Flink整合Yarn与Kafka
文章目录
- 1.Flink 整合 YARN
- 1.1yarn-session
- 1.2yarn-cluster
- 1.3Flink On YARN故障恢复
- 2.Flink整合Kafka
1.Flink 整合 YARN
Flink支持多种运行模式:本地Local模式,StandAlone模式,YARN模式,Mesos模式,Kubenetes 模式,Cloud 模式。其中本地模式是用来开发和调试的,YARN 模式是很多公司采用的。在一个企业中,为了最大化的利用集群资源,一般都会在一个集群中同时运行多种类型的 Workload。因此 Flink 也支持在 YARN 上面运行。首先,让我们通过下图了解下 YARN 和 Flink 的关系。

在图中可以看出,Flink 与 YARN 的关系与 MapReduce 和 YARN 的关系是一样的。Flink 通过 YARN 的接口实现了自己的 AppMaster。当在 YARN 中部署了 Flink,YARN 就会用自己的 Container 来启动 Flink 的 JobManager(也就是 AppMaster)和 TaskManager。
YARN 客户端需要访问Hadoop配置,从而连接 YARN 资源管理器和 HDFS。可以使用下面的策略来决定 Hadoop 配置:
-
测试 YARN_CONF_DIR, HADOOP_CONF_DIR 或 HADOOP_CONF_PATH 环境变量是否设置 了(按该顺序测试)。如果它们中有一个被设置了,那么它们就会用来读取配置。
-
如果上面的策略失败了(如果正确安装 YARN 的话,这不应该会发生),客户端会使用HADOOP_HOME 环境变量。 如果该变量设置了,客户端会尝试访问$HADOOP_HOME/etc/hadoop
-
当启动一个新的 Flink YARN Client会话,客户端首先会检查所请求的资源(容器和内存) 是否可用。之后,它会上传包含了 Flink 配置和 jar 文件到 HDFS(步骤 1)。
-
客户端的下一步是请求(步骤 2)一个 YARN 容器启动 ApplicationMaster(步骤 3)。 因为客户端将配置和 jar 文件作为容器的资源注册了,所以运行在特定机器上的 YARN 的NodeManager会负责准备容器(例如,下载文件)。一旦这些完成了,ApplicationMaster (AM) 就启动了。
JobManager 和 AM 运行在同一个容器中。一旦它们成功地启动了,AM 知道 JobManager 的 地址(它自己)。它会为 TaskManager 生成一个新的 Flink 配置文件(这样它们才能连上 JobManager)。该文件也同样会上传到 HDFS。另外,AM 容器同时提供了 Flink 的 Web 界面服务。Flink用来提供服务的端口是由用户+应用程序id作为偏移配置的。这使得用户能够并行执行多个Flink YARN会话。
之后,AM 开始为 Flink的TaskManager分配容器,这会从HDFS下载jar文件和修改过的配 置文件。一旦这些步骤完成了,Flink 就安装完成并准备接受任务了
1.1yarn-session
启动参数
-
必选
- -n,–container 分配多少个 yarn 容器 (=taskmanager 的数量)
-
可选
- -D:动态属性
- -d,–detached:以分离模式独立运行
- -jm,–jobManagerMemory:JobManager容器的内存(默认值:MB)
- -nm,–name:在yarn上为一个自定义的应用设置一个名字
- -q,–query:显示 yarn 中可用的资源 (内存, cpu核数)
- -qu,–queue :指定 YARN 队列.
- -s,–slots :每个TaskManager 使用的 slots 数量
- -tm,–taskManagerMemory:每个TaskManager 的内存(默认值:MB)
- -z,–zookeeperNamespace:针对 HA 模式在 zookeeper上创建 NameSpace
yarn-session.sh -n 2 -s 2 -tm 1024 -jm 1024
上面的命令的意思是,同时向 YARN 申请 3 个 Container,其中 2 个 Container 启动 TaskManager(-n 2),每个 TaskManager 拥有两个 Task Slot(-s 2),并且向每个 TaskManager 的 Container 申请 800M 的内存,以及一个 ApplicationMaster(Job Manager)。
| 参数 | 含义 |
|---|---|
| -n 2 | 指定 2 个容器,其实就是启动 2 个 TaskManager |
| -s 2 | 每个 TaskManager 启动 2 个 Slot |
| -jm 1024 | JobManager 内存为 1024MB |
| -tm 1024 | TaskManager 内存为 1024MB |
| -d | 任务后台运行 |
Flink 部署到 YARN Cluster 后,会显示 Job Manager 的连接细节信息。
Flink on YARN 会覆盖下面几个参数,如果不希望改变配置文件中的参数,可以动态的通过-D 选项指定,如 -Dfs.overwrite-files=true -Dtaskmanager.network.numberOfBuffers=16368
jobmanager.rpc.address:因为 JobManager会经常分配到不同的机器上
taskmanager.tmp.dirs:使用 YARN 提供的 tmp 目录
parallelism.default:如果有指定 slot 个数的情况下
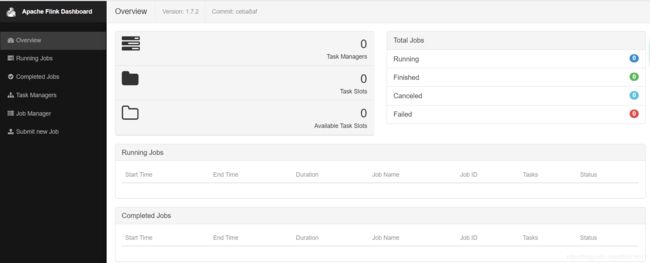
yarn-session.sh会挂起进程,所以可以通过在终端使用ctrl+c或输入stop停止 yarn-session。 如果不希望 Flink YARN client长期运行,Flink 提供了一种 detached YARN session,启动时候加 上参数-d 或–detached 在上面的命令成功后,我们就可以在 YARN Application 页面看到 Flink 的纪录。如下图:

如果在虚拟机中测试,可能会遇到错误。这里需要注意内存的大小,Flink向YARN 会申请多个 Container,但是YARN 的配置可能限制了 Containe 所能申请的内存大小,甚至 YARN本身所管理内存就很小。这样很可能无法正常启动 TaskManager,尤其当指定多个 TaskManager 的时候。因此,在启动 Flink 之后,需要去 Flink 的页面中检查下 Flink 的状态。这里可以从上面的页面中,直接跳转(点击 Tracking UI)。这时候 Flink 的页面如图:
如果由于内存不足导致的错误,可以修改yarn-site.xml中的yarn.nodemanager.vmem-check-enabled参数为false,默认为true
<property>
<name>yarn.nodemanager.vmem-check-enabledname>
<value>falsevalue>
property>
重启集群再尝试即可!!!
在启动了yarn-session的机器上可以看到进程

如下图中yarn-session启动成功后,会出现一个主机和端口后,这个就是JobManager(也是ApplicationMaster)

在yarn-session的机器上或者flink的web管理页面上提交flink任务
flink run $FLINK_HOME/examples/batch/WordCount.jar
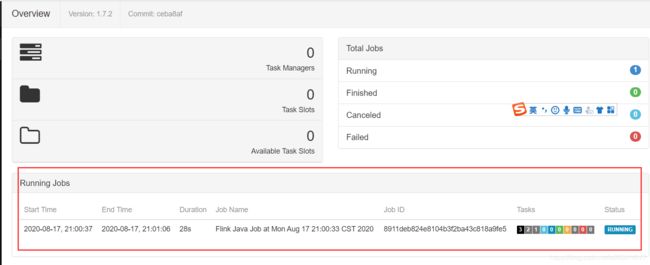
注意:其他节点主机不能提交,如果需要在其他主机节点提交JOB,需要在命令行中用-m参数指定yarn-session启动后,系统自动分配的ApplicationMaster主机和节点和端口

结果

1.2yarn-cluster
flink run -m yarn-cluster -yn 2 -yjm 1024 -ytm 1024 -yqu default $FLINK_HOME/examples/batch/WordCount.jar
-
-m 指定资源调度系统
-
-yn container容器个数
-
-yjm jobmanager 的内存
-
-ytm taskmanager 的内存
-
-yqu YARN 的任务队列
-
-p 指定运行的slot
-
-ys 指定每个节点启动多少个slot
在这个模式下,同样可以使用-m yarn-cluster 提交一个"运行后即焚"的detached yarn(-yd)作业到yarn cluster。

最后的结果
停止任务
yarn application -kill application_1597652530966_0003
1.3Flink On YARN故障恢复
Flink 的 YARN 客户端通过下面的配置参数来控制容器的故障恢复。这些参数可以通过 conf/flink-conf.yaml 或者在启动 yarn session的时候通过-D 参数来指定。
-
yarn.reallocate-failed
这个参数控制了 flink 是否应该重新分配失败的 taskmanager 容器。默认是 true。
-
yarn.maximum-failed-containers applicationMaster
可以接受的容器最大失败次数,达到这个参数,就会认为 yarn session 失败。默认这个次数和初始化请求的 taskmanager 数量相等(-n 参数指定的)。
-
yarn.application-attempts
applicationMaster 重试的次数。如果这个值被设置为 1(默认就是 1),当 application master 失败的时候,yarn session 也会失败。设置一个比较大的值的话,yarn 会尝试重启 applicationMaster。
2.Flink整合Kafka
Flink 提供 Kafka 连接器,用于读取和写入 kafka topics。Flink Kafka 消费者集成了 Flink 的检查点机制来提供Flink处理的exactly-once语义(注意:不是端到端保证)。为实现这一点,Flink 并不依靠 Kafka 的消费者 group offset 跟踪,而是跟踪检查点内部 offset
Flink’s Kafkaconsumer可消费一个或多个 topic。构造方法至少需要(3-4 个参数),直接看代码。
flink-core 默认提供一个最简单的字符序列化/反序列化类(默认:utf-8)参考:org.apache.flink.api.common.serialization.SimpleStringSchema。数据源不是固定数据格式的话,直接使用 SimpleStringSchema即可。否则,可以自己 实现固定数据格式对应的 POJO。 Flinkcheckpoint 开启时,checkpoint以一致的方式将kafka offsets和其他 operations状态一起 保存。Job失败,Flink将存储最近一次的checkpoint,启动之后依据该checkpoint内kafka offsets,开始消费kafka 数据。默认情况下,partitiondiscovery 是关闭的。 开启方法:在 properties config 设置非负值给 discovery 时间间隔(ms)
Flink Kafka Consumer 允许配置offsets 的提交到 kafka或者(zookeeper in 0.8)。这种方式提交的offsets 并不用来保证容错性,仅用来暴露出 consumer 的消费情况。Offsets 提交行为描述:未开启 checkpoint,offsets提交依赖于consumer 的自动提交。开启 checkpoint, offsets提交到checkpoint,setCommitOffsetsOnCheckpoints(boolean)默认是开启的。consumer的自动提交强制关闭。
最合适的做法就是 flinkconsumerkafka 并行度与 kafka partition 数相同,即能保证消费效率, 也不浪费资源。
FlinkIntegrateKafka.scala
package blog.kafka
import java.util.Properties
import org.apache.flink.api.common.serialization.SimpleStringSchema
import org.apache.flink.streaming.api.CheckpointingMode
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer
/**
* @Author Daniel
* @Description Flink整合Kafka
*
**/
object FlinkIntegrateKafka {
def main(args: Array[String]): Unit = {
//构建flink流式入口
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
//非常关键,一定要设置启动检查点!!每隔5s进行启动一个检查点。默认情况下,检查点被禁用,如果不设置,则使用zookeeper来进行存储offset
env.enableCheckpointing(5000)
//开启一次性语义
env.getCheckpointConfig.setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE)
//kafka的配置文件
val properties = new Properties()
//kafka的节点的IP或者hostName,多个使用逗号分隔
properties.setProperty("bootstrap.servers", "hadoop01:9092")
//zookeeper的节点的IP或者hostName,多个使用逗号进行分隔
properties.setProperty("zookeeper.connect", "hadoop01:2181,hadoop02:2181,hadoop03:2181")
//topic flink消费者的group.id
properties.setProperty("group.id", "flink-group-1")
val myConsumer = new FlinkKafkaConsumer[String]("flink", new SimpleStringSchema, properties)
//主要逻辑,这里我直接打印
val keyedStream = env.addSource(myConsumer)
keyedStream.print()
env.execute()
}
}
kafka-topics.sh --create --topic flink --zookeeper hadoop01:2181,hadoop02:2181,hadoop03:2181/kafka --partitions 3 --replication-factor 3
kafka-console-producer.sh --topic flink --broker-list hadoop01:9092,hadoop02:9092,hadoop03:9092
