python读写csv的操作汇总
记录我在项目中遇到的,会持续更新,:)
我没有特定用一个库去完成我要读、写、遍历csv的需求,因为常常由于编码的玄学,发现一种方法不适应时于是马上转而用另一种方式,然后就实现了。
显然这样的弊端是我对于编码问题还是一知半解,这里立一个有空要搞清楚编码问题的flag!
下面是应对一些情景时,我的成功的做法。
打开csv来读
1.用csv库
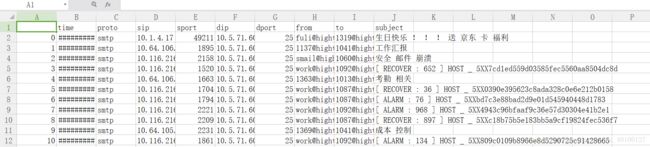
csv如下:
代码如下
csv文档的标题行(首行)需要特殊处理,csv.DictReader可以很好的解决这个问题。DictReader将读取的行转换为python字典对象,而不是列表。标题行的各列名即为字典的键名。
with open("./static/Dataset/" + foldername + "/email.csv", encoding='utf-8', errors='ignore') as csvfile:
fieldnames = ("time", "proto", "sip", "sport", "dip", "dport", "from", "to", "subject")
reader = csv.DictReader(csvfile, fieldnames)
re_email = re.compile('\w+@[hightech.]{9}[com,net,cn]{1,3}')
for row in reader:
if (re_email.match(row["from"])): #遍历每一行时要读某一列的数据用row['列名']的形式2.用pandas库
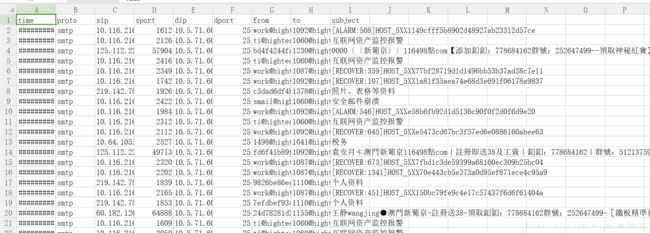
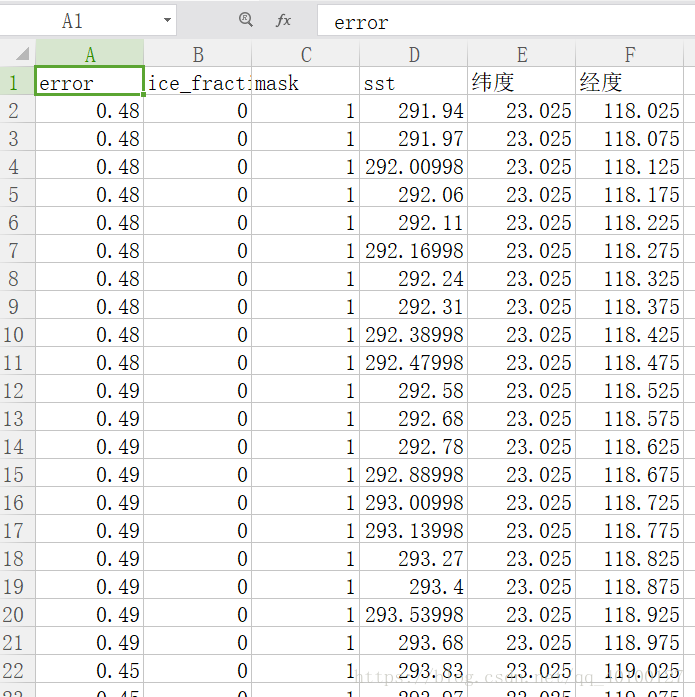
csv如下:
代码如下:
import pandas as pd
df=pd.read_csv(targetfolder+filename+'.csv')
latN=df['纬度'].drop_duplicates().__len__()
lats=list(df['纬度'].drop_duplicates())
lonN=df['经度'].drop_duplicates().__len__()
lons=list(df['经度'].drop_duplicates())2.把数据写入csv(新的csv)
1.用pandas库
代码如下:大意是把要写入csv的数据先装在一个个的list里(前9行代码),然后,用DataFrame格式封装,再用to_csv函数写入。
time_list = []
proto_list = []
sip_list = []
sport_list = []
dip_list = []
dport_list = []
from_list = []
to_list = []
subject_list = []
with open("../static/Dataset/"+foldername+"/email.csv",encoding='gb18030', errors='ignore') as file:
fieldnames = ("time", "proto", "sip", "sport", "dip", "dport", "from", "to", "subject")
reader=csv.DictReader(file,fieldnames)
re_email = re.compile('\w+@[hightech.]{9}[com,net,cn]{1,3}')
for row in reader:
if (re_email.match(row["from"])):
flag = 0
for each in row["to"].split(";"):
if (re_email.match(each) == False):
flag = 1
break
if (flag == 0):
subject_list.append(chinese_text_cut(row["subject"]))
time_list.append(row["time"])
proto_list.append(row["proto"])
sip_list.append(row["sip"])
sport_list.append(row["sport"])
dip_list.append(row["dip"])
dport_list.append(row["dport"])
from_list.append(row["from"])
to_list.append(row["to"])
df2 = pd.DataFrame({
'time': pd.Series(time_list),
'proto': pd.Series(proto_list),
'sip': pd.Series(sip_list),
'sport': pd.Series(sport_list),
'dip': pd.Series(dip_list),
'dport': pd.Series(dport_list),
'from': pd.Series(from_list),
'to': pd.Series(to_list),
'subject': pd.Series(subject_list)
})
df2.to_csv("F:\interactiveVisual\mysite\static\Dataset\\" + foldername + "\email_inner.csv", #新的csv存放的位置
index=True, #新的csv要不要序列号(我选择要)
columns=['time', 'proto', 'sip', 'sport', 'dip', 'dport', 'from', 'to', 'subject'], #设置csv各列的顺序是按照我规定来存
encoding='utf-8')新生成的csv如下: