Causal Inference in Statistics读书笔记-chapter1
Chapter1
Preliminaries: Statistical and Causal Models
1. Why Study Causation
“causation”的意思是因果关系,学习因果关系是因为我们需要通过理解数据来做出更好的决策和行动,从失败或者成功的经历中获取知识。作者通过辛普森悖论来讲述了因果关系在统计学习中的重要性。
## Simpson 悖论 我们想测试一种新研制出的药物对A疾病是否有效,邀请了700位病人来进行试验,其中一半服用新药,一半不服用。得到的结果如下表: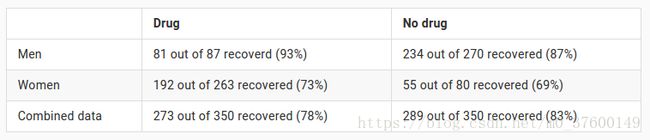
根据实验结果,如果是女/男患者,那么医生应该给患者服用新药,如果是一个不知性别的患者,那到底我们应该根据性别分组的结果给患者用药呢,还是根据总体数据的结果不给患者用药呢?这就是由于缺少问题因果关系而产生的悖论。
在变量连续的问题上同样存在这样的问题。

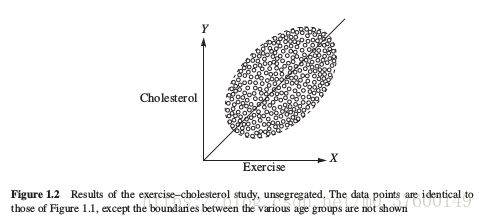
如果不考虑年龄的话,Cholesterol跟Exercise是正相关的,一旦考虑了年龄,二者就是负相关的。
由上面两个例子可以看出,利用传统的统计方法,我们很难直接从数据中获得因果关系的信息,通常我们都是对因果关系进行假设,比如上面的例子中假设性别对药效是有影响的,但这样的假设很可能导致悖论的发生。所以我们考虑 利用额外的统计方法来表达因果关系假设,这些方法就是这本书的重点。为了理解数据背后的因果关系,我们需要解决下面几个问题:
- 如何定义因果关系(causation)
- 如何表达因果关系的假设,即如何建立一个因果模型(causal model)
- 如何将因果模型和数据特征连接起来
- 如何通过结合数据及模型中隐藏的因果关系假设来得出结论
首先定义causation,如果变量Y的取值依赖于变量X的取值,我们说X是产生Y的原因(X is a cause of Y).其余问题在书后面几章进行回答。
2.Perimilinaries
下面是一下必要的统计知识和图论知识。
Independent 独立
我们称事件 A A 与事件 B B 相互独立,当 P(A|B)=P(A) P ( A | B ) = P ( A ) 时。
Conditionally Independent 条件独立
条件独立是图网络一个很重要的概念。两个事件A和B,对另一事件C,如果满足
则称事件A与事件B条件独立。
贝叶斯公式
全概率公式
对于事件 A A 和一系列事件 B1,B2…Bn B 1 , B 2 … B n ,事件 A A 发生的概率
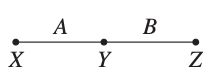

将 X,Y X , Y 作为外生变量, Z Z 为内生变量, fZ:(X,Y)↦Z f Z : ( X , Y ) ↦ Z
乘积分解
对于所有无环图,有下面的乘积分解式成立,
pai p a i 表示 Xi X i 的父节点。比如一个简单的链式图, X→Y→Z X → Y → Z
公式成立是基于各节点间的独立关系,这个将会在下一章中详细解释。
接下来就该进入第二章啦~~~