Faster R-CNN
原论文中Faster-RCNN的结构:

根据上图来看,Faster-RCNN主要分为四部分,分别是:
- Conv layers。Faster-RCNN首先使用卷积层提取特征获得特征图(feature maps),这些特征图(feature maps)会被共享用于后续区域建议网络(RPN)层和全连接(FC)层。
- RPN。RPN网络用于生成区域建议(region proposals)。该层通过softmax判断锚点(anchors)属于前景(foreground)或者背景(background),再利用边界框回归(bounding box regression)修正锚点(anchors)获得精确的区域建议(region proposals)。
- Roi Pooling。该层收集输入的特征图(feature maps)和区域建议(region proposals),综合这些信息后提取区域建议的特征图(region proposal feature maps),送入后续全连接层判定目标类别。
- Classification。利用区域建议的特征图(region proposal feature maps)计算区域建议(region proposals)的类别,同时再次利用边界框回归(bounding box regression)获得检测框最终的精确位置。
下图展示了Faster-RCNN的网络结构
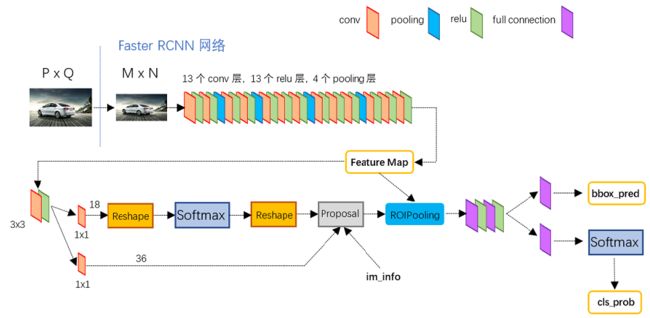
上述步骤简述如下:
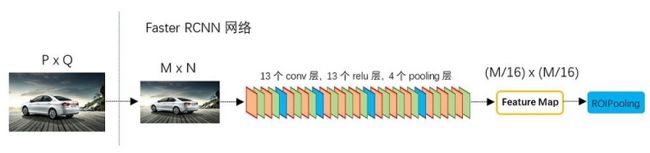
【0】 预处理:该网络对于一副大小(PxQ)的图像,首先缩放至固定大小(MxN),然后将(MxN)的图像送入网络;
【1】 Conv layers:卷积层中包含了13个conv层+13个relu层+4个pooling层;
【2】 RPN:首先将特征图(feature maps)经过3x3卷积,再分别生成foreground anchors与边界框回归(bounding box regression)偏移量,然后计算出区域建议(region proposal);
【3】 Roi Pooling:Roi Pooling层则结合区域建议(region proposal)从特征图(feature maps)中提取区域建议的特征图(region proposal feature maps;
【4】Classification:将区域建议的特征图(region proposal feature maps)送入全连接和softmax网络做分类(classification),即识别区域建议(region proposal)的类别。
1. 卷积部分(Conv layers)
在卷积部分(Conv layers),卷积(conv)层kernel_size=3,pad=1,经过该层之后图像大小不变,池化(pooling)层kernel_size=2,stride=2,(MxN)的图像经过该层之后大小变为(M/2 x N/2),所以一个(MxN)的图像经过卷积部分(Conv layers)之后大小变为(M/16 x N/16)。
2. 区域建议网络(RPN)
区域建议网络(RPN)网络结构如下:
 区域建议网络(RPN)实际分为2条线:
区域建议网络(RPN)实际分为2条线:
上面一条通过softmax分类锚点(anchors)获得前景(foreground)和背景(background)(检测目标是前景(foreground))。
下面一条用于计算对于锚点(anchors)的边界框回归(bounding box regression)偏移量,以获得精确的区域建议(region proposal)。
而最后的建议(Proposal)层则负责综合前景锚点(foreground anchors)和边界框回归(bounding box regression)偏移量获取区域建议(region proposal),同时剔除太小和超出边界的区域建议(region proposal)。其实整个网络到了建议(Proposal)层这里,就完成了相当于目标定位的功能。
锚点(Anchors)
锚点(anchor)的机制是:以滑动窗的中心为采样点,采用不同的尺寸(scale)和比例(ratio),生成不同大小共 k 个锚点(anchor)窗口。对于一个W*H大小的特征图(feature map)来说,生成的锚点(anchor)总数为W*H*k。例如尺寸(scale)为(128,256,512),比例(ratio)为(1:2,1:1,2:1)时,则生成 9 种锚点(anchor)。
目标识别任务应具有平移不变性和尺度不变性,传统的做法是采用图像金字塔(image pyramid)或滤波器金字塔(filter pyramid),锚点(anchor)的机制满足这样的要求,且相比较两种做法更加的经济且有效。
一个滑动窗的中心生成一组锚点(anchors),一共9个,如下:

只要生成一组锚点(anchors)做为基准,然后用这组锚点(anchors)在滑动窗上遍历就可以生成所有的锚点(anchors)了。如果滑动窗共有 x x x个点,那么遍历之后就可以生成9 x x x个锚点(anchors)。
过程图例如下,帮助理解:
下面以一段简单的代码来演示如何生成一个用作基准的锚点(anchors)。
# 先定义比例(ratio)和尺度(scale)
import numpy as np
base_size = 128 # 基础尺寸
ratios = [0.5, 1, 2] # 三种比例(1:2,1:1,2:1)
scales = [1, 2, 4] # 三种尺度(128,256,512)
# 扩展维度
ratios = np.expand_dims(ratios, axis=1) # (M, 1)
>>> [[0.5]
> [1. ]
> [2. ]]
scales = np.expand_dims(scales, axis=0) # (1, N)
>>> [[1 2 4]]
# 根据已有长宽比、缩放因子矩阵,得到两两结合的基于base_size的anchors长、宽
h = np.sqrt(ratios) * scales * base_size
>>> [[ 90.50966799 181.01933598 362.03867197]
> [128. 256. 512. ]
> [181.01933598 362.03867197 724.07734394]]
w = 1.0 / np.sqrt(ratios) * scales * base_size
>>> [[181.01933598 362.03867197 724.07734394]
> [128. 256. 512. ]
> [ 90.50966799 181.01933598 362.03867197]]
h = np.reshape(h, (-1, 1))
w = np.reshape(w, (-1, 1))
base_anchors = np.hstack([-0.5*h, -0.5*w, 0.5*h, 0.5*w])
>>> [[ -45.254834 -90.50966799 45.254834 90.50966799]
> [ -90.50966799 -181.01933598 90.50966799 181.01933598]
> [-181.01933598 -362.03867197 181.01933598 362.03867197]
> [ -64. -64. 64. 64. ]
> [-128. -128. 128. 128. ]
> [-256. -256. 256. 256. ]
> [ -90.50966799 -45.254834 90.50966799 45.254834 ]
> [-181.01933598 -90.50966799 181.01933598 90.50966799]
> [-362.03867197 -181.01933598 362.03867197 181.01933598]]
最终得到如上所述的9个锚点(anchors)(每行的4个值[x1,y1,x2,y2]分别代表矩形左上角和右下角的坐标),由上述过程得到的9个anchors是以(0, 0)为中心的,如下:

以该锚点在滑动窗口上遍历,就能得到所有的锚点,下面使用numpy来完成:
# 首先定义几个参数
stride = 1 # 遍历时的步长,因为要遍历所有的点,所以stride = 1
feature_map_shape = (10, 20) # 特征图(feature map)的维度,假设是(10x20)=200
# 找到所有中心点
H, W = feature_map_shape
center_x = (np.arange(W) + 0.5) * stride
>>> [ 0.5 1.5 2.5 3.5 4.5 5.5 6.5 7.5 8.5 9.5 10.5 11.5 12.5 13.5 14.5 15.5 16.5 17.5 18.5 19.5]
center_y = (np.arange(H) + 0.5) * stride
>>> [0.5 1.5 2.5 3.5 4.5 5.5 6.5 7.5 8.5 9.5]
# 构建中心点网络
center_x, center_y = np.meshgrid(center_x, center_y)
# 维度转换成(1, N)
center_x = np.reshape(center_x, [-1])
>>> [ 0.5 1.5 2.5 3.5 4.5 5.5 ... 17.5 18.5 19.5]
center_y = np.reshape(center_y, [-1])
>>> [ 0.5 0.5 0.5 0.5 0.5 0.5 ... 9.5 9.5 9.5]
# 扩展维度
shifts = np.expand_dims(np.stack([center_y, center_x, center_y, center_x], axis=1), axis=1)
>>> [[[ 0.5 0.5 0.5 0.5]]
> [[ 0.5 1.5 0.5 1.5]]
> ...
> [[ 9.5 18.5 9.5 18.5]]
> [[ 9.5 19.5 9.5 19.5]]]
base_anchors = np.expand_dims(base_anchors), axis=0)
>>> [[[ -45.254834 -90.50966799 45.254834 90.50966799]
> [ -90.50966799 -181.01933598 90.50966799 181.01933598]
> [-181.01933598 -362.03867197 181.01933598 362.03867197]
> [ -64. -64. 64. 64. ]
> [-128. -128. 128. 128. ]
> [-256. -256. 256. 256. ]
> [ -90.50966799 -45.254834 90.50966799 45.254834 ]
> [-181.01933598 -90.50966799 181.01933598 90.50966799]
> [-362.03867197 -181.01933598 362.03867197 181.01933598]]]
# 合并
all_anchors = base_anchors + shifts
>>> [[[ -44.754834 -90.00966799 45.754834 91.00966799]
> [ -90.00966799 -180.51933598 91.00966799 181.51933598]
> ...
> [-180.51933598 -90.00966799 181.51933598 91.00966799]
> [-361.53867197 -180.51933598 362.53867197 181.51933598]]
> ...
> [[ -35.754834 -71.00966799 54.754834 110.00966799]
> [ -81.00966799 -161.51933598 100.00966799 200.51933598]
> ...
> [-171.51933598 -71.00966799 190.51933598 110.00966799]
> [-352.53867197 -161.51933598 371.53867197 200.51933598]]]
anchors = np.reshape(all_anchors, [-1, 4])
>>> [[ -44.754834 -90.00966799 45.754834 91.00966799]
> [ -90.00966799 -180.51933598 91.00966799 181.51933598]
> ...
> [-171.51933598 -71.00966799 190.51933598 110.00966799]
> [-352.53867197 -161.51933598 371.53867197 200.51933598]]
特征图(feature map)共有200个点,这里最终得到的锚点(anchors)维度为(200x9, 4)=(1800, 4),也就是说一共1800个锚点(anchors)。这些锚点(anchors)会被当作初始的检测框。这样做获得检测框很不准确,后面还有2次边界框回归(bounding box regression)可以修正检测框位置。
目标锚点(anchor)
锚点个数太多了,先筛选一遍再拿过来用。对筛选后的锚点(anchor)分配标签(label),前景/背景,以便训练区域建议网络(RPN),筛选和分配标签的做法如下:
- 对于每个正确标注(Ground Truth),找到与他IOU最大的锚点(anchor)然后设为正样本
- 对于每个锚点(anchor)只要它与任意一个正确标注(Ground Truth)的IOU大于0.7即设为正样本
- 对于每个锚点(anchor),它与任意一个正确标注(Ground Truth)的IOU都小于0.3即设为负样本
- 不是正也不是负的锚点(anchor)被忽略。
这就得到了一批带有标签的锚点(anchor)。
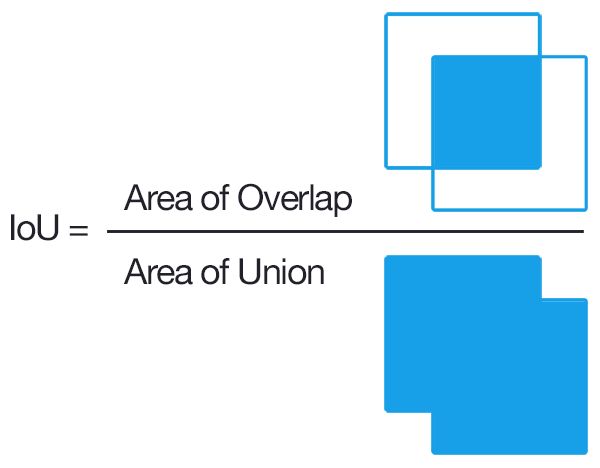
为什么用IOU(Intersection over Union)?
IOU(Intersection over Union),即交集并集比。是指两个区域的交集和并集的比值,图示如下:
如果您了解过任何以前的机器学习方法,特别是分类,您可能会习惯于预测类标签,其中您的模型输出一个正确或不正确的标签。
这种方法对二分类显得直截了当,然而对于物体检测而言,就变得困难得多了。我们预测的边界框的(x,y)坐标与标注边界框的(x,y)坐标完全匹配的可能性极小。由于我们模型的参数变化(图像金字塔比例,滑动窗口大小,特征提取方法等),预测框与真实边界框完全匹配是不现实的。因此,我们需要定义一个评估指标,对预测的边界框与真实边界框严重重叠的情况进行奖励:
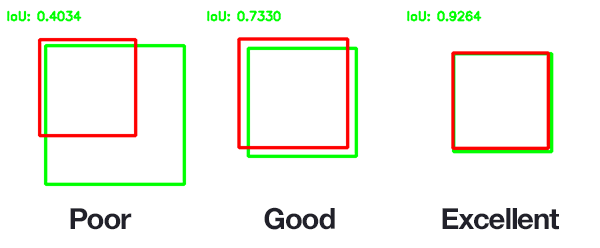
在上图中,我列举了关于IOU得分的例子。正如所看到的,与真实边界框重叠的预测边界框比重叠较少的边界框具有更高的分数。这使得IOU成为评估自定义对象检测器的极佳指标。我们并不关心(x,y)坐标的精确匹配,但我们确实希望确保我们预测的边界框尽可能匹配 - IOU能够考虑到这一点。
下面用一段简单的代码来计算边界框boxes_a和边界框boxes_b的IOU:
import numpy as np
# boxes样例
boxes_a = np.array([[78,22,253,304],[269,19,360,296]])
boxes_b = np.array([[50,30,200,280],[280,10,370,320]])
# 扩维
boxes_a = np.expand_dims(boxes_a, axis=1)
>>> [[[ 78 22 253 304]]
>
> [[269 19 360 296]]]
boxes_b = np.expand_dims(boxes_b, axis=0)
>>> [[[ 50 30 200 280]
> [280 10 370 320]]]
# 两两计算overlap的长与宽,若不相交(负值)则取0
overlap_h = np.maximum(0.0, np.minimum(boxes_a[...,2],boxes_b[...,2])-np.maximum(boxes_a[...,0],boxes_b[...,0]))
>>> [[122. 0.]
> [ 0. 80.]]
overlap_w = np.maximum(0.0, np.minimum(boxes_a[...,3],boxes_b[...,3])-np.maximum(boxes_a[...,1],boxes_b[...,1]))
>>> [[250. 282.]
> [250. 277.]]
# 计算交集
overlap = overlap_h * overlap_w
>>> [[30500. 0.]
> [ 0. 22160.]]
# 计算并集
union = (boxes_a[...,2]-boxes_a[...,0]) * (boxes_a[...,3]-boxes_a[...,1]) + (boxes_b[...,2]-boxes_b[...,0]) * (boxes_b[...,3]-boxes_b[...,1]) - overlap
>>> [[56350. 77250.]
> [62707. 30947.]]
# 求交并比
iou = overlap / union
>>> [[0.54125998 0. ]
> [0. 0.71606295]]
1x1的卷积有什么用?
对于多通道图像+多卷积核做卷积,计算方式如下:
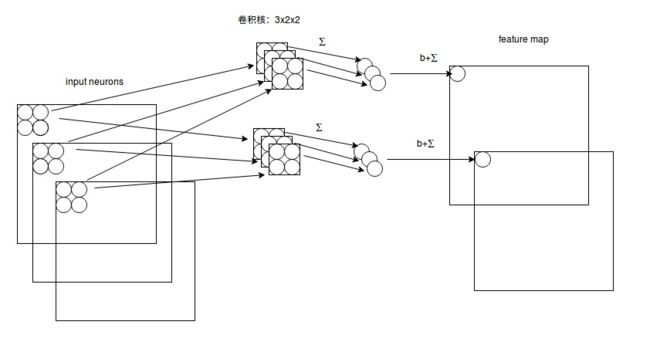
如上图,输入有3个通道,同时有2个卷积核。对于每个卷积核,先在输入3个通道分别作卷积,再将3个通道结果加起来得到卷积输出。所以对于某个卷积层,无论输入图像有多少个通道,输出图像通道数总是等于卷积核数量!如果将它看作跨通道的采样操作,它还能帮我们在同一位置对不同通道之间进行特征的融合。
也就是说,1x1的卷积核主要有两个作用
- 可以进行降维或者升维,这是通过控制卷积核(通道)数量实现的,这个可以减少模型参数,也可以对不同特征进行尺寸的归一化;
- 可以用于不同通道上特征的融合。
softmax判定前景(foreground)与背景(background)
一个MxN大小的矩阵送入Faster RCNN网络后,到RPN网络变为(M/16)x(N/16),不妨设W=M/16,H=N/16。在进入reshape与softmax之前,先做了1x1卷积,如图

可以看到其输出的维度是18,也就是经过该卷积的输出图像为WxHx18大小。这也就刚好对应了特征图(feature maps)每一个点都有9个锚点(anchors),同时每个锚点(anchors)又有可能是前景(foreground)或背景(background),所有这些信息都保存在WxHx(9x2)大小的矩阵中。
为何这样做?后面接softmax分类获得前景锚点(foreground anchors),也就相当于初步提取了检测目标候选区域框(box)。
另外,softmax层前后的reshape层仅仅是为了方便计算。
综上所述,RPN网络中利用锚点(anchors)和softmax初步提取出前景锚点(foreground anchors)作为候选区域。
边界框回归(bounding box regression)
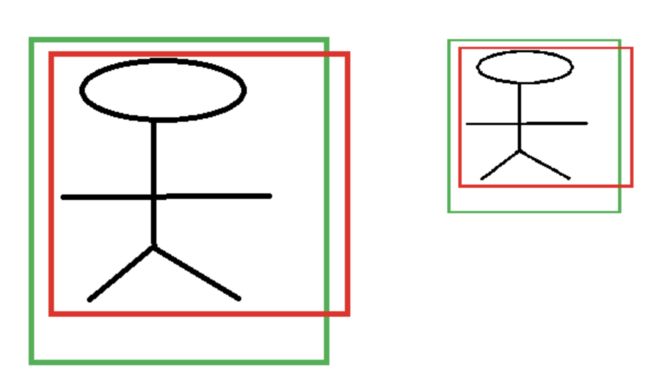
如图所示,绿色框为飞机的正确标注(Ground Truth),红色为提取的前景锚点(foreground anchors),那么即便红色的框被分类器识别为飞机,但是由于红色的框定位不准,这张图相当于没有正确的检测出飞机。所以我们希望采用一种方法对红色的框进行微调,使得前景锚点(foreground anchors)和正确标注(Ground Truth)更加接近。
对于窗口一般使用四维向量 ( x , y , w , h ) (x,y,w,h) (x,y,w,h) 来表示, 分别表示窗口的中心点坐标和宽高。 对于下图, 红色的框 P 代表原始的区域建议(Proposal), 绿色的框 G 代表目标的正确标注(Ground Truth), 我们的目标是寻找一种关系使得输入原始的窗口 P P P 经过映射得到一个跟真实窗口 G G G 更接近的回归窗口 G ^ Ĝ G^。

边框回归的目的即是:给定 ( P x , P y , P w , P h ) (P_x,P_y,P_w,P_h) (Px,Py,Pw,Ph)寻找一种映射 f f f, 使得
f ( P x , P y , P w , P h ) = ( G ^ x , G ^ y , G ^ w , G ^ h ) f\left(P_{x}, P_{y}, P_{w}, P_{h}\right)=\left(\hat{G}_{x}, \hat{G}_{y}, \hat{G}_{w}, \hat{G}_{h}\right) f(Px,Py,Pw,Ph)=(G^x,G^y,G^w,G^h)并且 ( G ^ x , G ^ y , G ^ w , G ^ h ) ≈ ( G x , G y , G w , G h ) \left(\hat{G}_{x}, \hat{G}_{y}, \hat{G}_{w}, \hat{G}_{h}\right) \approx\left(G_{x}, G_{y}, G_{w}, G_{h}\right) (G^x,G^y,G^w,G^h)≈(Gx,Gy,Gw,Gh)
那么经过何种变换才能从图中的窗口 P 变为窗口Ĝ 呢? 比较简单的思路就是: 平移+尺度放缩
-
先做平移: G ^ x = P w d x ( P ) + P x \hat{G}_{x}=P_{w} d_{x}(P)+P_{x} G^x=Pwdx(P)+Px G ^ y = P h d y ( P ) + P y \hat{G}_{y}=P_{h} d_{y}(P)+P_{y} G^y=Phdy(P)+Py
-
然后再做尺度缩放: G ^ w = P w exp ( d w ( P ) ) G ^ h = P h exp ( d h ( P ) ) \begin{aligned} \hat{G}_{w} &=P_{w} \exp \left(d_{w}(P)\right) \\ \hat{G}_{h} &=P_{h} \exp \left(d_{h}(P)\right)\end{aligned} G^wG^h=Pwexp(dw(P))=Phexp(dh(P))
观察上面四个公式我们发现, 边框回归学习就是 d x ( P ) d_x(P) dx(P), d y ( P ) d_y(P) dy(P), d w ( P ) d_w(P) dw(P), d h ( P ) d_h(P) dh(P)这四个变换。当输入的锚点(anchor)与正确标注(Ground Truth)相差较小时,可以认为这种变换是一种线性变换, 那么就可以用线性回归来建模对窗口进行微调。
对应于Faster RCNN原文,平移量 ( t x , t y ) (t_x, t_y) (tx,ty)与尺度因子 ( t w , t h ) (t_w, t_h) (tw,th)如下: t x = ( x − x a ) / w a , t y = ( y − y a ) / h a t w = log ( w / w a ) , t h = log ( h / h a ) \begin{aligned} t_{\mathrm{x}} &=\left(x-x_{\mathrm{a}}\right) / w_{\mathrm{a}}, \quad t_{\mathrm{y}}=\left(y-y_{\mathrm{a}}\right) / h_{\mathrm{a}} \\ t_{\mathrm{w}} &=\log \left(w / w_{\mathrm{a}}\right), \quad t_{\mathrm{h}}=\log \left(h / h_{\mathrm{a}}\right) \end{aligned} txtw=(x−xa)/wa,ty=(y−ya)/ha=log(w/wa),th=log(h/ha)接下来的问题就是如何通过线性回归获得 d x ( P ) d_x(P) dx(P), d y ( P ) d_y(P) dy(P), d w ( P ) d_w(P) dw(P), d h ( P ) d_h(P) dh(P)了。线性回归就是给定输入的特征向量 X X X, 学习一组参数 W W W, 使得经过线性回归后的值跟正确标注Y(Ground Truth)非常接近,即 Y ≈ W X Y≈WX Y≈WX 。对于该问题,输入 X X X是一张经过1x1卷积获得的特征图(feature map),定义为 Φ Φ Φ;同时还有训练传入的正确标注(Ground Truth),即 ( t x , t y , t w , t h ) (t_x, t_y, t_w, t_h) (tx,ty,tw,th)。输出是 d x ( P ) , d y ( P ) , d w ( P ) , d h ( P ) dx(P),dy(P),dw(P),dh(P) dx(P),dy(P),dw(P),dh(P)四个变换。那么目标函数可以表示为: d ∗ ( P ) = w ∗ T ⋅ Φ ( P ) d_{*}(P)=w_{*}^{T} \cdot \Phi(\mathrm{P}) d∗(P)=w∗T⋅Φ(P)其中 Φ ( P ) Φ(P) Φ(P)是对应锚点(anchor)的特征图(feature map)组成的特征向量, w w w是需要学习的参数, d ( P ) d(P) d(P)是得到的预测值(*表示 x , y , w , h x,y,w,h x,y,w,h,也就是每一个变换对应一个上述目标函数)。为了让预测值 ( t x , t y , t w , t h ) (t_x, t_y, t_w, t_h) (tx,ty,tw,th)与真实值误差最小,得到损失函数: L o s s = ∑ i N ( t ∗ i − w ^ ∗ T ϕ ( P i ) ) 2 L o s s=\sum_{i}^{N}\left(t_{*}^{i}-\hat{w}_{*}^{T} \phi\left(P^{i}\right)\right)^{2} Loss=i∑N(t∗i−w^∗Tϕ(Pi))2函数优化目标为: W ∗ = argmin w ∗ ^ ∑ i N ( t ∗ i − w ^ ∗ T ϕ ( P i ) ) 2 + λ ∥ w ^ ∗ ∥ 2 W_{*}=\operatorname{argmin}_{\hat{{w}_{*}}} \sum_{i}^{N}\left(t_{*}^{i}-\hat{w}_{*}^{T} \phi\left(P^{i}\right)\right)^{2}+\lambda\left\|\hat{w}_{*}\right\|^{2} W∗=argminw∗^i∑N(t∗i−w^∗Tϕ(Pi))2+λ∥w^∗∥2
为什么宽高尺度会设计这种形式?
x,y 坐标除以宽高
首先CNN具有尺度不变性, 以下图为例:
上图的两个人具有不同的尺度,因为他都是人,我们得到的特征相同。假设我们得到的特征分别为 ϕ 1 , ϕ 2 ϕ_1, ϕ_2 ϕ1,ϕ2,那么一个完好的特征应该满足 ϕ 1 = ϕ 2 ϕ_1=ϕ_2 ϕ1=ϕ2。如果我们直接学习坐标差值,以 x x x坐标为例,假设左边红色和绿色的中心坐标分别为 x 1 , p 1 x_1, p_1 x1,p1,右边为 x 2 , p 2 x_2, p_2 x2,p2,学习到的映射为 f f f, f ( ϕ 1 ) = x 1 − p 1 f(ϕ_1)=x_1−p_1 f(ϕ1)=x1−p1 ,同理 f ( ϕ 2 ) = x 2 − p 2 f(ϕ_2)=x_2−p_2 f(ϕ2)=x2−p2。从上图显而易见, x 1 − p 1 x_1−p_1 x1−p1和 x 2 − p 1 x_2−p_1 x2−p1不相等。所以原公式中写为 t x = ( x − x a ) / w a , t y = ( y − y a ) / h a t_x = (x - x_a) / w_a, t_y = (y - y_a) / h_a tx=(x−xa)/wa,ty=(y−ya)/ha,来消除尺度不同带来的影响。
宽高坐标Log形式
我们想要得到一个放缩的尺度,也就是说这里限制尺度必须大于0。我们学习的 t w , t h t_w, t_h tw,th怎么保证满足大于0呢?直观的想法就是EXP函数,那么反过来推导就是Log函数的来源了。
为什么IOU较大,认为是线性变换?
当输入的建议(Proposal) 与正确标注(Ground Truth) 相差较小时, 可以认为这种变换是一种线性变换, 那么我们就可以用线性回归来建模对窗口进行微调,否则会导致训练的回归模型不工作(当建议(Proposal) 跟正确标注(Ground Truth) 离得较远时,就是复杂的非线性问题了,此时用线性回归建模显然不合理)。解释如下:
Log函数明显不满足线性函数,但是为什么当建议(Proposal) 和正确标注(Ground Truth) 相差较小的时候,就可以认为是一种线性变换呢?这是因为:
lim x = 0 log ( 1 + x ) = x \lim _{x=0} \log (1+x)=x x=0limlog(1+x)=x
t w t_w tw的表达式为
t w = log ( G w / P w ) = log ( G w + P w − P w P w ) = log ( 1 + G w − P w P w ) t_{w}=\log \left(G_{w} / P_{w}\right)=\log \left(\frac{G_{w}+P_{w}-P_{w}}{P_{w}}\right)=\log \left(1+\frac{G_{w}-P_{w}}{P_{w}}\right) tw=log(Gw/Pw)=log(PwGw+Pw−Pw)=log(1+PwGw−Pw)
当且仅当 G w − P w = 0 G_w−P_w=0 Gw−Pw=0的时候,才会是线性函数,也就是建议(Proposal) 跟正确标注(Ground Truth) 必须近似相等,这也就是为什么调整只能是“微”调。
对建议(proposals)进行边界框回归(bbox regression)
在了解边界框回归(bounding box regression)后,再回头来看RPN网络第二条线路,如图

此处经过1x1卷积之后其输出的维度是36,即经过该卷积输出图像为WxHx36,可以将其存储为[1, 4x9, H, W],相当于feature maps每个点都有9个anchors,每个anchors又都有4个用于回归的 [ d x ( P ) , d y ( P ) , d w ( P ) , d h ( P ) ] \left[d_{x}(P), d_{y}(P), d_{w}(P), d_{h}(P)\right] [dx(P),dy(P),dw(P),dh(P)]变换量。
建议层(Proposal Layer)
建议层(Proposal Layer)负责综合所有 [ d x ( P ) , d y ( P ) , d w ( P ) , d h ( P ) ] \left[d_{x}(P), d_{y}(P), d_{w}(P), d_{h}(P)\right] [dx(P),dy(P),dw(P),dh(P)]变换量和前景锚点(foreground anchors),计算出精准的建议(proposal),送入后面的感兴趣区域池化层(RoI Pooling Layer)。
建议层(Proposal Layer)有3个输入:
- 前景/背景锚点( fg/bg anchors)分类器结果rpn_cls_prob_reshape;
- 对应的边界框回归(bbox reg)的 [ d x ( P ) , d y ( P ) , d w ( P ) , d h ( P ) ] \left[d_{x}(P), d_{y}(P), d_{w}(P), d_{h}(P)\right] [dx(P),dy(P),dw(P),dh(P)]变换量rpn_bbox_pred;
- 以及图像变换过程中发生过的变换信息(im_info)。
首先解释图像的变换信息(im_info)。对于一副任意大小PxQ图像,传入Faster R-CNN前首先重塑(reshape)到固定MxN,im_info=[M, N, scale_factor]则保存了此次缩放的所有信息(scale_factor为缩放因子)。然后经过卷积部分(Conv Layers),经过4次池化(pooling)变为WxH=(M/16)x(N/16)的大小,此处的16也会保存在im_info中(feat_stride=16),用于计算锚点(anchor)偏移量,以便于获得锚点(anchor)和原MxN的图像之间的对应关系。
建议层(Proposal Layer)前向传播(forward)按照以下顺序依次处理:
- 再次生成锚点(anchors),利用 [ d x ( P ) , d y ( P ) , d w ( P ) , d h ( P ) ] \left[d_{x}(P), d_{y}(P), d_{w}(P), d_{h}(P)\right] [dx(P),dy(P),dw(P),dh(P)]对所有的锚点(anchors)做边界框回归(bbox regression)(这里的anchors生成和训练时完全一致);
- 按照输入的前景(foreground)的softmax分数(scores)由大到小排序锚点(anchors),提取前若干(例如 6000)个锚点(anchors),即提取修正位置后的前景(foreground anchors)。
- 将锚点(anchors)映射回原图,判断前景锚点(fg anchors)是否超过边界,剔除超出边界的前景锚点(fg anchors);
- 剔除非常小:宽度或高度小于给定阈值(width
- 进行非极大值抑制(nonmaximum suppression,非极大值抑制);
- 再次按照非极大值抑制(NMS)后的前景(foreground)的softmax分数(scores)由大到小排序前景锚点(fg anchors),提取前若干(例如 300)个结果作为建议(proposal)输出。
之后输出proposal=[x1, y1, x2, y2],注意,由于在第三步中将锚点(anchors)映射回原图判断是否超出边界,所以这里输出的proposal是对应MxN输入图像尺度的。
TensorFlow中有NMS的函数non_max_suppression,下面用一段简单的代码来看一下如何使用:
import numpy as np
import tensorflow as tf
# 定义一些参数
max_output_size = 10 # 输出的维度
iou_threshold=0.5 # IOU的阈值
# 模拟一组(这里是四个)边界框(bboxes)和其对应的分数(scores)
bboxes = np.array([[78,22,253,304],[269,19,360,296],[50,30,200,280],[280,10,370,320]])
scores = tf.constant([0.9,0.8,0.7,0.75])
# 转tensor
bboxes = tf.convert_to_tensor(bboxes, dtype=tf.float32)
>>> Tensor("Const_1:0", shape=(4, 4), dtype=float32)
# nms
indices = tf.image.non_max_suppression(bboxes, scores, max_output_size, iou_threshold)
>>> Tensor("non_max_suppression/NonMaxSuppressionV3:0", shape=(?,), dtype=int32)
# tf.image.non_max_suppression()方法返回的是bboxes对应的下标
# 直接用tf.gather()方法得到对应的边界框(bboxes)与得分(scores)
bboxes_out = tf.gather(bboxes, indices)
>>> Tensor("GatherV2:0", shape=(?, 4), dtype=float32)
scores_out = tf.gather(scores, indices)
>>> Tensor("GatherV2_1:0", shape=(?,), dtype=float32)
RPN网络结构就介绍到这里,总结起来就是:
生成锚点(anchors) -> softmax分类器提取前景锚点(fg anchors) -> 对前景(fg anchors)进行边界框回归(bbox reg) -> 建议层(Proposal Layer)生成建议(proposals)
【3】感兴趣区域池化(RoI pooling)
感兴趣区域池化(RoI Pooling)层则负责收集建议(proposal),并计算出建议特征图(proposal feature maps),送入后面的网络中。感兴趣区域池化(Rol pooling)层有2个输入:
- 原始的特征图(feature maps)
- 区域建议网络(RPN)输出的建议框(proposal boxes)(大小各不相同)
为何需要RoI Pooling
先来看一个问题:对于传统的卷积神经网络(CNN)(如AlexNet,VGG等),当网络训练好后输入的图像尺寸必须是固定值,同时网络输出也是固定大小的向量或矩阵。如果输入图像大小不定,这个问题就变得比较麻烦。有2种解决办法:
- 从图像中剪裁(crop)一部分传入网络
- 将图像扭曲(warp)成需要的大小后传入网络

可以看到无论采取那种办法都不好,要么剪裁(crop)后破坏了图像的完整结构,要么扭曲(warp)破坏了图像原始形状信息。回忆区域建议网络(RPN)生成的建议(proposals)的方法:对前景锚点(foreground anchors)进行边界框回归(bound box regression),那么这样获得的建议(proposals)也是大小形状各不相同,即也存在上述问题。所以Faster R-CNN中提出了感兴趣区域池化(RoI Pooling)解决这个问题。
感兴趣区域池化(RoI Pooling)原理
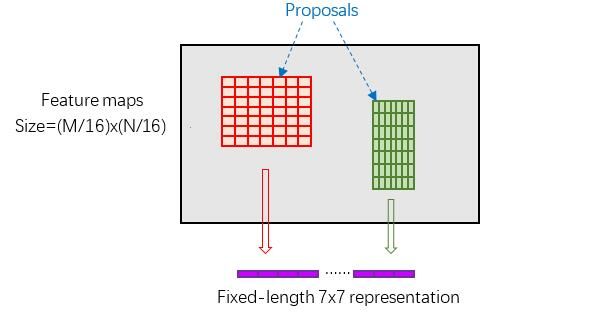
感兴趣区域池化层(RoI Pooling layer)前向传播(forward)过程:在之前有明确提到:proposal=[x1, y1, x2, y2]是对应MxN尺度的,所以首先使用将其映射回MxN大小的特征图(feature maps)尺度;之后将每个建议(proposal)水平和竖直都分为7份,对每一份都进行最大池化(max pooling)处理。这样处理后,即使大小不同的建议(proposal),输出结果都是7x7大小,实现了定长输出(fixed-length output)。
【4】分类(Classification)
分类(Classification)部分利用已经获得的建议(proposal)的特征图(feature maps),通过全连接(full connect)层与softmax计算每个建议(proposal)具体属于哪个类别(如人,车,电视等),输出类别概率向量cls_prob;同时再次利用边界框回归(bounding box regression)获得每个建议(proposal)的位置偏移量(bbox_pred),用于回归更加精确的目标检测框。分类(Classification)部分网络结构如图。

从感兴趣区域池化(RoI Pooling)层获取到7x7=49大小的建议(proposal)特征图(feature maps)后,送入后面网络,可以看到做了如下2件事:
- 通过全连接和softmax对建议(proposals)进行分类
- 再次对建议(proposals)进行边界框回归(bounding box regression),获取更高精度的边界框(bounding box)。
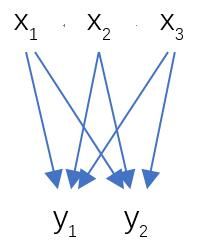
这里来看看全连接层(FC),如图
其计算公式如下:
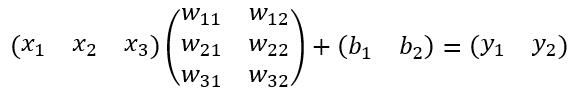
其中权重W和偏置B都是预先训练好的,即大小是固定的,当然输入X和输出Y也就是固定大小。所以,这也就印证了之前感兴趣区域池化(ROI Pooling)的必要性。
参考:
CSDN: 物体检测系列之faster-rcnn原理介绍
知乎: 一文读懂Faster RCNN
知乎: Faster R-CNN 论文阅读记录(一):概览
paper: Faster-RCNN
imooc: Faster R-CNN算法解析
CSDN: 边框回归(Bounding Box Regression)详解
voidcn: faster rcnn源码解析(持续更新中)
pyimagesearch: Intersection over Union (IoU) for object detection
github: Object-Detection-Practice