spark 存储分析(六)
文章目录
- 前言
- 1. 整体架构
- 2. RDD存储过程
- 2.1 存储级别
- 2.2 RDD存储调用
- 2.3 RDD读数据过程
- 2.3.1 本地读取数据
- 2.3.2 远程读取:
- 2.4 RDD写数据过程
- 3 shuffle 存储过程
- 3.1 shuffle的写操作
- 3.2 Shuffle的读操作
- 4 序列化和压缩
- 4.1 序列化
- 4.2 压缩(具体展开还需要查阅资料)
- 5 共享变量(细节需要查阅资料)
- 5.1 广播变量
- 5.2 累加器
前言
本文还有诸多不明朗的地方,会在后续查阅后,进行补充。
共享变量。
shuffle过程。
shuffle写过程中,关于Map和reduce对数据处理的流程。
1. 整体架构

- Master(__这里的Master端是作为Master/Slave结构的master部分,并不是常规一样上的Master/Worker __)负责运行期间数据块。元数据的管理和维护,slave 一方面将本地数据块上报给Master,一方面接收从Master传过来的执行命令,如删除RDD/数据块等。
- 在Driver端(客户端)实例化 BlockManager和BlockManagerMaster。
- slave也会在启动Executor时,也会创建BlockManager,并和Driver端相互通信。
- 当slave写入、更新或者删除数据完毕后,发送数据块的最新状态消息给Driver,让其更新数据块元信息。(元数据包括ExecutorId,blockManagerId等),当blockManangerInfo和blockLocations两个列表。
- app数据存储后,如果Executor在RDD操作时,需要获取数据块的编号和位置,需要发送请求给BlockManangerMasterEndpoint终端点(Driver),来查询数据块位置信息。
- spark提供删除RDD,数据块和广播变量等方式。当数据需要删除时,需要发送请求给BlockManangerMasterEndpoint终端点(Driver),在该终端点发起删除操作,一方面要删除该数据块的元数据,另一方面要发送消息通知Executor,删除对应的物理数据。
- blokckManager存在于Driver端和每个Executor中,在Driver端的blockManager保存了数据元信息(这里的Driver端是作为Master/Slave结构的master部分),而Executor的BlockManager根据接收到消息进行操作。
- Executor接收到读取数据,根据数据块若为本地,则直接调用MemoryStore和DiskStore的getValues/getBytes进行读取,如果是远程则调用BlockTransferService的服务进行获取。
- 当Executo接收到写入数据时,如果不需要创建副本,则直接调用BlockStore进行处理。
模块类关系

2. RDD存储过程
2.1 存储级别
- RDD不仅可以存储在内存中,还可以存储在磁盘中。
- 由于persist只是一种控制操作,它只修改了RDD的元信息,并没有进行实际的存储,当RDD的iterator方法中,才进行真正的存储。
- RDD第一次被计算时,persist方法会根据参数StoreLevel的设置采取特定的策略。
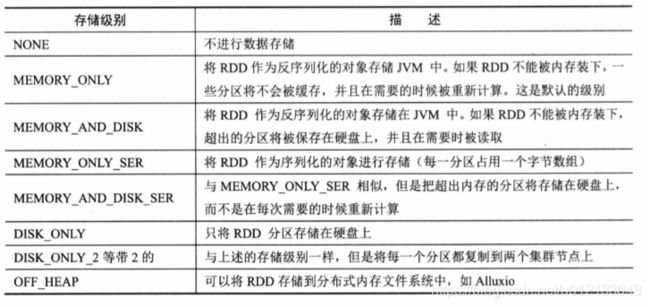
- StorageLevel有5个参数,useDisk,useMemory,useOffHeap,deserialized,replications。根据不同的参数组合有12中储存级别。其分别代表的意义为磁盘,内存,堆外内存(或者是其他分布式内存系统),序列化,以及副本。
val NONE = new StorageLevel(false,false,false,false)
val DISK_ONLY = new StorageLevel(true,false,false,false)
val DISK_ONLY_2 = new StorageLevel(true,false,false,false,2)
val MEMORY_ONLY = new StorageLevel(false,true,false,true)
val MEMORY_ONLY_2 = new StorageLevel(false,true,false,true,2)
val MEMORY_ONLY_SER = new StorageLevel(false,true,false,false)
val MEMORY_ONLY_SER_2 = new StorageLevel(false,true,false,false,2)
val MEMORY_AND_DISK = new StorageLevel(true,true,false,true)
val MEMORY_AND_DISK_2 = new StorageLevel(true,true,false,true,2)
val MEMORY_AND_DISK_SER = new StorageLevel(true,true,false,false)
val MEMORY_AND_DISK_SER_2 = new StorageLevel(true,true,false,false,2)
val OFF_HEAP = new StorageLevel(false,false,true,false)
2.2 RDD存储调用
- RDD和block的关系。RDD----->n个partition------->n个block(数据块),也就是说partition和block是一一对应的关系。每个RDD有一个或多个Block,每个block有特定的id,rdd_ + rddId + _ + splitIndex,其中splitIndex为数据块对应的partition编号。
- Executor任务运行时,先根据block的编号判断当前是否已经有数据,如果有则直接读取并计算,否则临时计算并存储。
2.3 RDD读数据过程
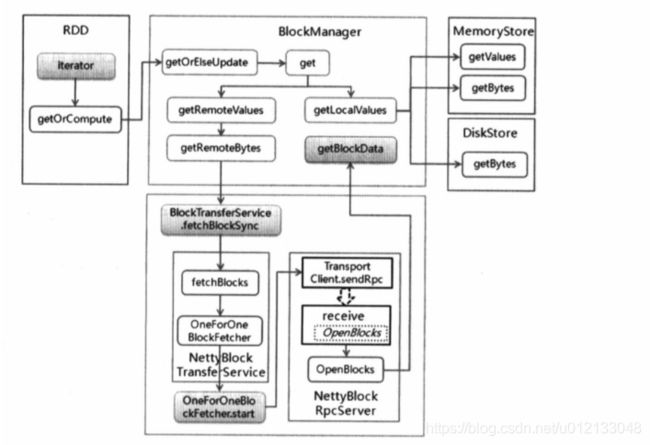
BlockManager的get方法是读数据的入口,读数据分为两类:本地读取和远程读取。
- 本地读取则直接调用getLocalValues方法,根据不同的存储级别调用不同的实现方法。
- 远程读取则使用getRemoteValues方法,调用远程数据传输发服务类BlockTransferService。
2.3.1 本地读取数据
不同存储级别对应的读取操作:
-
内存读取:
- 本地读取内存中的数据,有两种读取方式分别为MemoryStore中的getValues和getBytes两种方法,分别对应内存存储中是否进行序列化,如果是经过序列化存储在JVM中则使用getBytes,获取字节流后,再进行反序列化,否则使用getValues。
- 读取完成后,返回block大小,读取方法等元数据信息。
- MemroyStore的getValue和getByte方法都是根据blockId来读取数据的,而spark的内存储存其实是使用了一个大的LinkedHashMap,记录了插入的顺序,遍历时,先到先得,由于内存的大小限制和LinkedHashMap的特性,先保存的数据会被清除,类似于FIFO。 -
磁盘读取:
- 磁盘读取在getLocalValues方法中,调用的是DiskStore的getBytes方法,从磁盘中读取后,需要将这些数据缓存在内存中,并根据存储级别判断是否需要反序列化。如果存储级别需要反序列化,则从磁盘中读取数据后,经过反序列化存储到内存中,否则直接存储,等需要使用时再进行反序列化处理。
- b)读取完毕后,返回数据以及数据块大小、读取方法等信息。
- c)spark的spark.local.dir设置了词频存储的第一层目录。一般情况下,设置1个一级目录,并在一个一级目录下最多创建64个二级子目录。一级目录的命名为Spark-UUID.randomUUID,其中UUID.randomUUID是16位的UUID; 二级目录以数据命名,00-63; 目录中文件的名字是数据块的名称blockId.name 其中二级目录启动时并不创建,有数据操作时才创建。- d)读取文件时,以RandomAccessFile的只读方式打开该文件,通过偏移量来读取指定大小,如果文件足够小,则直接读取,较大的文件则通过指定文件的区域直接映射到内存中进行读取。
2.3.2 远程读取:
远程读取的关键在于,如何获取数据位置。
- 远程读取的入口为getRemoteValues,调用getRemoteBytes方法,在该方法中调用getLocations,向Driver端的BlockManangerMasterEndpoint终端点发送请求数据块所在的位置。
- Driver端接收到请求后,根据数据块的编号获取所在位置,返回数据。
- Executor获取到数据块位置信息后,根据是否是本地节点数据对位置信息进行排序(优先读取本地节点)
- 获取数据块位置列表后,发送请求到对应的节点中。
- 远程节点接收到消息后,对消息进行匹配,如果是读取消息,则调用本地getBlockData方法读取数据,将读取到的数据块封装成ManangerBuffer缓存后,使用netty将数据返回,完成传输任务。
2.4 RDD写数据过程
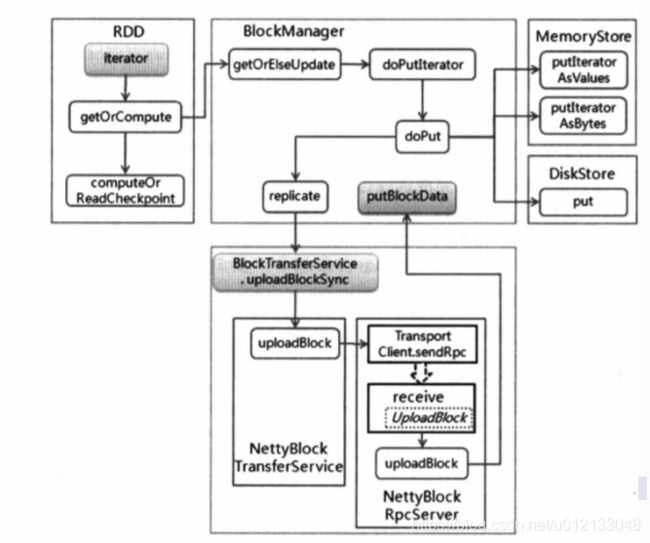
- blockManager中的doPutIterator方法是写数据的入口
- 根据存储级别,通过putInterator方法直接存储到磁盘或者内存。
- 如果存储到内存,需要先判断是否需要序列化,如果设置了序列化则通过putInteratorAsBytes方法实现,如果不需要序列化则通过putInteratorAsValues。
- 写入内存时,需要判断内存大小是否足够,如果足够则直接写入,否则把数据写入到磁盘。
- 写入数据完成后,一方面把数据块元信息发送给Driver端,另一方面判断是否需要创建数据副本,将数据写到远程节点上。
类调用图:
spark内存结构图:
RDD内存写入过程:
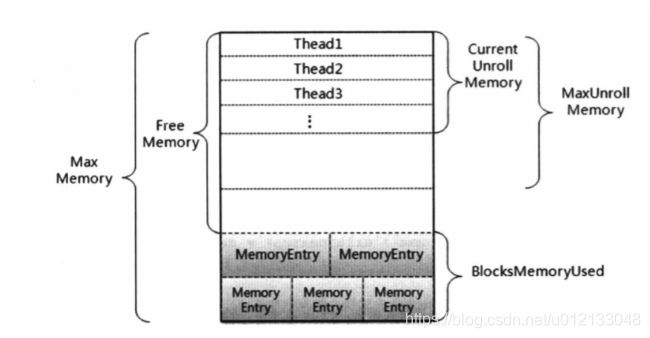
内存写入:
下半部分为已用内存,在这些内存中存放entries,该entries由不同的数据块生成的MemoryEntry构成。上半部分为可用内存。
- 在写入内存时,先会对可用内存进行展开数据块,展开的意思并不是直接存储数据块,而是在内存中占用位置,步步为营,在每一步中都会先检查内存大小是否足够。
- 如果内存大小不足,则尝试把内存中的数据写入到磁盘中,然后释放空来来存放新写入的数据。
- 数据参数是以linkedHashMap保存,是有序的,释放空间时以FIFO的原则进行,当释放空间足够时,返回内存足够的结果。
- 当释放所有空间后,空间还是不足(属于同一个RDD中的数据块不能被释放),返回内存不足的结果。
- 当展开成功时,需要把这些数据写入内存中。
在内存处理类MemroyStore中,有两种不同的写入方式,分别为:
- putIteratorAsValues作为值类型直接写入,没有序列化。
- putIteratorAsBytes作为字节码数据写入,经过序列化。
写入磁盘:
spark写入磁盘调用的是DiskStore的put方法。,将数据序列化成数据流后写入。
3 shuffle 存储过程
在hadoop中,shuffle是Map和Reduce之间桥梁,由于shuffle涉及到磁盘读写和网络传输,因此Shuffle的性能高低直接影响了整个程序性能。
在MapReduce的过程中,需要各个节点上的同一类数据汇集到一个节点进行计算,这个汇集的过程称为shuffle。
在spark的shuffle过程中存在以下问题:
- 数据量非常大,达到TB深圳PB级别,在数百甚至数千集群中运行,如何关于任务中创建的众多文件,以及处理大小超过内存的数据量。
- 进行序列化和反序列化时,如何在传输前进行压缩处理。
3.1 shuffle的写操作
在spark1.6之前采用hash的shuffle写操作,但是由于创建的临时文件数量过多,缓存开销过大的问题,放弃了。hash方法的问题:
- MapTask会根据Reduce的个数,创建相应的bucket,后续每个Reduce可以根据编号去相应的bucket中获取数据,这就意味着。如果有S个Map,F个Reduce,那总文件就位S*F,1000个Map,1000个reduce,文件数为1M,这对IO是非常大的负担,严重影响性能。
- 当Map数为1000,Reduce数为1000时,每个文件读写如果需要100kb的内存,那系统开销就是100GB的内存。这对内存的开销也非常巨大。

当前shuffle采用的是基于排序的Shuffle写操作。
- 在当前机制中,每个Map不会为每个Reduce创建一个文件,而是会将所有的结果写到同一个文件中,对应生成一个index文件进行索引,也就是说reduce通过这个索引文件获取对应的数据。
- 当前机制中,将Aggregator的操作从内存转移到磁盘中,在reduce结束时,再将不同的文件进行归并排序,从而减少内存使用量。
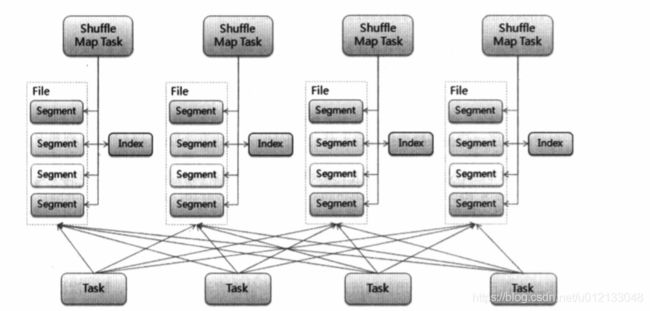
具体的写过程(需要再验证和查阅资料,看了半天总是不够清晰):
- 先判断在MapTask的输出结果在Map端是否需要合并(Combine)。
- 如果需要合并,则外部排序中进行聚合并排序,如果不需要则外部排序中不进行聚合。
例如sortByKey操作在reduce端会进行聚合排序。当确认外部排序方式后,将使用PartitionAppendOnlyMap来存放数据,当排序中的Map占用的内存已经超越了使用的阈值,则将Map中的内容溢写到磁盘中。
从上述过程可以看到:
- shuffle的外部排序过程过程中的中间数据,先存储到内存数据。
- 当内存不够时,溢出存储到磁盘,每一次溢出产生一个不同的文件。
- 当所有数据处理完毕后,在外部排序中可能有一部分计算结果在内存中,另一部分计算结果溢出写到一个或者多个文件中,这时通过merge操作将内存和spill文件中的内容合并整到一个文件里。
所以这里总结一下:在spark中:
- Map端的数据直接存储在磁盘中,创建一个存储文件和索引文件。
- reduce的外部排序数据会先写到内存,当内存不足时会溢写到磁盘。
3.2 Shuffle的读操作
shuffle读数据的场景是在下游stage执行时,需要读取上游stage的数据,而在读取前需要解决两个问题:
- 排序shuffle,读取方式如何。
- 如何确认上游任务读取数据的位置信息,位置信息包括所在节点,Executor编号和读取数据块序列。
具体过程如下:
- 在Worker中启动时,实例化IndexShuffleBlockResolver(因为排序方式,创建了一个存储文件和索引文件)。
- 在Executor发送消息给Driver,获取上游shuffle输出结果对应的MapStatus,该MapStatus存放了数据的位置信息,这个信息也就是写入时ShuffleMapTask执行结果的元信息。
- 知道Shuffle结果的位置后,判断是否为本地节点,如果为本地节点,则直接调用getBlockData方法,如果在远程节点则通过Netty网络方式读取。远程读取使用短线呈的方式,一般会启动5个线程到5个节点进去读取,每个请求的数据大小不会超过系统设置的1/5,默认系统设置为48MB。
- 读取数据后,判断ShuffleDependency是否定义聚合(Aggregation),如果需要则根据键值进行聚合。需要注意的是,如果在ShuffleMapTask已经做了合并,则在合并数据的基础上再做聚合,聚合完毕后,使用外部排序对数据进行排序并放入存储中,至此完成读取操作。
4 序列化和压缩
4.1 序列化
Spark内中了两种序列化方式:JavaSeralizer和KryoSerializer,这两个继承于抽象类Serializer,而在SparkSql中SparkSqlSerializer继承于KryoSerializer。
默认,Spark使用JavaSeralizer,虽然灵活,但是性能不佳,生成的结果集也比较大。
也可以用KryoSerializer,性能更好,压缩率更高。不过KryoSerializer并不支持所有的对象(具体支持哪些),而且要求用户注册类。
4.2 压缩(具体展开还需要查阅资料)
spark提供了三种压缩方法,分别为:LZ4、LZF和snappy,三者的特性为:
1)Snappy提供了更高的压缩速度;
2)LZF提供了更高的压缩比;
3)LZ4提供了压缩速度和压缩比俱佳的性能
5 共享变量(细节需要查阅资料)
5.1 广播变量
广播变量运行在每个节点缓存只读的变量,而不是在任务之间传递这些变量。广播变量能够高效的在集群每个节点创建大数据集的副本。同时,spark还用高效的广播算法分发这些变量(什么广播算法),从而减少通信的开销。
spark的任务由一些列stage构成,这些stage通过shuffle进行分隔。Spark能在每个stage阶段自动广播任务所需要的数据,这些数据在广播时,需要进行序列化缓存,并在任务运行钱需进行反序列化。这就意味着当多个调度阶段的任务需要相同的数据,显示地创建广播变量才有用,广播变量只读不能被需改。