Hadoop之hive 第二天 (分区关键字partitioned by)
创建分区表
hive> create table test_4(ip string,url string,staylong int) partitioned by(day string) row format delimrminated by ',';
准备数据
[root@Tyler01 home]# vi pv.data
在hive中加载本地数据。
hive> load data local inpath '/home/pv.data' into table test_4 partition(day='2019-05-10');
#local是加载本地,不加local则加载hdfs的数据
在hdfs上查看hive中加载的数据。
[root@Tyler01 home]# hadoop fs -cat /user/hive/warehouse/test_4/day=2019-05-10/pv.data
19/09/06 15:16:36 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
192.168.9.10,www.a.com,1000
192.168.10.10,www.b.com,100
192.168.11.10,www.c.com,900
192.168.12.10,www.d.com,100
192.168.13.10,www.e.com,2000

在写一个文件的数据
[root@Tyler01 home]# vi pv.data-2019-05-11
在hive中加载这个数据
hive> load data local inpath '/home/pv.data-2019-05-11' into table test_4 partition(day='2019-05-11');

day='2019-05-11’与day='2019-05-10’同级,说明就分区了。
hive查询
hive> select * from test_4;
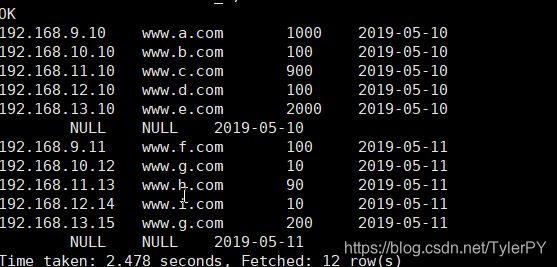
有两行空是因为在编辑数据的时候多了一行空格。多按了下回车。
分区查询
hive> select * from test_4 where day='2019-05-11';

查看2019-05-11这天的访问人数
hive> select distinct ip from test_4 where day="2019-05-11";

导入数据
在hive中加载本地数据导入到已存在的表中。
ive> load data local inpath '/home/pv.data-2019-05-11' overwrite into table test_1;
Loading data to table default.test_1
Table default.test_1 stats: [numFiles=1, numRows=0, totalSize=137, rawDataSize=0]
OK
Time taken: 1.517 seconds
查看表
hive> select * from test_1;
OK
192.168.9.11 www.f.com 100
192.168.10.12 www.g.com 10
192.168.11.13 www.h.com 90
192.168.12.14 www.i.com 10
192.168.13.15 www.g.com 200
NULL NULL
Time taken: 0.434 seconds, Fetched: 6 row(s)
从别的表查询数据后插入到一张新建表中
hive> create table t_1jz as select id,name from test_1;
like复制表结构,不复制内容
hive> create table t_1hd like test_2;
OK
Time taken: 0.521 seconds
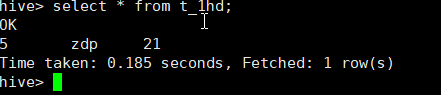
hive> select * from t_1hd;
OK
Time taken: 0.442 seconds
hive> select * from t_1hd;
往t_1hd表中插入数据
hive> insert into table t_1hd select *from test_2 where name='wahaha'
> ;
Automatically selecting local only mode for query
Query ID = root_20190906163525_3a162223-ea03-49a1-af4f-a9eceba213c7
Total jobs = 3
Launching Job 1 out of 3
Number of reduce tasks is set to 0 since there's no reduce operator
Job running in-process (local Hadoop)
2019-09-06 16:35:30,421 Stage-1 map = 0%, reduce = 0%
2019-09-06 16:35:31,434 Stage-1 map = 100%, reduce = 0%
Ended Job = job_local1965711162_0001
Stage-4 is selected by condition resolver.
Stage-3 is filtered out by condition resolver.
Stage-5 is filtered out by condition resolver.
Moving data to: hdfs://Tyler01:9000/user/hive/warehouse/t_1hd/.hive-staging_hive_2019-09-06_16-35-25_256_7229741555640883680-1/-ext-10000
Loading data to table default.t_1hd
Table default.t_1hd stats: [numFiles=1, numRows=2, totalSize=24, rawDataSize=22]
MapReduce Jobs Launched:
Stage-Stage-1: HDFS Read: 841 HDFS Write: 20798852 SUCCESS
Total MapReduce CPU Time Spent: 0 msec
OK
Time taken: 7.811 seconds

用like插入数据
like’x%’ 第一个字符是x %是任意匹配。
hive> insert into table t_1hd select id,name,age from test_2 where name like'x%';
查看插入的数据
hive> select * from t_1hd;
OK
2 wahaha 22
2 wahaha 22
2 wahaha 22
2 wahaha 22
1 xiaoming 20
1 xiaoming 20
3 xioahuang 34
Time taken: 0.167 seconds, Fetched: 7 row(s)
overwrite (重写)
hive> insert overwrite table t_1hd select * from test_2 where name like 'z%';
分区导入另一张表
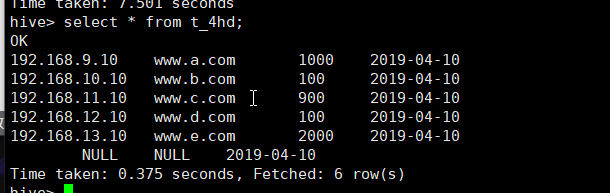
hive> insert into table t_4hd partition(day='2019-04-10') select ip,url,staylong from test_4 where day='2019-05-10;
导出数据
将数据从hive的表中导出达到hdfs的目录中。关键字(directory )
hive> insert overwrite directory '/aa/test_2' select * from test_2 where name like 'x%' and '%a';
在hdfs上查看


将上面的数据按逗号拆分。
[root@Tyler01 home]# hive -e "select * from test_2" | tr "\t" "," > result.csv

HIVE的存储文件格式
HIVE支持很多种文件格式: sequence file | text file | parquet file | rc file
修改表的分区
查看表分区
hive> show partitions test_4;
OK
day=2019-05-10
day=2019-05-11
Time taken: 2.43 seconds, Fetched: 2 row(s)
添加分区
hive> alter table test_4 add partition(day='2019-05-12') partition(day='2019-03-11');

向分区加载数据(load)
hive> load data local inpath '/root/pv.data.2019-05-12' into table test_4 partition(day='2019-03-11');
向分区加载数据(insert)
hive> insert into table test_4 partition(day='2019-05-16') select * from test_4 where staylong>80 and partition(day='2019-05-11');
![]()
Hive> insert into table test_4 partition(day='2019-05-13')
select ip,url,staylong from test_4 where day='2019-05-11' and staylong>20;
hive> select * from test_4 where day='2019-05-13';
删除分区
hive> select * from test_4 where day='2019-05-13';
hive> select * from test_4;

修改表结构
添加列
原始表
hive> desc test_1;
OK
id string
name string
age int
Time taken: 0.766 seconds, Fetched: 3 row(s)
添加address字段(columns)
OK
Time taken: 1.456 seconds
hive> desc test_1;
OK
id string
name string
age int
address string
Time taken: 0.682 seconds, Fetched: 4 row(s))
hive> alter table test_1 add columns(address string);
OK
Time taken: 1.456 seconds
hive> desc test_1;
OK
id string
name string
age int
address string
Time taken: 0.682 seconds, Fetched: 4 row(s)
重新定义表结构(replace)
hive> alter table test_1 replace columns(id int,name string,age int);
OK
Time taken: 3.091 seconds
hive> desc test_1;
OK
id int
name string
age int
Time taken: 1.45 seconds, Fetched: 3 row(s)
修改已存在的列
hive> alter table test_1 change id uid string;
OK
Time taken: 1.343 seconds
hive> desc test_1;
OK
uid string
name string
age int
Time taken: 0.899 seconds, Fetched: 3 row(s)
显示命令
显示表分区
hive> show partitions test_4;
内置函数
hive> show functions;
表结构
hive> desc test_4;
表定义的详情信息
hive> desc extended test_4;
显示表定义的详细信息,并且用比较规范的格式显示
hive> desc formatted test_4;
清空表数据,保留表结构
hive> truncate table test_4_st_200;
设置本地运行hive的mapreduce,不提交给yarn
hive>set hive.exec.mode.local.auto=true;
单条插入数据
hive> insert into table t_seq values('10','xx','beijing',28);
查看数据
hive> select * from t_1hd;
OK
5 zdp 21
10 hahaaa 32
Time taken: 9.659 seconds, Fetched: 2 row(s)
多重插入
先创建个分区表
hive> create table test_44st like test_4;
OK
Time taken: 1.73 seconds
添加分区
由于此表已有day分区,若在加其他分区会出错。如下:
hive> alter table test_44st add partition(condition='lt200');
FAILED: ValidationFailureSemanticException Partition spec {condition=lt200} contains non-partition columns
添加day分区就可以
hive> alter table test_44st add partition(day='lt200');
OK
Time taken: 1.246 seconds
条件插入数据
hive> insert into table test_44st partition(day='lt200') select ip,url,staylong from test_4 where staylong<200;
查看数据
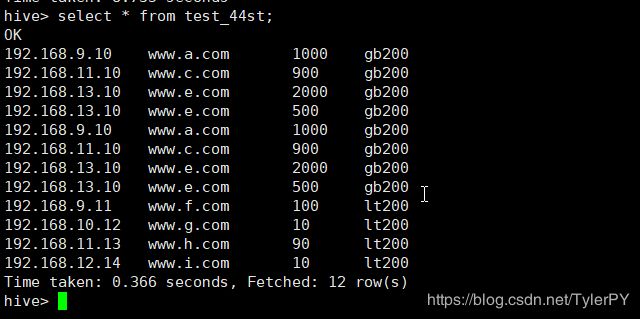
hive> select * from test_44st;
OK
192.168.9.11 www.f.com 100 lt200
192.168.10.12 www.g.com 10 lt200
192.168.11.13 www.h.com 90 lt200
192.168.12.14 www.i.com 10 lt200
Time taken: 1.788 seconds, Fetched: 4 row(s)
添加数据
hive> insert into table test_44st partition(day='gb200') select ip,url,staylong from test_4 where staylong>200;
多重条件插入数据
hive> from test_4
> insert into table test_44st partition(day='lt200')
> select ip,url,staylong where staylong<200
> insert into table test_44st partition(day='gt200')
> select ip,url,staylong where staylong<200;
