine-tunning的方法。首先编码网络在ILSVRC2012数据集【8】训练完成分类。实际当中,这一步被省略。我们直接使用原作者训练发布出来的权重数据就可以了。
在第二步中,去除最后的全连接层,取而代之的是我们的解码器。然后网络用KITTI数据进行端到端的训练。因此MultiNet的训练过程遵循一个经典的fine-tunning pipeline。
我们的联合训练用三个任务它们各自的样本计算前向传播。各自的梯度在反向传播过程中仅仅是加在一起。这样做的实际好处是我们可以给每一个解码器使用不同的训练参数。对于我们的联合训练来说这是一个重要的特点。相对于分割任务来说,分类任务要求一个比较大的batch size和更多的data-augmentation。
损失函数:分类和分割使用softmax交叉熵损失函数进行训练。
对于检测来说,最后一层的预测是一个12*39的网格预测。每一个网格有一个置信度和一个边界框预测。边界框预测包含边界框的4个坐标,与网格的相对位置有关。一个网格比如c会获得一个正的置信度,如果它当且仅当与至少一个真实边界框相交。如果多个边界框与一个网格相交,中心越靠近网格c的边界框会被选中。因此我们可以注意到一个单元格可以被多个网格进行预测。
如果一个边界框是由网格c来进行预测,下列值会保存在c这个单元格内:

其中x_b, y_b和x_c,y_c是边界框b,网格c的中心点坐标,w和h代表宽度和高度。注意到w_c和h_c都是32(这里32是怎么计算出来的,输入是384×1248时,划分为12×39的网格,每一个网格就刚好是32×32),我们模型中网格的长宽因此就是固定值。我们使用L1损失:

其中c^是预测网格,c是真实值网格,c_p代表这个预测网格是否有一个正的置信度预测。Sigma*c_p项可以确保当该网格内没有物体时,回归损失为零。我们使用交叉熵训练置信度预测。每个网格的损失是这个网格的置信度和回归损失的加权和。每幅图像的损失是所有网格损失和的均值。KITTI数据集包括"Don’t care areas".那些Don’t care areas通过将它们的损失乘以0(过滤)处理。我们注意到我们的最终预测的表达形式比Faster-RCNN 或ReInspect都简单。这是我们的检测系统的一个额外特点。MultiNet的损失就是分割、检测和分类的损失和。
联合训练的损失也是分割、检测和分类的损失和。
初始化:编码器的权重使用在ImageNet数据上【23】训练的权重。检测和分类的解码器权重使用【23】中的方法来初始化。分割解码器转置卷积层初始化成双线性插值的值。分割解码器的skip connections初始化成很小的权重。
所有的这些修改都极大地提升了分割性能。
优化和正则化:我们使用Adam优化方法【27】,学习率为10^-5. 所有层的权重衰减率是510^-4,dropout的概率是0.5,dropout只用到33的分类卷积和所有检测解码器中的所有1*1卷积。
标准的数据增广被用来增加有效可用训练数据的数量。我们通过使用随机亮度和随机对比度来增广数据的颜色特征。空间特征通过使用随机反转,随机resize和随机裁剪来进行扭曲增广。
5.实验结果
在这一部分,我们在具有挑战性的KITTI数据集上完成实验验证。
5.1数据集
我们在KITTI视觉基准数据集上【14】验证MultiNet。这个基准数据集包括在Karlsruhe城市里移动车辆采集的多样化场景数据集。原始的数据里,KITTI有自动驾驶相关任务的数据标注。我们使用路面标准数据【12】来评估我们语义分割解码器的性能,物体检测标准数据【15】来评估检测解码器。我们利用自动生成的标签【37】,它通过使用GPS信息和公开街道地图数据提供给我们路面标签。
检测性能通过average precision score【11】来进行评价。为了评估,物体被分成三类:容易,适中,困难。分割性能通过MaxF1 score【12】来衡量。另外,average precision score用来作参考。分类性能通过计算mean accuracy, precision和recall来评估。
5.2 实验验证
这一部分结构如下。我们首先单独评估三个解码器的性能。为了实现这个,我们通过使用三个损失分割、检测和分类中的一个fine-tune编码器,与很多基准指标比较来评价性能。第二部分,我们比较三个解码器联合训练(时间)和单独推理(时间),从中我们得出联合训练的性能赶上了单独推理的性能。总体上,我们的方法与单独推理相比也是很有竞争性的。This makes our approach very relevant. 联合训练在很多机器人应用中很有好处,比如快速的推理时间。