Keras调研
关于Keras
Keras基于Python编写,是一个高层神经网络API,基于TensorFlow、Theano及CNTK后端。Keras为支持快速实验而生,能把idea迅速转换为结果。
Keras的特性
简单和快速的原型设计(keras具有高度模块化,极简,和扩充特性)
支持CNN和RNN,或二者的结合
无缝CPU和GPU切换
Keras的设计原则
用户友好:用户使用体验极佳,简单的几行代码就可轻松搭建各种神经网络模型
模块性:Keras的模块化程度很高,其中网络层、损失函数、优化器、初始化策略、激活函数、正则化方法等都是独立的模块,可以像搭积木一样的方式来轻松构建自己想要的模型。
易拓展性:只需要仿照现有的模块就可以编写新的类或函数,从而创建自己的新模块。
与Python协作:Keras没有单独的模型配置文件类型(作为对比,caffe有),模型由python代码描述,使其更紧凑和更易debug,并提供了拓展的便利性。
Keras框架组织
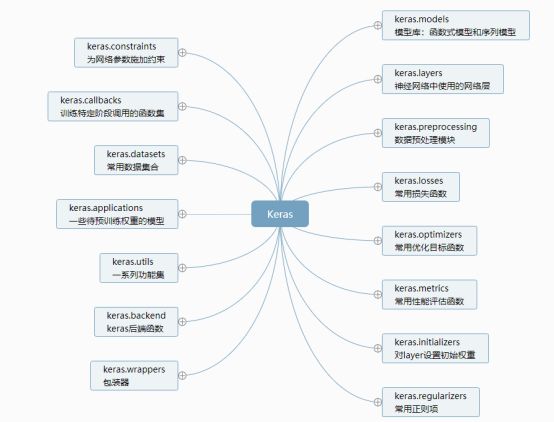
在Keras中,主要被组织为models、layers、preprocessing、losses、optimizers、metrics、initializers、regularizers、constraints、callbacks、datasets、applications、utils、backend等。
其中:
- models定义了Keras的模型,包括函数式模型(Model)和序贯模型(Sequential);
- layers中定义了神经网络中使用的各种网络层,如Dense全连接层,RNN循环神经网络层,Convolutional卷积层、Activation激活层等; preprocessing模块是数据预处理层,包含序列预处理、文本预处理和图片预处理等;
- losses模块包含了一些常用的损失函数,如mse、mae、categorical_crossentropy等,和优化函数一起在编译模型时使用;
- optimizers模块定义了一些常用的优化目标函数,如SGD、RMSprop、Adagrad等,和损失函数一起在编译模型时使用;
- metrics模块中包含一些常用的性能评估函数,如mae、acc、categorical_accuracy等,性能评估函数类似于目标函数,不过该性能的评估结果不会用于训练;
- initializers模块负责对layer设置初始权重,如全零Zeros、Ones全一、RandomNormal正态分布初始化等;
- regularizers模块定义了一些常用的正则项,正则项在优化过程中对层的参数或激活值添加惩罚项,这些惩罚项将与损失函数一起作为网络的最终优化目标,正则项可以选择添加在权重、偏置向量或输出上;
- constraints模块的功能有些类似于regularizers,它的功能是在优化过程中为网络的参数施加约束,如非负、绝对值小于2等,可以选择对主权重矩阵或偏置向量进行约束;
- callbacks模块预定义了一些训练特定阶段调用的函数集,可以用来观察训练过程中的网络内部的状态和统计信息,预定义的回调函数如BaseLogger、History、EarlyStopping、TensorBoard等;
- datasets模块包含了一些常用的数据集合,如IMDB影评倾向分类、MNIST手写数字识别等,可以用来验证训练模型;
- applications包含了一些带预训练权重的模型,主要是应用于图像分类的模型,在数据量较小或任务相似、数据分布类似的场景下比较有用;
- utils模块中定义了一些常用的工具函数,如to_cagegorical、plot_model等;
- backend模块中定义了一些常见的后端函数,由于Keras并不负责处理张量乘法、卷积等底层操作,这些依赖后端的库,而Keras定义了通用的后端函数,避免了直接调用这些库,常用的后端函数如backend、dot、mean、any、sin等;
除此之外,keras的wrappers包装器提供了如Scikit-Learn的接口,可以将Sequential模型传入Scikit-Learn包装器中的分类器或回归器接口完成训练;
序贯模型与函数式模型
在Keras中,模型包括Sequential序贯模型和Model函数式模型,其中函数式模型的应用更加广泛,序贯模型是函数式模型的一种特殊情况。
序贯模型的API在大多数情况下非常适合开发深度学习模型,但也有一些限制。它适合处理一般的单输入、单输出、层次堆叠鲜明的神经网络模型,而并不适合处理多对一、一对多、以及在网络中共享输入层、共享特征提取层等相对复杂、灵活的情况。
模型保存
keras的model模块提供了save(filepath)方法用于保存Keras模型和权重到HDF5文件中
文件包含的内容包括:模型的结构,以便重构改模型、模型的权重、训练配置(损失函数,优化器等)、优化器的状态,以便于从上次训练中断的地方开始 model模块提供了:
- load_model(filepath)重新实例化模型
- 使用to_json()函数保存模型的结构为json文件,不包含其权重或配置信息。
- 使用to_yaml()函数保存模型的结构为yaml文件,不包含其权重或配置信息。
- 使用model_from_json()函数从json文件中载入模型
- 使用model_from_yaml()函数从yaml文件中载入模型
- 使用save_weights()函数保存模型权重到HDF5文件
- 使用load_weights()函数从HDF5文件中加载模型权重
简单案例说明
Sequential模型
# For a single-input model with 2 classes (binary classification):
model = Sequential()
model.add(Dense(32, activation='relu', input_dim=100))
model.add(Dense(1, activation='sigmoid'))
model.compile(optimizer='rmsprop',
loss='binary_crossentropy',
metrics=['accuracy'])
# Generate dummy data
import numpy as np
data = np.random.random((1000, 100))
labels = np.random.randint(2, size=(1000, 1))
# Train the model, iterating on the data in batches of 32 samples
model.fit(data, labels, epochs=10, batch_size=32)
上例是一个简单的二分类模型,构建的是一个Sequential序贯模型:
首先使用add方法添加了一个全连接层,其输入参数的维度是(,100),输出的维度是(,32),激活函数为relu,
然后又添加了一个全连接层,其输入维度可由model自动确定,即上一个层的输出维度(,32),输出维度为(,1)
随后compile方法将模型编译,采用的优化目标函数为RMSprop、损失函数为binary_crossentropy,评估指标是准确率accuracy
然后生成了一些训练数据,data和对应的labels,然后调用模型的fit方法即可完成训练。
Model模型
# Shared Input Layer
from keras.utils import plot_model
from keras.models import Model
from keras.layers import Input
from keras.layers import Dense
from keras.layers import Flatten
from keras.layers.convolutional import Conv2D
from keras.layers.pooling import MaxPooling2D
from keras.layers.merge import concatenate
# input layer
visible = Input(shape=(64,64,1))
# first feature extractor
conv1 = Conv2D(32, kernel_size=4, activation='relu')(visible)
pool1 = MaxPooling2D(pool_size=(2, 2))(conv1)
flat1 = Flatten()(pool1)
# second feature extractor
conv2 = Conv2D(16, kernel_size=8, activation='relu')(visible)
pool2 = MaxPooling2D(pool_size=(2, 2))(conv2)
flat2 = Flatten()(pool2)
# merge feature extractors
merge = concatenate([flat1, flat2])
# interpretation layer
hidden1 = Dense(10, activation='relu')(merge)
# prediction output
output = Dense(1, activation='sigmoid')(hidden1)
model = Model(inputs=visible, outputs=output)
该神经网络的模型如下图:
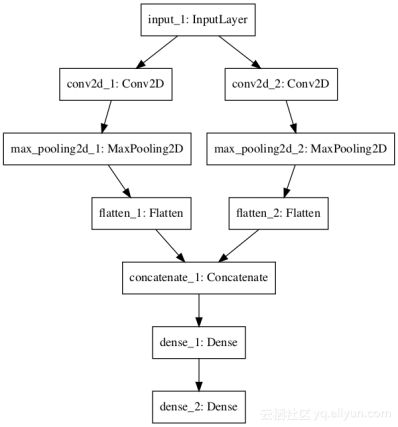
这里使用了Model函数式模型构建的神经网络模型,输入的维度为64641有两个CNN特征提取子模型共享该输入,第一个内核大小为4,第二个内核大小为8,在分别卷积池化后,特征会被平坦化为向量并连接成一个长向量,并连接到完全连接的层,最终使用sigmoid激活函数完成分类问题。
调用GPU的方式
如果采用TensorFlow作为后端,当机器上有可用的GPU时,代码会自动调用GPU进行并行计算。如果采用Theano作为后端,可通过使用Theano标记、设置.theano文件、代码开头手动设置等三种方式来指定。
和其他框架对比
易用性和灵活性:对比TensorFlow、Pytorch等其他深度学习框架而言,Keras的抽象层次更高,将常用的深度学习层和运算封装进干净、乐高大小的构造块,使用者不用考虑深度学习的复杂度,而Pytorch和TensorFlow则提供较低级别的实验环境,用户可以自由的编写自定义层、查看数值优化任务,访问使用函数的核心,在开发复杂架构时更加直接,但这是以冗长和重复造轮子为代价的;
流行度和可获取学习资源:Keras可以获得大量的教程和可重用代码,而TensorFlow和PyTorch则有卓越的社区支持和活跃的开发;
Debug和内省:由于Keras封装了大量的计算模块,这使得确定导致问题的代码较为困难,相比而言TensorFlow和PyTorch则更加详细;Keras用户创建的标准网络要比PyTorch用户创建的标准网络出错的几率要小一个数量级,但一旦出错,则损害巨大,且通常很难定位出错的代码行;
导出模型和跨平台可移植性:在模型导出方面,PyTorch将模型保存在Pickles中,Pickles基于Python,且不可移植,而Keras利用JSON和H5的文件格式,十分方便;在模型部署方面,Keras运行在TensorFlow之上,这使得Keras可以基于TensorFlow将其部署到移动平台和网页上;
性能:相对而言,PyTorch和TensorFlow一样快,在循环神经网络方面可能PyTorch更快,而Keras通常速度较慢,但在大多数情况下,高性能框架(PyTorch和TensorFlow)的计算效率优势不敌快速开发环境以及Keras提供的实验易用性。
总结
Keras是一个非常容易上手的深度学习框架,使用起来比较简单,创建神经网络模型就像搭积木一样,可以快速搭建模型和验证想法,同时不用去关心CPU和GPU切换的问题,CNN和RNN及其变体都支持,十分适合新手和需要快速验证更迭模型的人群使用;
同时由于Keras是高层的API,在使用时一般不会直接涉及神经网络与深度学习一些基础性的知识和原理,屏蔽了许多细节,使用起来就像黑盒子,不如TensorFlow等需要自己去设计和配置较低层的东西,从而更加理解和掌握相关原理;
性能方面,Keras非常适合在学术界或研究领域,但可能并不太适用于在性能要求很高、要求实时计算的领域,如移动端或嵌入式设备等。
参考
https://keras-cn.readthedocs.io/en/latest/
https://keras-cn.readthedocs.io/en/latest/for_beginners/FAQ/
https://blog.csdn.net/ice_actor/article/details/78290830
https://www.jiqizhixin.com/articles/keras-or-pytorch