Flink-dataStream的种类和基本使用
Flink-dataStream的种类和基本使用
- map
- flatMap
- filter
- keyBy
- keyBy使用元组
- keyBy自定义Bean
- keyBy多字段分组
- reduce
- max/min
官方案例以及说明地址:
官方案例
map
取一个元素并产生一个元素。一个映射函数,将输入流的值加倍
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment environment = StreamExecutionEnvironment.getExecutionEnvironment();
DataStreamSource<Integer> dataStreamSource = environment.fromElements(1, 9, 4, 2, 8);
// 用于映射,取一个元素,并返回一个新的元素,内部实现的是MapFunction
SingleOutputStreamOperator<Integer> dataStream = dataStreamSource.map(i -> i * 2);
// 功能更强大的Map :RichMapFunction,常用的方法有3个。
SingleOutputStreamOperator<Integer> dataStream2 = dataStreamSource.map(new RichMapFunction<Integer, Integer>() {
// 例如:open方法打开数据库连接
// open 在构造方法之后,map方法之前执行,执行一次,一般用于初始化一个连接
@Override
public void open(Configuration parameters) throws Exception {
super.open(parameters);
}
// 对数据库数据进行操作
@Override
public Integer map(Integer integer) throws Exception {
return null;
}
// 一般用于资源释放,如关闭数据库连接
@Override
public void close() throws Exception {
super.close();
}
});
dataStream.print();
environment.execute("MapDemo");
}
结果:
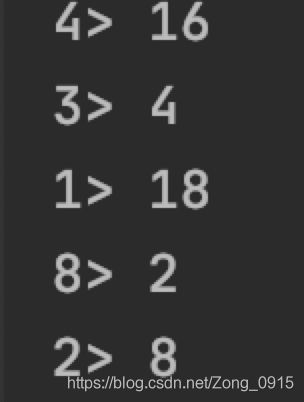
flatMap
取一个元素并产生零个,一个或多个元素。平面图功能可将句子拆分为单词
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStreamSource<String> dataSource = env.fromElements("spark flink hadoop", "spark hello flink flink");
// 方式一:内置函数实现
SingleOutputStreamOperator<String> dataStream = dataSource.flatMap(new FlatMapFunction<String, String>() {
@Override
public void flatMap(String line, Collector<String> out) throws Exception {
// Arrays.stream(line.split(" ")).forEach(out :: collect);
String[] words = line.split(" ");
for (String word : words) {
out.collect(word);
}
}
});
// 方式二:用lambda表达式实现
SingleOutputStreamOperator<String> dataStream2 = dataSource.flatMap(
(String line, Collector<String> out) ->
Arrays.stream(line.split(" ")).forEach(out::collect))
.returns(Types.STRING);
dataStream.print();
env.execute("FlatMapDemo");
}
结果:将文本切分成多个单词
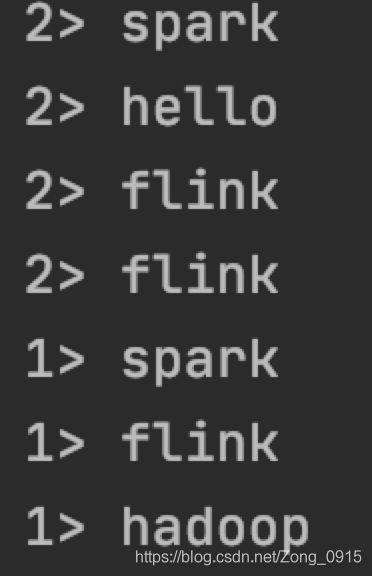
filter
为每个元素评估一个布尔函数,并保留该函数返回true的布尔函数。筛选出零值的筛选器
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment environment = StreamExecutionEnvironment.getExecutionEnvironment();
DataStreamSource<Integer> dataSource = environment.fromElements(1, 2, 3, 4, 5, 6, 7, 8, 9);
// 方式一:实现函数
SingleOutputStreamOperator<Integer> dataStream = dataSource.filter(new FilterFunction<Integer>() {
@Override
public boolean filter(Integer value) throws Exception {
return value % 2 != 0;
}
});
// 方式二:lambda表达式实现
SingleOutputStreamOperator<Integer> dataStream2 = dataSource.filter(i -> i % 2 != 0);
dataStream2.print();
environment.execute("FilterDemo");
}
结果:过滤掉了偶数

keyBy
从逻辑上将流划分为不相交的分区。具有相同键的所有记录都分配给同一分区。在内部,keyBy()是通过哈希分区实现的。
keyBy使用元组
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStreamSource<String> dataSource = env.fromElements("spark", "hello", "spark", "flink", "hive", "flink", "hello");
// 一个单词会变成 (word,1)的形式
SingleOutputStreamOperator<Tuple2<String, Integer>> dataStream =
dataSource.map(word -> Tuple2.of(word, 1))
.returns(Types.TUPLE(Types.STRING, Types.INT));
// java的下标是从0开始的,等于根据单词进行归类,等于把相同单词的个数进行统计
// 两个单词用Tuple2,如果是3个单词一组,可以用Tuple3。。。以此推类
KeyedStream<Tuple2<String, Integer>, Tuple> dataStream2 = dataStream.keyBy(0);
dataStream2.print();
env.execute("KeyByDemo");
}
结果:将单词拼装为根据key进行分组,形成键值对。

keyBy自定义Bean
1.创建一个实体类WordCounts
public class WordCounts {
private String word;
private Long counts;
// 无参、有参。get/set也要
2.代码部分:
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStreamSource<String> dataSource = env.fromElements("spark", "hello", "spark", "flink", "hive", "flink", "hello");
SingleOutputStreamOperator<WordCounts> dataStream = dataSource.map(new MapFunction<String, WordCounts>() {
@Override
public WordCounts map(String value) throws Exception {
return WordCounts.of(value, 1L);
}
});
// 根据word进行分组,这里的名称一定要和Bean当中的属性名称对应,否则报错。
KeyedStream<WordCounts, Tuple> keyedStream = dataStream.keyBy("word");
// 根据counts实现聚合,即累加
SingleOutputStreamOperator<WordCounts> counts = keyedStream.sum("counts");
counts.print();
env.execute("KeyByDemo2");
}
keyBy多字段分组
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStreamSource<String> dataSource = env.fromElements("浙江,杭州,3000", "浙江,杭州,666", "山东,济南,555");
SingleOutputStreamOperator<Tuple3<String, String, Double>> mapStream = dataSource.map(new MapFunction<String, Tuple3<String, String, Double>>() {
@Override
public Tuple3<String, String, Double> map(String line) throws Exception {
String[] fields = line.split(",");
String province = fields[0];
String city = fields[1];
Double money = Double.parseDouble(fields[2]);
return Tuple3.of(province, city, money);
}
});
SingleOutputStreamOperator<Tuple3<String, String, Double>> sumStream = mapStream.keyBy(0, 1).sum(2);
sumStream.print();
env.execute("KeyByDemo3");
}
结果:

reduce
对键控数据流进行“滚动”压缩。将当前元素与最后一个减少的值合并,并发出新值。
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStreamSource<String> dataSource = env.fromElements("spark", "hello", "spark", "spark", "hive", "flink", "hello");
// 一个单词会变成 (word,1)的形式
SingleOutputStreamOperator<Tuple2<String, Integer>> dataStream =
dataSource.map(word -> Tuple2.of(word, 1))
.returns(Types.TUPLE(Types.STRING, Types.INT));
// java的下标是从0开始的,等于根据单词进行归类,等于把相同单词的个数进行统计
// 两个单词用Tuple2,如果是3个单词一组,可以用Tuple3。。。以此推类
KeyedStream<Tuple2<String, Integer>, Tuple> keyedStream = dataStream.keyBy(0);
SingleOutputStreamOperator<Tuple2<String, Integer>> reduce = keyedStream.reduce(new ReduceFunction<Tuple2<String, Integer>>() {
@Override
public Tuple2<String, Integer> reduce(Tuple2<String, Integer> value1, Tuple2<String, Integer> t1) throws Exception {
// f0代表第一个字段,f1代表第二个字段
String key = value1.f0;
Integer counts1 = value1.f1;
Integer counts2 = t1.f1;
// 将结果合并
return Tuple2.of(key, counts1 + counts2);
}
});
reduce.print();
env.execute("KeyByDemo");
}
结果:

max/min
在键控数据流上滚动聚合。min和minBy之间的区别在于min返回最小值,而minBy返回在此字段中具有最小值的元素
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStreamSource<String> dataSource = env.fromElements("a,1", "a,2","b,10","b,3","b,6");
SingleOutputStreamOperator<Tuple2<String, Integer>> map = dataSource.map(new MapFunction<String, Tuple2<String, Integer>>() {
@Override
public Tuple2<String, Integer> map(String line) throws Exception {
String[] s = line.split(",");
String word = s[0];
int nums = Integer.parseInt(s[1]);
return Tuple2.of(word, nums);
}
});
SingleOutputStreamOperator<Tuple2<String, Integer>> max = map.keyBy(0).min(1);
max.print();
env.execute("MaxMinDemo");
}
结果:每次输出,都会根据第二个字段的最小值来互相比较,然后输出那个最小的
max同理
