GPU编程自学10 —— 流并行
深度学习的兴起,使得多线程以及GPU编程逐渐成为算法工程师无法规避的问题。这里主要记录自己的GPU自学历程。
目录
- 《GPU编程自学1 —— 引言》
- 《GPU编程自学2 —— CUDA环境配置》
- 《GPU编程自学3 —— CUDA程序初探》
- 《GPU编程自学4 —— CUDA核函数运行参数》
- 《GPU编程自学5 —— 线程协作》
- 《GPU编程自学6 —— 函数与变量类型限定符》
- 《GPU编程自学7 —— 常量内存与事件》
- 《GPU编程自学8 —— 纹理内存》
- 《GPU编程自学9 —— 原子操作》
- 《GPU编程自学10 —— 流并行》
十、 流并行
我们前面学习的CUDA并行程序设计,基本上都是在一批数据上利用大量线程实现并行。 除此之外, NVIDIA系列GPU还支持另外一种类型的并行性 —— 流。
GPU中的流并行类似于CPU上的任务并行,即每个流都可以看作是一个独立的任务,每个流中的代码操作顺序执行。
下面从流并行的基础到使用来说明。
10.1 页锁定内存
流并行的使用需要有硬件支持:即必须是支持设备重叠功能的GPU。
通过下面的代码查询设备是否支持设备重叠功能:
cudaDeviceProp mprop;
cudaGetDeviceProperties(&mprop,0);
if (!mprop.deviceOverlap)
{
cout << "Device not support overlaps, so stream is invalid!" << endl;
}只有支持设备重叠,GPU在执行一个核函数的同时,才可以同时在设备与主机之间执行复制操作。 当然,这种复制操作需要在一种特殊的内存上才可以进行 —— 页锁定内存。
- 页锁定内存: 需要由cudaHostAlloc()分配,又称为固定内存(Pinned Memory)或者不可分页内存。 操作系统将不会对这块内存分页并交换到磁盘上,从而确保了该内存始终驻留在物理内存中,因为这块内存将不会被破坏或者重新定位。 由于gpu知道内存的物理地址,因此可以通过“直接内存访问(Direct Memory Access,DMA)” 直接在gpu和主机之间复制数据。
- 可分页内存: malloc()分配的内存是标准的、可分页的(Pagable)主机内存。 可分页内存面临着重定位的问题,因此使用可分页内存进行复制时,复制可能执行两次操作:从可分页内存复制到一块“临时”页锁定内存,然后从页锁定内存复制到GPU。
虽然在页锁定内存上执行复制操作效率比较高,但消耗物理内存更多。因此,通常对cudaMemcpy()调用的源内存或者目标内存才使用,而且使用完毕立即释放。
10.2 流并行机制
流并行是指我们可以创建多个流来执行多个任务, 但每个流都是一个需要按照顺序执行的操作队列。 那么我们如何实现程序加速? 其核心就在于,在页锁定内存上的数据复制是独立于核函数执行的,即我们可以在执行核函数的同时进行数据复制。
这里的复制需要使用cudaMemcpyAsync(),一个以异步执行的函数。调用cudaMemcpyAsync()时,只是放置一个请求,表示在流中执行一次内存复制操作。当函数返回时,我们无法确保复制操作已经结束。我们能够得到的保证是,复制操作肯定会当下一个被放入流中的操作之前执行。(相比之下,cudaMemcpy()是一个同步执行函数。当函数返回时,复制操作已完成。)
以计算 a + b = c为例,假如我们创建了两个流,每个流都是按顺序执行:
复制a(主机到GPU) -> 复制b(主机到GPU) -> 核函数计算 -> 复制c(GPU到主机)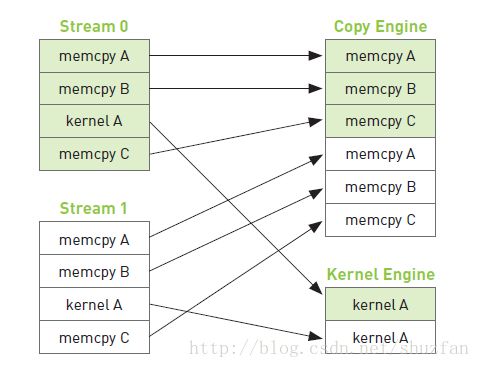
如上图,复制操作和核函数执行是分开的,但由于每个流内部需要按顺序执行,因此复制c的操作需要等待核函数执行完毕。 于是,整个程序执行的时间线如下图:(箭头表示需要等待)

从上面的时间线我们可以启发式的思考下:如何调整每个流当中的操作顺序来获得最大的收益? 提高重叠率。
如下图所示,假如复制一份数据的时间和执行一次核函数的时间差不多,那么我们可以采用交叉执行的策略:

由于流0的a和b已经准备完成,因此当复制流1的b时,可以同步执行流0的核函数。 这样整个时间线,相较于之前的操作很明显少掉了两块操作。
10.3 流并行示例
与流相关的常用函数如下:
// 创建与销毁
cudaStream_t stream//定义流
cudaStreamCreate(cudaStream_t * s)//创建流
cudaStreamDestroy(cudaStream_t s)//销毁流
//同步
cudaStreamSynchronize()//同步单个流:等待该流上的命令都完成
cudaDeviceSynchronize()//同步所有流:等待整个设备上流都完成
cudaStreamWaitEvent()//等待某个事件结束后执行该流上的命令
cudaStreamQuery()//查询一个流任务是否完成
//回调
cudaStreamAddCallback()//在任何点插入回调函数
//优先级
cudaStreamCreateWithPriority()
cudaDeviceGetStreamPriorityRange()下面给出一个2个流执行a + b = c的示例, 我们假设数据量非常大,需要将数据拆分,每次计算一部分。
#include 256, 256, 0, stream0 >> >(dev_a0, dev_b0, dev_c0);
// 执行流1核函数
add << 256, 256, 0, stream1 >> >(dev_a1, dev_b1, dev_c1);
// 复制流0数据c
cudaMemcpyAsync(host_c + i*N, dev_c0, N*sizeof(int), cudaMemcpyDeviceToHost, stream0);
// 复制流1数据c
cudaMemcpyAsync(host_c + i*N+N, dev_c1, N*sizeof(int), cudaMemcpyDeviceToHost, stream1);
}
// 流同步
cudaStreamSynchronize(stream0);
cudaStreamSynchronize(stream1);
// 处理计时
cudaEventSynchronize(stop);
cudaEventRecord(stop, 0);
cudaEventElapsedTime(&elapsedTime, start, stop);
cout << "GPU time: " << elapsedTime << "ms" << endl;
// 销毁所有开辟的内存
cudaFreeHost(host_a); cudaFreeHost(host_b); cudaFreeHost(host_c);
cudaFree(dev_a0); cudaFree(dev_b0); cudaFree(dev_c0);
cudaFree(dev_a1); cudaFree(dev_b1); cudaFree(dev_c1);
// 销毁流以及计时事件
cudaStreamDestroy(stream0); cudaStreamDestroy(stream1);
cudaEventDestroy(start); cudaEventDestroy(stop);
return 0;
} 参考资料
- 《CUDA by Example: An Introduction to General-Purpose GPU Programming》 中文名《GPU高性能编程CUDA实战》