基于深度学习的轴承故障识别-优化模型
在深度学习的训练中,常常会遇到过拟合(overfitting)的问题(低偏差和高方差),模型为了适应训练集的数据拟合出了非常复杂的曲线,该曲线对于训练集的数据识别率极高,但泛化能力差,对于不同于训练集的测试数据执行起来表现很差,准确率大幅降低。
抑制过拟合有几种方式:1.获取更多的样本,例如数据增强技术;2.丢弃一些特征以获得更好地容错能力,例如Dropout机制;3.保留所有的特征,但是减少参数,确保所有的特征都对实际性能有贡献,例如通常所用的L1、L2正则化技术;4.在模型训练即将过拟合时提前终止训练或根据过往经验修改模型的部分参数。以上方法概括一下就是,增加优化约束的能力或干扰优化过程。
在构建深度学习模型的时候,会遇到诸如应该堆叠多少层网络层、每层包含多少单元、激活函数用哪一种函数、Dropout丢弃率应该选择多少这类的问题,这些在架构层面的参数为了区别于模型反向传播时会自动优化的参数,通常被称为超参数(hyperparameter)。对于超参数的调节并没有成文的规则,只能依靠直觉或经验来判定,一般会先随机选择一组超参数,将模型在训练数据上拟合,观察验证数据上的模型性能,然后不断尝试不同的超参数进行比对,最终确定最合适的模型,在测试数据上测试模型的最终性能。
目录
1.经验正则化
2.参数正则化
3.激活函数
4.Dropout
5.批标准化
1.经验正则化
通过工程上的实际经验来实现更低泛化误差的方法被称之为经验正则化,主要有提前终止和模型集成两种方法。提前终止,顾名思义就是在模型即将过拟合时提前终止训练。模型集成(ensemable method)是通过训练不同网络结构、不同激活函数、不同数据集训练等方法,对多个模型进行投票抉择的策略。
本文选择待定卷积层层数、全连接层层数和每层大小,并对三者不同组合的故障识别能力通过验证集上的结果进行比对,选择最优的搭配。通过以下代码来测试全连接层0-2层、卷积层1-3层、每层大小32/64/128时共3的3次方 =27种排列组合中性能最优的模型。
程序运行完后,在TensorBoard的可视化界面中可以观察27种模型的检测结果,也可以以csv的格式导出实验数据,导出的数据生成折线图如下图所示。在验证集上,不同模型的损失率和准确率差异较大,多数模型大体趋势比较相近。
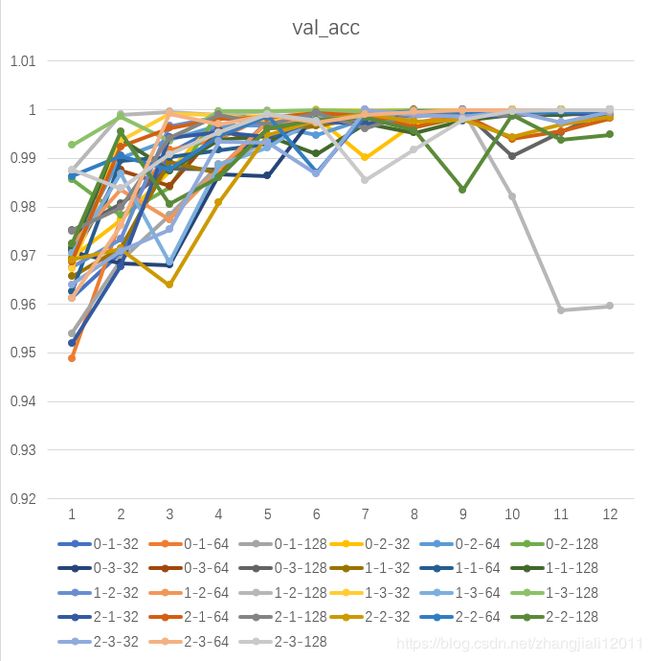
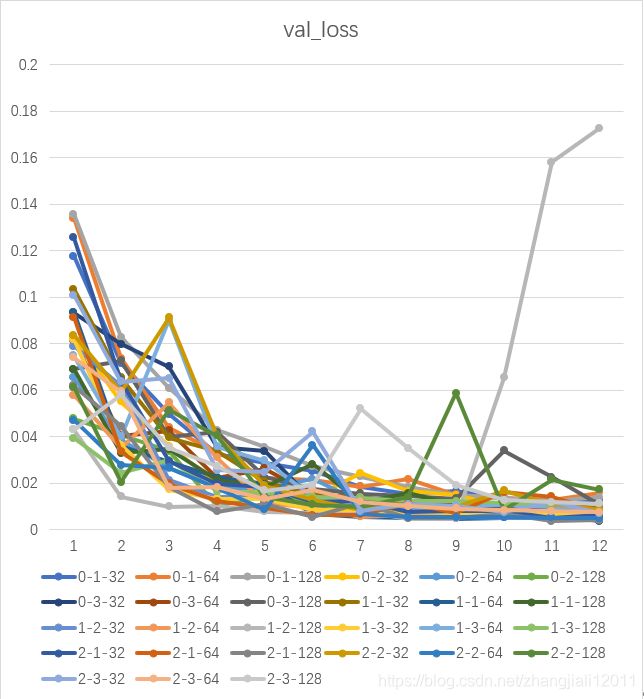
上图的标签是全连接层层数-卷积层层数-节点个数的简写。综合考虑用时及准确率和损失率的表现,由于2卷积层-32个节点-1全连接层的模型在验证集上准确率和损失率都较优,且训练用时最短,最终选定模型为2卷积层-32个节点-1全连接层的CNN模型作为轴承故障识别的模型。
2.参数正则化
L1、L2正则化方法是最常用的参数正则化方法,L1通常又被称为Lasso回归,L2为岭回归(Ridge回归),二者都是对回归损失函数加一个约束形式,L1、L2正则化的本质是范数约束。
参数正则化可以有效降低模型的复杂度,抑制过拟合。L1正则化会产生大量的0参数使得参数的数量减少,即产生一个稀疏模型,通常用于特征选择。L2正则化又称权重衰减,减低了参数之间的差距,使参数变的更平滑,模型能适应更多的数据集,所以抑制过拟合通常都会选用L2正则化。
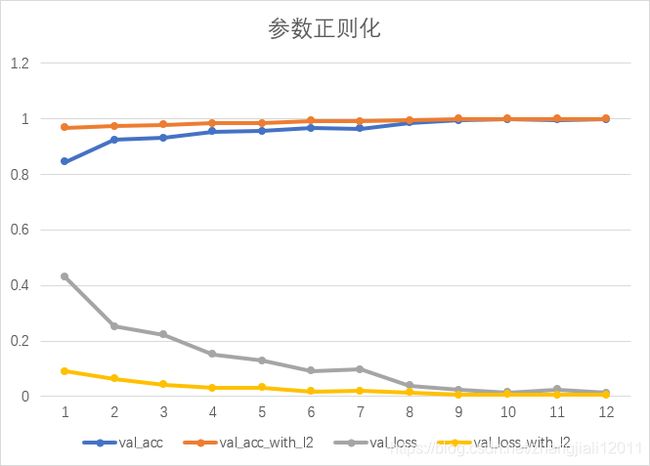 添加L2正则化对识别率的影响
添加L2正则化对识别率的影响
3.激活函数
激活函数可以保证神经网络的非线性。在神经网络发展早期,sigmoid函数应用较多,在AlexNet出现以后,ReLU函数因其不容易产生梯度消失的优点,逐步取代之前常用的激活函数并成为最广泛应用的激活函数。
ReLU函数的神经元计算上更加高效,并且具有很好的稀疏性,更加接近实际生物神经网络,同一时间约有一半的神经元会处在激活状态。在优化上,很多激活函数会将输出值约束在很小的区间内,在激活函数两端较大范围的定义域内梯度为0,造成学习停滞,产生梯度消失,导致权值更新缓慢,训练难度上升,而ReLU函数为左饱和函数,x>0时导数为1,可以缓解神经网络梯度消失的问题,加速梯度下降的收敛速度。但同时ReLU函数也有一些缺点,它会给后一层的神经网络引入偏置偏移,还容易在参数不恰当的更新后导致后续神经元永远无法激活,这个问题被称为Dying ReLU Problem。为了解决上述问题,ReLU产生了一些变种,例如Leaky ReLU、PReLU、ELU等。
在本文构建的卷积神经网络中尝试三种不同的激活函数,观察对模型的优化作用。
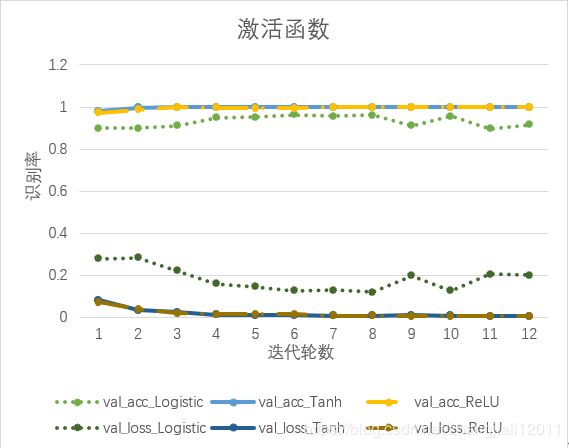
| 激活函数 |
val_acc |
val_loss |
训练时间 |
| Logistic |
0.9154 |
0.2015 |
51s |
| Tanh |
1 |
6.3747e-3 |
49s |
| ReLU |
1 |
4.4998e-3 |
49s |
由上图可以看出,Logistic函数在本文模型上效果最差,准确率最低、损失率最高且用时最长。ReLU函数和Tanh函数效果相近,用时也一样,但从验证集的损失率上看,ReLU函数的效果略优于Tanh函数。因此本文选择ReLU函数作为激活函数。
4.Dropout
Dropout也叫丢弃法,是深度学习中常用的既简单又有效的正则化技术,可以有效抑制神经网络模型的过拟合。Dropout由Srivastava等人于2014年提出,他们针对深度神经网络参数过多导致的过拟合及训练速度缓慢的问题,提出Dropout方法,即在训练过程中,随机丢弃一部分神经元及对应的连接边,以阻止神经元之间过多的相互适应。这种方法提高了神经网络在视觉分析、语音识别、数据分类等领域的性能。
5.批标准化
了便于后续处理,提升模型性能,通常会将数据集统一到同一分布。否则多次参数更新后,各层的数据分布会变化的非常明显,不停地变化会为模型训练带来困难,深层网络需要为了适应数据分布的变化不断调整参数。
标准化(normalization)是最基础的方法,可以使模型数据分布更紧密,有助于提升模型的泛化能力。最常见的数据标准化形式就是将数据向平均值靠拢,使分布的中心为0,与此同时将方差缩放到1。
批标准化(batch normalization)是Ioffe和Szegedy在2015年ICML会议上提出的一种层的类型,在训练过程中均值和方差不断变化的情况下也可以保持数据标准化。其原理是训练过程中在内部保存已读取每批数据均值和方差的指数移动平均值。
Ioffe于2017年又提出了改进的批量重整化(batch renormalization),可以确保模型产生相同的输出,相比批标准化更有优势,尤其是在处理小型训练时效果更优秀,且代价没有明显增加。
批标准化通常用于模型中激活函数之前,规范前面网络层数据的分布,然后经过激活函数的非线性映射得到网络层的输出。
在本文构建的模型中添加批标准化项,并在验证集上与之前未加批标准化项的识别率进行对比。
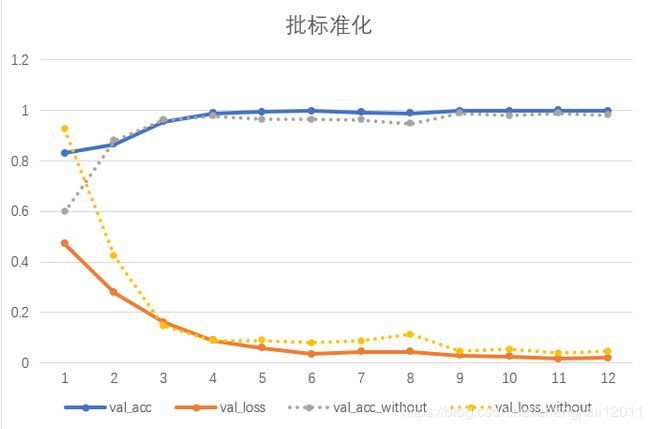
由上图可以看出,很明显添加了批标准化项后,准确率上升,损失率下降。批标准化可以规范不同网络层的数据,本文在卷积层的激活函数之前添加批标准化项。
经过一系列优化后,最终构建的神经网络基本参数如下。
| 编号 |
网络层 |
卷积核数目 |
窗口大小 |
步长/池化层缩小比例因数 |
输出大小 |
非零填充 |
激活函数 |
正则化 |
| 1 |
卷积层 |
16 |
64×1 |
16×1 |
128×16 |
same |
relu |
l2 |
| 2 |
池化层 |
|
2×1 |
2 |
64×16 |
valid |
|
|
| 3 |
卷积层 |
32 |
3×1 |
1×1 |
64×32 |
same |
relu |
l2 |
| 4 |
池化层 |
|
2×1 |
2 |
32×32 |
valid |
|
|
| 5 |
展平 |
|
|
|
1024 |
|
|
|
| 6 |
全连 接层 |
|
|
|
32 |
|
relu |
l2 |
| 7 |
输出层 |
|
|
|
10 |
|
softmax |
l2 |
点击此处返回总目录:基于深度学习的轴承故障识别