0x00:IComponent接口
public interface IComponent extends Serializable {
/**
* Declare the output schema for all the streams of this topology.
*
* @param declarer this is used to declare output stream ids, output fields, and whether or not each output stream is a direct stream
*/
void declareOutputFields(OutputFieldsDeclarer declarer);
/**
* Declare configuration specific to this component. Only a subset of the "topology.*" configs can
* be overridden. The component configuration can be further overridden when constructing the
* topology using {@link TopologyBuilder}
*
*/
Map getComponentConfiguration();
}
- 所有的Storm的组件都必须实现这个接口,Storm的组件通过
void declareOutputFields(OutputFieldsDeclarer declarer);方法告诉Storm该组件会发射那些数据流,每个数据流的Tuple中包含那些字段。
0x01:Spout
- ISpout接口
/** * Storm会在同一个线程中执行所有的ack、fail、nextTuple方法,因此实现者无需担心Spout * 的这些方法间的并发问题
,因此实现者应该保证nextTuple方法是非阻塞的,否则会阻塞 * Storm处理ack和fail方法。 * * Storm executes ack, fail, and nextTuple all on the same thread. This means that an implementor * of an ISpout does not need to worry about concurrency issues between those methods. However, it * also means that an implementor must ensure that nextTuple is non-blocking: otherwise * the method could block acks and fails that are pending to be processed. */ public interface ISpout extends Serializable { /** * 所有的Spout组件在初始化的时候调用该方法,和IBolt中的Prepare()类似 * 大部分实例field都应该在这个方法中进行初始化 * 这种设计模式是由Topology的部署方式决定的。当Topology发布时,所有的 * Spout和Bolt组件首先会进行序列化,然后通过网络发送到集群中。如果Spout和Bolt * 在序列化之前(比如构造函数中or直接初始化),实例化了任何无法序列化的实例变量,在进行 * 序列化时就会抛出异常---> * 因此最好在此方法中进行Field的初始化,此方法不会受序列化的限制。 * */ void open(Map conf, TopologyContext context, SpoutOutputCollector collector); /** * 可以在这个方法中做一些清理工作,例如释放数据库连接 * 1、当Topology以集群模式运行时,不保证一定会被调用--》 kill -9 * * Called when an ISpout is going to be shutdown. There is no guarentee that close * will be called, because the supervisor kill -9's worker processes on the cluster. * * The one context where close is guaranteed to be called is a topology is * killed when running Storm in local mode. */ void close(); /** * 当Spout从暂停状态(不发射tuple)中,被激活时,会调用此方法。 * * Called when a spout has been activated out of a deactivated mode. * nextTuple will be called on this spout soon. A spout can become activated * after having been deactivated when the topology is manipulated using the * `storm` client. */ void activate(); /** * 当Spout被暂停的时候,会调用该方法 * * Called when a spout has been deactivated. nextTuple will not be called while * a spout is deactivated. The spout may or may not be reactivated in the future. */ void deactivate(); /** * 该方法会不断的调用,从而不断的向外发射Tuple. * 该方法应该是非阻塞的,如果这个Spout没有Tuple要发射,那么这个方法应该立即返回 * 同时如果没有Tuple要发射,将会Sleep一段时间,防止浪费过多CPU资源 * * When this method is called, Storm is requesting that the Spout emit tuples to the * output collector. This method should be non-blocking, so if the Spout has no tuples * to emit, this method should return. nextTuple, ack, and fail are all called in a tight * loop in a single thread in the spout task. When there are no tuples to emit, it is courteous * to have nextTuple sleep for a short amount of time (like a single millisecond) * so as not to waste too much CPU. */ void nextTuple(); /** * Storm已经确定由该Spout发出的具有msgId标识符的Tuple已经被完全处理,该 * 方法会被调用。。 * 通常情况下,这种方法的实现会将该消息从队列中取出并阻止其重播。 * * Storm has determined that the tuple emitted by this spout with the msgId identifier * has been fully processed. Typically, an implementation of this method will take that * message off the queue and prevent it from being replayed. */ void ack(Object msgId); /** * 该Spout发出的带有msgId标识符的Tuple未能完全处理,此方法将会被调用。。 * 通常,此方法的实现将把该消息放回到队列中,以便稍后重播。 * * The tuple emitted by this spout with the msgId identifier has failed to be * fully processed. Typically, an implementation of this method will put that * message back on the queue to be replayed at a later time. */ void fail(Object msgId); }
0x02:Bolt
- IBolt接口
/**
* An IBolt represents a component that takes tuples as input and produces tuples
* as output. An IBolt can do everything from filtering to joining to functions
* to aggregations. It does not have to process a tuple immediately and may
* hold onto tuples to process later.
*
* A bolt's lifecycle is as follows:
*
* IBolt object created on client machine. The IBolt is serialized into the topology
* (using Java serialization) and submitted to the master machine of the cluster (Nimbus).
* Nimbus then launches workers which deserialize the object, call prepare on it, and then
* start processing tuples.
*
* 如果你想参数化一个IBolt,你应该通过它的构造函数设置参数,并将参数化状态保存
* 为实例变量(然后这些变量将被序列化并发送给在整个群集中执行此螺栓的每个任务)。
* If you want to parameterize an IBolt, you should set the parameters through its
* constructor and save the parameterization state as instance variables (which will
* then get serialized and shipped to every task executing this bolt across the cluster).
*
* When defining bolts in Java, you should use the IRichBolt interface which adds
* necessary methods for using the Java TopologyBuilder API.
*/
public interface IBolt extends Serializable {
void prepare(Map stormConf, TopologyContext context, OutputCollector collector);
/**
* Process a single tuple of input. The Tuple object contains metadata on it
* about which component/stream/task it came from. The values of the Tuple can
* be accessed using Tuple#getValue. The IBolt does not have to process the Tuple
* immediately. It is perfectly fine to hang onto a tuple and process it later
* (for instance, to do an aggregation or join).
*
*
* 应该使用通过prepare方法提供的OutputCollector来发射元组。
* 要求所有输入元组在使用OutputCollector的某个点处成功发出或失败。
* 否则,Storm将无法确定从Spout发射的元组何时完成。
* Tuples should be emitted using the OutputCollector provided through the prepare method.
* It is required that all input tuples are acked or failed at some point using the OutputCollector.
* Otherwise, Storm will be unable to determine when tuples coming off the spouts
* have been completed.
*
* 对于在执行方法结束时确认输入元组成功发射的常见情况,
* 请参阅IBasicBolt,它将其自动化。
* For the common case of acking an input tuple at the end of the execute method,
* see IBasicBolt which automates this.
*
* @param input The input tuple to be processed.
*/
void execute(Tuple input);
void cleanup();
}
0x04: 为Storm设置并发
- ①给Topology增加work:注意
Config conf = new Config();
conf.setNumWorkers(1);
- ②配置Executor和task
- 第一种:该Spout并发为两个Task,每个task指派各自的Executor线程,即会启动三个线程。
builder.setSpout("adx-track-store-spout", kafkaSpout, 3);- 第二种:该Bolt被设置为8个Task,4个Executor,即每个线程执行两个Task(8/4=2)
builder.setBolt("insert-kudu", upsertBolt, 4).setNumTasks(8) .localOrShuffleGrouping("kudu-mapping");
0x05:有保障机制的数据处理
0x05-1: Spout的可靠性:
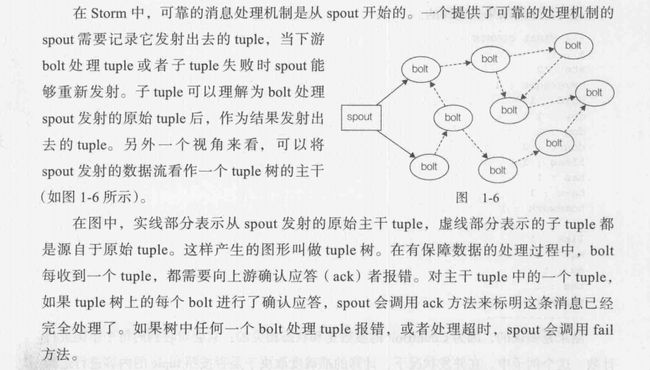
① Storm的ISpout接口定义了三个可靠性相关的API:nextTuple、ack、fail。为了实现可靠的消息处理,首先要给每个发出的Tuple带上唯一的ID,并且将ID作为参数传递给
SpoutOutputCollector的emit()方法
②给tuple指定ID告诉Storm系统,无论执行成功还是失败,Spout都要接受Tuple树上所有节点返回的通知。如果处理成功,Spout的ack()方法将会对编号是ID的消息应答确认,如果执行失败或者超时,会调用fail()方法。
0x05-2: Bolt的可靠性

0x06:Storm调优
- ①
topology.max.spout.pending
/**
*
* Spout task在任意给定的时间可以等待处理的Tuple数量
* 这个配置只作用于单个任务。
*
*
*
* 一个待处理的Tuple是一个已经从Spout发出但尚未被查看或
* 失败的Tuple。注意,这个配置参数对不可靠的Spout没有作用,
* 即不可靠的喷口不会用消息ID标记它们的元组。
*
* The maximum number of tuples that can be pending on a spout task at any given time.
* This config applies to individual tasks, not to spouts or topologies as a whole.
*/
TOPOLOGY_MAX_SPOUT_PENDING="topology.max.spout.pending";