时间序列分析的七种方法
7 methods to perform Time Series forecasting
- Method 1 – Start with a Naive Approach
- Method 2 – Simple average
- Method 3 – Moving average
- Method 4 – Single Exponential smoothing
- Method 5 – Holt’s linear trend method
- Method 6 – Holt’s Winter seasonal method
- Method 7 – ARIMA
import pandas as pd
import numpy as np
import matplotlib.pylab as plt
%matplotlib inline
# 解决坐标轴刻度负号乱码
plt.rcParams['axes.unicode_minus'] = False
# 解决中文乱码问题
plt.rcParams['font.sans-serif'] = ['Simhei']
from matplotlib.pylab import rcParams
rcParams['figure.figsize'] = 18, 6
import warnings
warnings.filterwarnings("ignore")
数据:1981-1990年澳大利亚墨尔本每日最低温度
#Importing data
df = pd.read_csv('Train_SU63ISt.csv')
#Printing head
df.head()
| ID | Datetime | Count | |
|---|---|---|---|
| 0 | 0 | 25-08-2012 00:00 | 8 |
| 1 | 1 | 25-08-2012 01:00 | 2 |
| 2 | 2 | 25-08-2012 02:00 | 6 |
| 3 | 3 | 25-08-2012 03:00 | 2 |
| 4 | 4 | 25-08-2012 04:00 | 2 |
#Printing tail
df.tail()
| ID | Datetime | Count | |
|---|---|---|---|
| 18283 | 18283 | 25-09-2014 19:00 | 868 |
| 18284 | 18284 | 25-09-2014 20:00 | 732 |
| 18285 | 18285 | 25-09-2014 21:00 | 702 |
| 18286 | 18286 | 25-09-2014 22:00 | 580 |
| 18287 | 18287 | 25-09-2014 23:00 | 534 |
#Subsetting the dataset
#Index 11856 marks the end of year 2013
df = pd.read_csv('Train_SU63ISt.csv', nrows = 11856)
#Creating train and test set
#Index 10392 marks the end of October 2013
train=df[0:10392]
test=df[10392:]
#Aggregating the dataset at daily level
df.Timestamp = pd.to_datetime(df.Datetime,format='%d-%m-%Y %H:%M')
df.index = df.Timestamp
df = df.resample('D').mean()
train.Timestamp = pd.to_datetime(train.Datetime,format='%d-%m-%Y %H:%M')
train.index = train.Timestamp
train = train.resample('D').mean()
test.Timestamp = pd.to_datetime(test.Datetime,format='%d-%m-%Y %H:%M')
test.index = test.Timestamp
test = test.resample('D').mean()
#Plotting data
train.Count.plot(figsize=(18,8), title= 'Daily Ridership', fontsize=14)
test.Count.plot(figsize=(18,8), title= 'Daily Ridership', fontsize=14)
plt.show()
[外链图片转存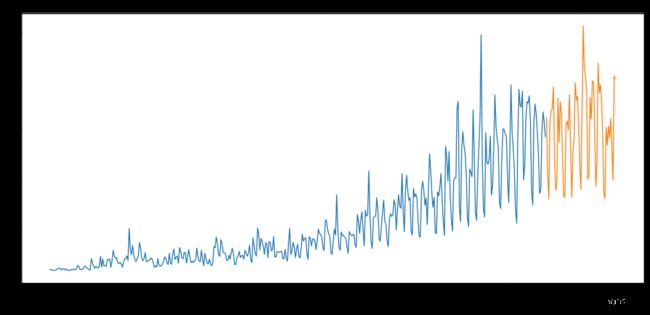 (img-bVsS038e-1562729709187)(output_8_0.png)]
(img-bVsS038e-1562729709187)(output_8_0.png)]
Method 1: Start with a Naive Approach
**Naive Method:**简单地将最近一个观测值作为下一期的预测值来做预测
[外链图片转存失败(img-ICzME1oI-1562729709188)(attachment:image.png)]
dd= np.asarray(train.Count)
y_hat = test.copy()
y_hat['naive'] = dd[len(dd)-1]
plt.figure(figsize=(18,8))
plt.plot(train.index, train['Count'], label='Train')
plt.plot(test.index,test['Count'], label='Test')
plt.plot(y_hat.index,y_hat['naive'], label='Naive Forecast')
plt.legend(loc='best')
plt.title("Naive Forecast")
plt.show()
[外链图片转存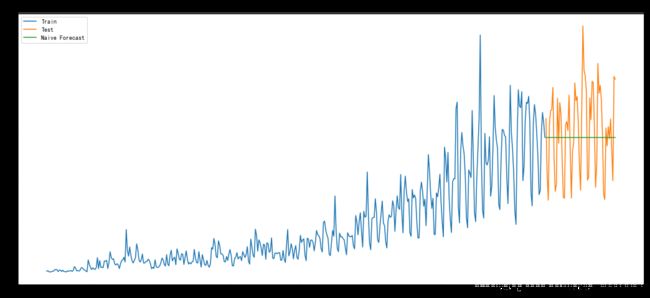 (img-Gbx6dI6V-1562729709188)(output_10_0.png)]
(img-Gbx6dI6V-1562729709188)(output_10_0.png)]
from sklearn.metrics import mean_squared_error
from math import sqrt
rms = sqrt(mean_squared_error(test.Count, y_hat.naive))
print(rms)
# RMSE = 43.9164061439
43.91640614391676
Method 2: – Simple Average
**Simple Average:**用历史全部观测值的均值作为下一期的预测值来做预测
[外链图片转存失败(img-PJRCQxAw-1562729709189)(attachment:image.png)]
y_hat_avg = test.copy()
y_hat_avg['avg_forecast'] = train['Count'].mean()
plt.figure(figsize=(18,8))
plt.plot(train['Count'], label='Train')
plt.plot(test['Count'], label='Test')
plt.plot(y_hat_avg['avg_forecast'], label='Average Forecast')
plt.legend(loc='best')
plt.show()
[外链图片转存 (img-hJ9bhiV6-1562729709189)(output_13_0.png)]
(img-hJ9bhiV6-1562729709189)(output_13_0.png)]
rms = sqrt(mean_squared_error(test.Count, y_hat_avg.avg_forecast))
print(rms)
# RMSE = 109.545990803
109.88526527082863
Method 3 – Moving Average
移动平均法用近期固定期数的历史观测值的均值作为下一期的预测值来做预测
[外链图片转存失败(img-joYQ58fO-1562729709189)(attachment:image.png)]
y_hat_avg = test.copy()
y_hat_avg['moving_avg_forecast'] = train['Count'].rolling(60).mean().iloc[-1]
plt.figure(figsize=(18,8))
plt.plot(train['Count'], label='Train')
plt.plot(test['Count'], label='Test')
plt.plot(y_hat_avg['moving_avg_forecast'], label='Moving Average Forecast')
plt.legend(loc='best')
plt.show()
[外链图片转存 (img-uV2GHixM-1562729709189)(output_16_0.png)]
(img-uV2GHixM-1562729709189)(output_16_0.png)]
rms = sqrt(mean_squared_error(test.Count, y_hat_avg.moving_avg_forecast))
print(rms)
# RMSE = 46.7284072511
46.72840725106963
Weighted moving average
加权移动平均法
[外链图片转存失败(img-RhPeTgZ1-1562729709190)(attachment:image.png)]
Method 4 – Simple Exponential Smoothing
[外链图片转存失败(img-422QEAx8-1562729709190)(attachment:image.png)]
[外链图片转存失败(img-VKsPCRNi-1562729709190)(attachment:image.png)]
"""
在这儿:https://github.com/statsmodels/statsmodels/tree/master/statsmodels/tsa 下载holtwinters.py,
放在当前脚本所在路径下,将tsamodel.py,放在当前脚本所在路径下
"""
import sys, os
sys.path.append(os.getcwd())
from statsmodels.tsa.holtwinters import ExponentialSmoothing, SimpleExpSmoothing, Holt
y_hat_avg = test.copy()
fit2 = SimpleExpSmoothing(np.asarray(train['Count'])).fit(smoothing_level=0.6,optimized=False)
y_hat_avg['SES'] = fit2.forecast(len(test))
plt.figure(figsize=(18,8))
plt.plot(train['Count'], label='Train')
plt.plot(test['Count'], label='Test')
plt.plot(y_hat_avg['SES'], label='SES')
plt.legend(loc='best')
plt.show()
[外链图片转存 (img-mTTxABPn-1562729709190)(output_25_0.png)]
(img-mTTxABPn-1562729709190)(output_25_0.png)]
rms = sqrt(mean_squared_error(test.Count, y_hat_avg.SES))
print(rms)
# RMSE = 43.3576252252
43.357625225228155
Method 5 – Holt’s Linear Trend method
[外链图片转存失败(img-jGMgIePX-1562729709191)(attachment:image.png)]
import statsmodels.api as sm
sm.tsa.seasonal_decompose(train.Count).plot()
result = sm.tsa.stattools.adfuller(train.Count)
plt.show()
[外链图片转存 (img-HxL5F7UP-1562729709191)(output_29_0.png)]
(img-HxL5F7UP-1562729709191)(output_29_0.png)]
y_hat_avg = test.copy()
fit1 = Holt(np.asarray(train['Count'])).fit(smoothing_level = 0.3,smoothing_slope = 0.1)
y_hat_avg['Holt_linear'] = fit1.forecast(len(test))
plt.figure(figsize=(18,8))
plt.plot(train['Count'], label='Train')
plt.plot(test['Count'], label='Test')
plt.plot(y_hat_avg['Holt_linear'], label='Holt_linear')
plt.legend(loc='best')
plt.show()
[外链图片转存 (img-ydYINjlI-1562729709191)(output_30_0.png)]
(img-ydYINjlI-1562729709191)(output_30_0.png)]
rms = sqrt(mean_squared_error(test.Count, y_hat_avg.Holt_linear))
print(rms)
# RMSE = 43.0562596115
43.056259611507286
Method 6 – Holt-Winters Method
[外链图片转存失败(img-EWPH92cP-1562729709192)(attachment:image.png)]
y_hat_avg = test.copy()
fit1 = ExponentialSmoothing(np.asarray(train['Count']) ,seasonal_periods=7 ,trend='add', seasonal='add',).fit()
y_hat_avg['Holt_Winter'] = fit1.forecast(len(test))
plt.figure(figsize=(18,8))
plt.plot( train['Count'], label='Train')
plt.plot(test['Count'], label='Test')
plt.plot(y_hat_avg['Holt_Winter'], label='Holt_Winter')
plt.legend(loc='best')
plt.show()
[外链图片转存 (img-zbjucRo2-1562729709192)(output_34_0.png)]
(img-zbjucRo2-1562729709192)(output_34_0.png)]
rms = sqrt(mean_squared_error(test.Count, y_hat_avg.Holt_Winter))
print(rms)
# RMSE = 23.9614925662
23.961492566159794
Method 7 – ARIMA
min(train.index), max(train.index),train.shape
(Timestamp('2012-08-25 00:00:00', freq='D'),
Timestamp('2013-10-31 00:00:00', freq='D'),
(433, 2))
min(test.index), max(test.index), test.shape
(Timestamp('2013-11-01 00:00:00', freq='D'),
Timestamp('2013-12-31 00:00:00', freq='D'),
(61, 2))
from pandas import datetime, date_range
start_index = datetime(2013, 11, 1).date()
end_index = datetime(2013, 12, 31).date()
start_index, end_index
(datetime.date(2013, 11, 1), datetime.date(2013, 12, 31))
y_hat_avg = test.copy()
fit1 = sm.tsa.statespace.SARIMAX(train.Count, order=(2, 1, 4),seasonal_order=(0,1,1,7)).fit()
# y_hat_avg['SARIMA'] = fit1.predict(start="2013-11-1", end="2013-12-31", dynamic=True)
# y_hat_avg['SARIMA'] = fit1.predict(start=start_index, end=end_index, dynamic=True)
y_hat_avg['SARIMA'] = fit1.predict(start=433, end=494, dynamic=True)
plt.figure(figsize=(18,8))
plt.plot(train['Count'], label='Train')
plt.plot(test['Count'], label='Test')
plt.plot(y_hat_avg['SARIMA'], label='SARIMA')
plt.legend(loc='best')
plt.show()
[外链图片转存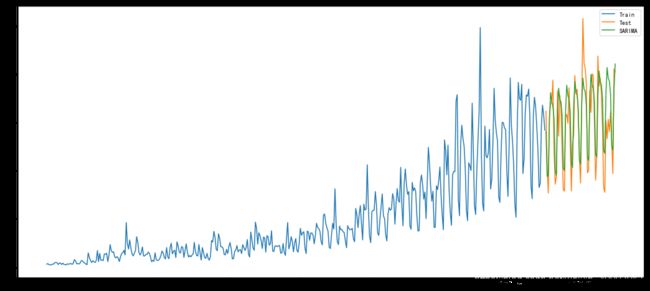 (img-bbHgTnPm-1562729709192)(output_41_0.png)]
(img-bbHgTnPm-1562729709192)(output_41_0.png)]
rms = sqrt(mean_squared_error(test.Count, y_hat_avg.SARIMA))
print(rms)
# RMSE = 25.952261782952643
26.052705330843708