c/c++简单实现哈利波特文本检索及查询的开发
为什么写这篇博客
文本检索一直是学习一门语言的必经之路,大多数教学都以哈利波特系列的几本书作为文本检索的练习内容,但是直接上手去做这个项目的话,新手可能会感觉力不从心,不知道从哪下手,网上容易搜索到的资源也基本没有专门介绍这个项目的,所以我将它写到博客里,以供广大网友学习交流之用。
本文为原创作品,希望转载的朋友附上我的原文链接。
文本资源下载
百度网盘下载:
链接:https://pan.baidu.com/s/1wxmUvMHWiOnuzB9jhWefKw
提取码:482w
项目要求
【问题描述】
将哈利波特的8本书(txt格式)读入,然后在指定了人名/地名后,显示查询结果,选择指定查询结果序号(选择查询内容),能够显示指定查询结果所在位置前后的一段文字。
【输入形式】
哈利波特的8本书,txt文件
【输出形式】
人名/地名输出:
显示查找到的人名/地名,以及出现的页码和章节,书名, 按照出现的页码顺序显示,每个查询结果都对应序号。
序号 ____ 人名/地名_____页码_____章节______书名
1_________Harry________1________1 _______Harry_Potter_and_the_Chamber_of_Secrets_Book_2
选择查询结果记录项时,显示指定的人名/地名位置前后的一段文字。
选择序号,或者单击查询记录行,能够显示到指定位置人名/地名前后的一段文字。如选择序号1,应显示:
Not for the first time, an argument had broken out over breakfast at number four, Privet Drive. Mr. Vernon Durs-
ley had been woken in the early hours of the morning by a loud, hooting noise from his nephew Harry’s room.
基本思路梳理
1.如何读取文本内容
c++的 fstream 头文件是专门用来对文本进行操作的,关于 fstream 的用法在这里不作过多介绍,详情请看菜鸟教程
https://www.runoob.com/cplusplus/cpp-files-streams.html
(1)首先,就是打开文本,并读取内容。读取文本内容有按行读取和按字符读取,这里我们使用按行读取。
ifstream in("J.K. Rowling - HP 3 - Harry Potter and the Prisoner of Azkaban.txt");
string line;
if(in) //判断是否成功打开文件
while(getline(in, line)) //此时每读取一行,都会重新给line赋值,即每读取一行,该行的内容便存在line中
{
cout << line; //输出每次读取到的内容,到最后即把文本全部显示在控制台界面上
}
(2)此时我们便要依次把8本书都读取一遍,看看程序是否错误,但是在第2本和第6本的读取过程中,突然报错如下:
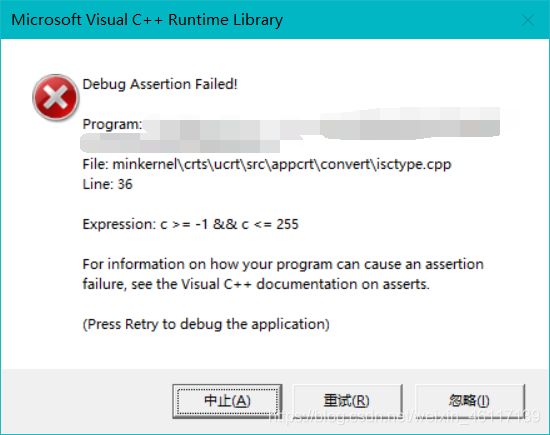
原因就是这两本书里含有中文字符,而现在默认的读取方式是英文,所以会报错,解决方法如下:
setlocale(LC_ALL, "zh-CN");
setlocale() 函数的目的是设置区域(即设置语言),这里 LC_ALL 表示设定区域的覆盖范围包含全部,即文本内的所有内容都按照设置的区域的语言去读取,而 “zh-CN” 则表示中文,即可以读取中文字符,这样就解决了文本2和文本6无法读取的问题了。
2.读取到的内容怎么存到正在运行的程序中
可以使用 vector 容器或者 deque 双端队列来在读取文本的同时将内容实时保存下来,以便后面查询的时候使用。
关于 vector 的用法:https://blog.csdn.net/duan19920101/article/details/50617190
关于 deque 的用法:https://blog.csdn.net/longshengguoji/article/details/8519812
(1)这里使用deque双端队列来存储读取到的信息,我们希望把项目要求的章节、页码、书名和该段信息作为一个整体存到队列中,所以首先我们要定义一个Text类,这个类中包括了我们想要的所有信息,之后就可以直接新建一个Text类的对象,对对象进行操作,然后把对象存到队列中
class Text //定义文本(Text)类
{
public:
int page; //页码
int chapter; //章节
string bookName; //书名
string content; //单段内容
};
(2)定义完Text类之后,我们就需要一个双端队列来存储Text类的对象了。
deque <Text> text; //定义一个Text类的双端队列,存储文本内容
Text one_Content; //定义一个Text类的对象,便于之后的操作
这里的 text 队列和 Text 的对象 one_Content 都是全局定义,目的是在后面可以直接使用,避免了不同函数之间需要增加接口的麻烦。
(3)解决了存储文本的容器的问题,现在我们就需要往text这个队列里边存东西了。但是摆在我们面前的又有几个问题:
①如何判断读取到的内容到底是章节、页码还是正文;
②如何把读取到的内容存到text队列里。
void get_text(string book, int ch = 0) //读取并保存文本内容
{
setlocale(LC_ALL, "zh-CN"); //解决文本2和6有中文字符的问题
ifstream in("TXT\\"+ book + ".txt"); //拼接路径
string line, con; //存储按行读取到的内容
one_Content.bookName = book; //初始化对象
one_Content.page = 1;
one_Content.chapter = ch;
int len = 0;
if (in) // 有该文件
{
while (getline(in, line))
{
len = line.length();
if (len <= 20 && len > 0) //判断是章节名或者是页码
{
int counts = 0;
for (int i = 0; i < len; i++)
if (isdigit(line[i]))
counts++;
if (counts == len)
one_Content.page = atoi(line.c_str()) + 1; //是页码
else
{
transform(line.begin(), line.end(), line.begin(), ::tolower);
if (line.substr(0, 7) == "chapter")
one_Content.chapter++; //是章节
}
}
else
{
one_Content.content = line;
text.push_back(one_Content);
}
}
}
else
cout << "不存在此文本:" << book << endl;
}
解释如下:
①在这里我们直接定义一个函数 get_text(string book, int ch = 0) ,封装录入文本的方法,便于后期管理。 其中的第一个参数 book ,为传入的书名,因为我们定义的Text类中需要单独的书名的出现,所以我们便从外部只传入书名, 至于第二个参数 ch ,到后面自会讲解。
②因为我们传入的 book 是书名,所以要想实现文本读取,还需要进行一步路径拼接的操作,拼接成完整路径之后就能顺利读取内容了。
③之后便是对于 one_Content 对象的初始化了,初始页码为1, 初始章节为传入的参数 ch ,默认是0。这样便可以保证每本书一开始都是第一章,但是第一本书又是特例,是从第0章开始的,所以要传入的是-1,这条解释要结合地⑥条对比着理解。
④经过多个文本比对你会发现凡是章节名、页码,该行长度都不会超过20,但是为了避免遍历溢出的情况,还需要长度大于0,即所有的章节、页码都符合该行长度大于0,小于20,如果读取到了这样的行,我们便可以对其进行检测,看是否是章节或者页码。
⑤ isdigit() 函数用来判断参数是否为数字,如果该行表示页码,那么必然是一整行都是数字,即满足 count == len,由此我们便可以充分判定这行就是页码。但是再仔细观察一下文本,页码都是写在页末的,但是我们从页头开始便要存储信息,即需要页码信息,不可能先跳到页末去寻找页码,再返回来存储信息,所以我们将初始页码设置为1,以后每读取到一次页码,便代表这一行的信息已经读取完成,下次读取的是下一页的信息了,所以便给页码+1,至于 atoi(line.c_str()) 这句,目的是将存储数字的字符串转换成整型,也可以直接将本行代码改为one_Content.page++,效果一样。
⑥如果确定该行是页码,那么更新页码就行了,但是如果不是页码呢,就一定是章节吗?通过观察文本我们发现,还有其他文本内容也满足长度大于0,小于20 这个条件,所以我们要再进行一次判断。但是细心的你又会发现,这8本书对于表示章节的 chapter 有着大小写结合的许多种写法,要判断是不是章节,有两种方式:取前七个字符,
第一种,把文本中出现的所有chapter的写法都罗列出来,挨个用 if 语句判断,第二种,直接把该行文本全部转换为小写(或大写),与 chapter (或CHAPTER)进行比对,这里我们选择更为便捷的第二种方法。
transform(line.begin(), line.end(), line.begin(), ::tolower) 的目的是将该行内容转换为小写。如果检测到章节,便表示下一次读取的是下一个章节的内容,要给章节+1,道理同页码的增加方式。
⑦对于长度大于0,小于20 的行都处理完了,剩下的除了空行便是内容行,直接赋值给 one_Content.content,更新对象中的内容即可,操作完这一切之后便可以将 one_Content 添加到 text 队列里边了。当然,细心的朋友会发现,满足长度大于0,小于20 但既不是章节也不是页码的行岂不是丢失了吗,经过观察文本,我们发现这类内容对整体检索没有影响,可以不要,也可以添加进去。
就这样,就完成了从文本中读取信息,并保存到正在运行的程序中了。此外,我们还需要把所有的书目都给 get_text() 函数传入:
void input_Book() //传入文本信息
{
get_text("J.K. Rowling - HP 0 - Harry Potter Prequel", -1); //第一本是从第0章开始的,所以传入-1;后面的都是从第1章开始,所以不用传
get_text("J.K. Rowling - HP 2 - Harry Potter and the Chamber of Secrets");
get_text("J.K. Rowling - HP 3 - Harry Potter and the Prisoner of Azkaban");
get_text("J.K. Rowling - HP 4 - Harry Potter and the Goblet of Fire");
get_text("J.K. Rowling - HP 6 - Harry Potter and the Half-Blood Prince");
get_text("J.K. Rowling - HP 7 - Harry Potter and the Deathly Hallows");
get_text("J.K. Rowling - Quidditch Through the Ages");
get_text("J.K. Rowling - The Tales of Beedle the Bard");
}
3.用户输入要查询的 人名/地名 之后,如何查询
(1)有了已经存下来的 text 队列的数据,我们便可以轻松实现信息的查找了。
void search_in_File(string info, deque<Text> & s) //查找信息
{
int all_len = text.size();
string::size_type p;
for (int i = 0; i < all_len; i++)
{
p = text[i].content.find(info);
if (!(p == string::npos))
s.push_back(text[i]);
}
}
解释如下:
①同样,我们用函数封装起来,这个函数传入两个参数,分别是用户输入的要查询的 人名/地名 info 和 在主函数中定义的 Text类型的队列的引用(主函数中的定义为 deque ,这个队列的使用范围并不是所有函数都要用到,所以没必要定义为全局量)。
② find()函数是 string 里匹配子串的函数,如果子串在原串中出现,则返回子串第一个字符在原串中的地址,否则返回 npos。 npos 表示 size_type 的最大值,用来表示不存在的位置。find()成员函数的返回值为 size_type。目的是判断用户输入的字符串是否在 text 队列中的某一个对象的 content 中出现,如果出现,即检索到了想要的信息,把该对象添加到 s 队列(s 是 主函数中定义的 search_Info 队列的引用,所以可以直接操作)中,遍历 text 即可实现把所有的有效信息都存到 s 队列中。
这样,对于用户输入的信息的检索就完成了。
(2)下一步,便是显示出查询的的信息,直接对 search_Info 队列进行遍历输出即可。
void show_Info(deque<Text> s, string info) //显示查询结果
{
cout << "序号 人名/地名 页码 章节 书名" << endl;
for (int i = 0; i < s.size(); i++)
cout << " "
<< i + 1 << " "
<< info << " "
<< s[i].page << " "
<< s[i].chapter << " "
<< s[i].bookName << endl;
}
至此,项目要求的功能已基本实现,剩余的小功能直接在主函数中实现即可,主函数源代码如下。
源代码
代码仅作学习交流之用,请勿抄袭,尊重版权。
如有不当之处还请不吝指正,谢谢!
/*********************************************************
** 哈利波特小说文本检索程序 **
** 作者:木笔# **
** 博客(csdn):木笔# **
** 日期:2020-6-8 **
** 尊重版权,请勿抄袭 **
*********************************************************/
#include 关于此项目总结几点经验:
①实现不同的功能,尽量用不同的函数或者类封装起来,既便于后期维护,也有利于他人阅读理解,同时还能提高自己的统筹规划能力。
②遇到困难多上网,互联网的时代,如果不会在网上解决问题,那真的不是一个合格的程序员。
有任何问题请及时在下方评论区留言,谢谢!
本期教程到这里就结束了,如果感觉对您有所帮助,就帮我点一个赞支持一下吧~~~