解惑:Redis的HSCAN命令中COUNT参数的"失效"场景
前提
❝这是一篇Redis命令使用不当的踩坑经历分享
❞
笔者最近在做一个项目时候使用Redis存放客户端展示的订单列表,列表需要进行分页。由于笔者先前对Redis的各种数据类型的使用场景并不是十分熟悉,于是先入为主地看到Hash类型的数据结构,假定:
USER_ID:1
ORDER_ID:ORDER_XX: {"amount": "100","orderId":"ORDER_XX"}
ORDER_ID:ORDER_YY: {"amount": "200","orderId":"ORDER_YY"}
感觉Hash类型完全满足需求实现的场景。然后想当然地考虑使用HSCAN命令进行分页,引发了后面遇到的问题。
SCAN和HSCAN命令
SCAN命令如下:
SCAN cursor [MATCH pattern] [COUNT count] [TYPE type]
// 返回值如下:
// 1. cursor,数值类型,下一轮的起始游标值,0代表遍历结束
// 2. 遍历的结果集合,列表
SCAN命令在Redis2.8.0版本中新增,时间复杂度计算如下:每一轮遍历的时间复杂度为O(1),所有元素遍历完毕直到游标cursor返回0的时间复杂度为O(N),其中N为集合内元素的数量。SCAN是针对整个Database内的所有KEY进行渐进式的遍历,它不会一直阻塞Redis,也就是使用SCAN命令遍历KEY的性能有可能会优于KEY *命令。对于Hash类型有一个衍生的命令HSCAN专门用于遍历Hash类型及其相关属性(Field)的字段:
HSCAN key cursor [MATCH pattern] [COUNT count]
// 返回值如下:
// 1. cursor,数值类型,下一轮的起始游标值,0代表遍历结束
// 2. 遍历的结果集合,是一个映射
笔者当时没有仔细查阅Redis的官方文档,想当然地认为Hash类型的分页简单如下(偏激一点假设每页数据只有1条):
// 第一页
HSCAN USER_ID:1 0 COUNT 1 <= 这里认为返回的游标值为1
// 第二页
HSCAN USER_ID:1 1 COUNT 1 <= 这里认为返回的游标值为0,结束迭代
实际上,执行的结果如下:
HSCAN USER_ID:1 0 COUNT 1
// 结果
0
ORDER_ID:ORDER_XX
{"amount": "100","orderId":"ORDER_XX"}
ORDER_ID:ORDER_YY
{"amount": "200","orderId":"ORDER_YY"}
也就是在第一轮遍历的时候,KEY对应的所有Field-Value已经全量返回。笔者尝试增加哈希集合KEY = USER_ID:1里面的元素,但是数据量相对较大的时候,依然没有达到预期的分页效果;另一个方面,尝试修改命令中的COUNT值,发现无论如何修改COUNT值都不会对遍历的结果产生任何影响(也就是还是在第一轮迭代返回全部结果)。百思不得其解的情况下,只能仔细翻阅官方文档寻找解决方案。在SCAN命令的COUNT属性描述中找到了原因:
 r-h-p-1
r-h-p-1
简单翻译理解一下:
SCAN命令以及其衍生命令并不保证每一轮迭代返回的元素数量,但是可以使用COUNT属性凭经验调整SCAN命令的行为。COUNT指定每次调用应该完成遍历的元素的数量,以便于遍历集合,「本质只是一个提示值」(just a hint,hint意思为暗示)。
COUNT默认值为10。当遍历的目标
Set、Hash、Sorted Set或者Key空间足够大可以使用一个哈希表表示并且不使用MATCH属性的前提下,Redis服务端会返回COUNT或者比COUNT大的遍历元素结果集合。当遍历只包含
Integer值的Set集合(也称为intsets),或者ziplists类型编码的Hash或者Sorted Set集合(说明这些集合里面的元素占用的空间足够小),那么SCAN命令会返回集合中的所有元素,直接忽略COUNT属性。
注意第3点,这个就是在Hash集合中使用HSCAN命令COUNT属性失效的根本原因。Redis配置中有两个和Hash类型ziplist编码的相关配置值:
hash-max-ziplist-entries 512
hash-max-ziplist-value 64
在如下两个条件之一满足的时候,Hash集合的编码会由ziplist会转成dict(字典类型编码是哈希表,即hashtable):
当
Hash集合中的数据项(即Field-Value对)的「数目超过512」的时候。当
Hash集合中插入的任意一个Field-Value对中的「Value长度超过64」的时候。
当Hash集合的编码会由ziplist会转成dict,Redis为Hash类型的内存空间占用优化相当于失败了,降级为相对消耗更多内存的字典类型编码,这个时候,HSCAN命令COUNT属性才会起效。
案例验证
❝查询Redis中Key的编码类型的命令为:object encoding $KEY
❞
简单验证一下上一节得出的结论,写入一个测试数据如下:
// 70个X
HSET USER_ID:2 ORDER_ID:ORDER_XXX XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX
// 70个Y
HSET USER_ID:2 ORDER_ID:ORDER_YYY YYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYY
接着开始测试一下HSCAN命令:
// 查看编码
object encoding USER_ID:2
// 编码结果
hashtable
// 第一轮迭代
HSCAN USER_ID:2 0 COUNT 1
// 第一轮迭代返回结果
2
ORDER_ID:ORDER_YYY
YYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYY
// 第二轮迭代
HSCAN USER_ID:2 2 COUNT 1
0
ORDER_ID:ORDER_XXX
XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX
测试案例中故意让两个值的长度为70,大于64,也就是让Hash集合转变为dict(hashtable)类型,使得COUNT属性生效。但是,这种做法是放弃了Redis为Hash集合的内存优化。此前验证的是hash-max-ziplist-value配置项的临界值,还可以编写一个例子验证hash-max-ziplist-entries的临界值:
// 下面的代码需要确保本地安装了Redis,并且引入Redis的客户端依赖:io.lettuce:lettuce-core:5.3.3.RELEASE
public class HashScanCountSample {
static String KEY = "HS";
static int THRESHOLD = 513;
static int COUNT = 5;
public static void main(String[] args) throws Exception {
ScanArgs scanArgs = new ScanArgs().limit(COUNT);
RedisURI redisUri = RedisURI.create("127.0.0.1", 6379);
RedisClient redisClient = RedisClient.create(redisUri);
RedisCommands commands = redisClient.connect().sync();
commands.del(KEY);
int total = 10;
for (int i = 1; i <= total; i++) {
String fv = String.valueOf(i);
commands.hset(KEY, fv, fv);
}
ScanCursor scanCursor = ScanCursor.INITIAL;
int idx = 1;
processScan(total, scanArgs, commands, scanCursor, idx);
for (int i = 11; i <= THRESHOLD; i++) {
String fv = String.valueOf(i);
commands.hset(KEY, fv, fv);
}
scanCursor = ScanCursor.INITIAL;
total = THRESHOLD;
idx = 1;
processScan(total, scanArgs, commands, scanCursor, idx);
}
private static void processScan(int total, ScanArgs scanArgs, RedisCommands commands, ScanCursor scanCursor, int idx) {
System.out.println(String.format("%d个F-V的HS的编码:%s", total, commands.objectEncoding(KEY)));
System.out.println(String.format("%d个F-V的HS进行HSCAN...", total));
MapScanCursor result;
while (!(result = commands.hscan(KEY, scanCursor, scanArgs)).isFinished()) {
System.out.println(String.format("%d个F-V的HS进行HSCAN第%d次遍历,size=%d", total, idx, result.getMap().size()));
scanCursor = new ScanCursor(result.getCursor(), result.isFinished());
idx++;
}
System.out.println(String.format("%d个F-V的HS进行HSCAN第%d次遍历,size=%d", total, idx, result.getMap().size()));
}
}
// 某次输出结果
10个F-V的HS的编码:ziplist
10个F-V的HS进行HSCAN...
10个F-V的HS进行HSCAN第1次遍历,size=10
......
513个F-V的HS的编码:hashtable
513个F-V的HS进行HSCAN...
513个F-V的HS进行HSCAN第1次遍历,size=5
......
513个F-V的HS进行HSCAN第92次遍历,size=6
513个F-V的HS进行HSCAN第93次遍历,size=6
513个F-V的HS进行HSCAN第94次遍历,size=5
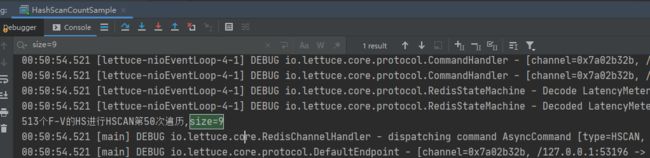
这里看到,最终遍历513个F-V的Hash类型的KEY,最多每次能遍历出9个F-V对,这里只是其中一次的测试数据,也就是说COUNT值即使固定为一个常量,但是遍历出来的数据集合中的元素数量不一定为COUNT,但是大多数情况下为COUNT。
❝不过可以推断出一点,如果Hash中的F-V对的数量小于512,并且所有的V的长度都比较短,HSCAN命令会一次遍历出该KEY的所有的F-V对
❞
显然,HSCAN命令天然不是为了做数据分页而设计的,而是为了渐进式的迭代(也就是如果需要迭代的集合很大,也不会一直阻塞Redis服务)。所以笔者最后放弃了使用HSCAN命令,寻找更适合做数据分页查询的其他Redis命令。
小结
通过这简单的踩坑案例,笔者得到一些经验:
切忌先入为主,使用中间件的时候要结合实际的场景。
使用工具的之前要仔细阅读工具的使用手册。
要通过一些案例验证自己的猜想或者推导的结果。
HSCAN命令中的COUNT属性的功能和Redis服务的配置项hash-max-ziplist-value、hash-max-ziplist-entries以及KEY的编码类型息息相关。Redis提供的API十分丰富,这些API的版本兼容性做得十分优秀,后面应该还会遇到更多的踩坑经验。
(本文完 r-a-2020812 c-2-d 封面来源于动漫《青春之旅》)