InnoDB下的MVCC(多版本并行控制)
参考文章:
http://hedengcheng.com/?p=148#_Toc322691905
https://zhuanlan.zhihu.com/p/29532524
一、行锁
InnoDB上的锁分为行锁与表锁。此处只讨论行锁。
1.1 共享锁、独占锁
从类型的角度上,分为共享锁(S锁)与独占锁(X锁)。
执行相关SQL语句的时候,对应的行(或区间)加锁
事务结束(提交或回滚),锁被释放。
类型 |
特点 |
相关语句 |
|---|---|---|
共享锁(S锁) |
一条记录上可以重叠多把S锁,但不能出现X锁 |
select ... lock in share mode |
独占锁(X锁) |
X锁独占记录,此记录上不能再有S锁或者其他的X锁 |
select ... for update/update/delete/insert |
1.2 记录锁、间隙锁
从上锁范围来看,分为记录锁(Record Lock)与间隙锁(Gap Lock)。
Record Lock,锁单条记录
Gap Lock,锁一个开区间
还存在Next-key Lock,相当于一个间隙锁+记录锁,是一个左开右闭区间
加锁不只在主键索引上加锁。如果用到了其他索引,则会①先在该索引上加锁,②再在主键索引上加锁。
以下的讨论以这一张表为例:
id(主键) |
sum(其上有普通索引) |
code(其上有唯一索引) |
1 |
10 |
100 |
2 |
20 |
200 |
5 |
50 |
500 |
7 |
70 |
700 |
8 |
80 |
800 |
11 |
110 |
1100 |
12 |
120 |
1200 |
13 |
130 |
1300 |
15 |
150 |
1500 |
17 |
170 |
1700 |
18 |
180 |
1800 |
20 |
200 |
2000 |
对主键、唯一索引加记录锁
事务T1语句:select * from demo where code = 500 for update; 这一条能够查到对应的记录。此时仅仅锁住一条,即:
code索引上,500的一行被上锁
主键索引上,id=5的一行被上锁
对主键、唯一索引上不存在的值加记录锁
事务T1语句:select * from demo where id = 10 for update; 查不到对应的记录,Gap Lock无法降级为Record Lock。此时:
主键索引上,(8, 11)的区间被锁
对唯一索引上范围锁
事务T1语句:select * from demo where code between 1100 and 1600 for update;
code索引上,(800, 1700)的区间被锁,无法写入
主键索引上,id=11,12,13,15的行被锁
对主键上范围锁
事务T1语句:select * from demo where id between 16 and 30 for update;
主键索引上,(15, +∞)区间被锁,无法写入
对普通索引上记录锁(RR隔离级别)
事务T1语句:select * from demo where sum = 110 for update;
sum索引上,
[80, 120)
区间被锁,无法写入
可见,虽然查询条件是单个值,但是该值的前后两个区间都被锁了。
对普通索引上记录锁(RC隔离级别)
试着把事务隔离级别降级到Read-Committed。事务T1语句:select * from demo where sum = 110 for update;
sum索引上,仅110单个值被锁。此时还可以写入另外一条sum=110的记录
主键索引上,id=11的一行被锁。
隔离级别不一样,上锁的范围也就不一样了。
二、Undo日志
事务读取历史数据,使用到的就是undo日志。
如下图,表的一行不光有本身的数据,还有如下的隐含字段:
事务ID,表明创建(或最新修改)这一行的事务的ID
回滚指针,指向这一行还有可能会被用到的历史版本
删除标记,如果“物理删除”某一行,则这个标记先被置位,并在合适的时机删除
而在开启事务,修改一行的时候,是这么做的:
给这一行加上X锁
把现有的数据复制到undo日志中
修改原有的数据,并让回滚指针指向undo日志
这其中要注意的是:修改的就是原有的记录。
提交事务的时候,反而什么也不要做;undo日志不能马上删除,可能有其他事务需要读取undo日志中的数据
回滚事务时,从undo日志中取出数据,恢复回去

一条数据可能存在多个历史版本。但是由于修改时数据行被上X锁,这些历史数据间一定存在严格的事务先后关系,而不会出现:某个时间点分叉,产生若干种不同版本的数据。
而删除也并不是马上从记录中删除,而是将“删除标记”置位,确保之前的事务可以读到这一条数据。确信没有使用之后,这一条数据才会被真正删除。
关于undo日志的清理,和数据的真正删除,本文不会涉及,若需要请另行寻找资料。
三、一致性非锁定读
在Serializable事务隔离级别下,事务中所有的读取操作,都会给相应的数据行上S锁。Repeatable-Read和Read-Committed隔离级别下,事务中的普通读取操作不会上锁。这称作“一致性非锁定读”。
首先介绍ReadView数据结构。其中与数据可见性相关的字段如下:
dulint low_limit_id; /* 事务号 >= low_limit_id的记录,对于当前Read View都是不可见的 */
dulint up_limit_id; /* 事务号 < up_limit_id ,对于当前Read View都是可见的 */
ulint n_trx_ids; /* Number of cells in the trx_ids array */
dulint* trx_ids; /* 正在执行中的事务id集合(除了本事务之外) */
dulint creator_trx_id; /* 本事务的ID */借着下图来解释一下各个字段的用意。事务ID是随着事务开始时间递增的。在某个事务的ReadView数据对象建立的时候,事务ID的使用情况如下:
一定能在“当前正在执行的事务”中,找到一个事务ID最小的。比这个事务ID还要小的事务,必定是已经提交的事务。up_limit_id即存储这个值
能够拿到“给下一个事务分配的事务ID”。大于等于这个事务ID的,在ReadView创建的时候还没有开始,这些事务的数据当然不可见。low_limit_id即存储这个值
事务ID介于这两个值之间的事务,可能有的还未提交,有的已经提交。未提交的事务,数据当然不可见。将未提交的事务的ID,存入到trx_ids数组中
当然,本事务中的修改对自己可见。将本事务的ID存到creator_trx_id中

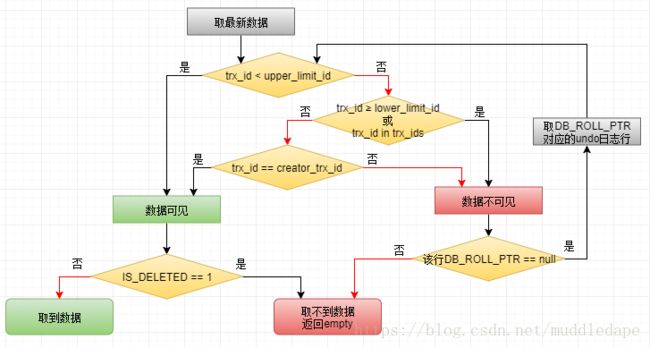
在读取的时候,使用的策略如下(判断顺序可能不一定,并未阅读源代码):
首先取表中的正式记录
根据upper_limit_id、lower_limit_id、trx_ids和creator_trx_id属性,判断该行在本事务中是否可见
如果不可见,则根据DB_ROLL_PTR指针,取undo日志,如果取不到,则返回empty;如果取到了,回到上一步
如果可见,再根据IS_DELETED判断是否已经被删。若是返回empty,若不是则返回取到的数据
在Read-Committed事务隔离级别下,ReadView结构在每次读取的时候都新建一个,因此能够保证读取到已提交事务的改动。
而在Repeatable-Read事务隔离级别下,ReadView是在第一次读取操作时新建,因此能够保证可重复读。
要强调的是:ReadView是在第一次读取操作时新建,而不是在事务开始时新建的。insert/update/delete也不能创建ReadView。以下的操作可以证实这个说法:
事务A |
事务B |
|---|---|
|
begin; ***** |
begin; insert XXX into demo_table; commit; |
|
|
select * from demo_table; |
注意上面表格中,事务B打星号的地方。
如果此处执行了一句select,则ReadView在此处建立。这样,事务B中的select读不到事务A插入的一条数据
如果此处什么都没执行,或者执行的是insert/delete/update这样的语句,则ReadView在最后select操作时才建立。此时的select是可以读取到事务A插入的数据的
但是,“一致性非锁定读”也只能保证,“读”操作可以读取到历史版本。如果是修改操作,仍然是数据表中的最新版本。例如以下的操作:
事务A |
事务B |
|---|---|
begin; insert xxx into demo_table; (插入了id为1、2、3三条数据) |
|
|
begin; select * from demo_table;(ReadView建立) |
|
update demo_table set ... where id = 2;(阻塞) |
commit; |
|
|
阻塞解除,显示修改成功一条 |
|
select * from demo_table; (只能够读取到 id=2 的一条,因为这条记录的trx_id被修改为本事务的id了) |