基于Keras的DCGAN实现
基于Keras的DCGAN实现
说明:所有图片均来自网络,如有侵权请私信我删
参考资料
- 基于Keras的DCGAN实现的外文博客:GAN by Example using Keras on Tensorflow Backend
- GitHub上关于GAN网络实现技巧文章:How to Train a GAN? Tips and tricks to make GANs work
- 提出DCGAN网络的科技论文:Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks
DCGAN简介
Wikipedia定义
生成对抗网络(Generative Adversarial Network,简称GAN)是非监督式学习的一种方法,通过让两个神经网络相互博弈的方式进行学习。
生成对抗网络由一个生成网络与一个判别网络组成。生成网络从潜在空间(latent space)中随机采样作为输入,其输出结果需要尽量模仿训练集中的真实样本。判别网络的输入则为真实样本或生成网络的输出,其目的是将生成网络的输出从真实样本中尽可能分辨出来。而生成网络则要尽可能地欺骗判别网络。两个网络相互对抗、不断调整参数,最终目的是使判别网络无法判断生成网络的输出结果是否真实。
通俗解释
这里使用警察和假币制造者的例子进行说明:判别网络就是警察,生成网络就是假币制造者。假币制造者通过随意购买的材料制造伪钞,然后交给警察判别真假,警察将真假货币特征告诉假币制造者,假币制造者改良制造工艺,如此一直循环下去,直到有一天,假币制造者将自己的伪钞给警察的时候,竟然骗过了警察的火眼金睛,达到了以假乱真的程度。
这就是对抗生成网络,Adversarial说明了该网络的方式是通过两个网络的对抗来完成任务的,Generative说明了该网络是用来生成一些不存在的东西的,比如图片,比如诗歌等等。
实现细节
实现代码GitHub地址:https://github.com/theonegis/keras-examples.git
首先,来看一张图,这张图就是GAN的原理图,也是我们实现的指导思想。
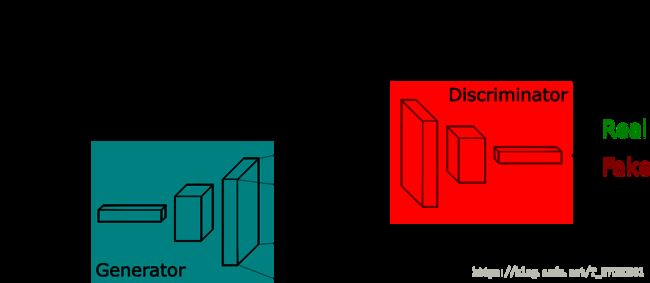
所以,代码的核心是实现两个网络,以及训练过程。
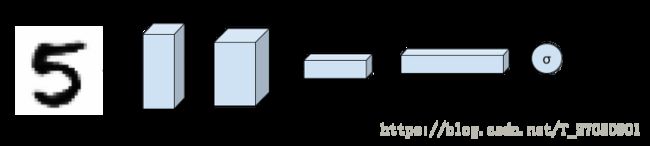
判别网络
判别网络的架构如下:我们的输入是一个 28×28×1 28 × 28 × 1 的一张图片,中间经过四个卷积层变成 4×4×512 4 × 4 × 512 的一个张量(tensor),然后我们使用一个Flatten和一个Dense层,最后的激活函数选择sigmoid,输出判别概率。
判别网络中其它的激活层使用LeakyReLu函数,并添加Dropput层。
def discriminator_model(self):
# 28*28*1-->14*14*64-->7*7*128-->4*4*256-->4*4*512
dropout = 0.4
model = Sequential()
model.add(Conv2D(64, kernel_size=3, strides=2, padding="same",
input_shape=self.img_shape))
model.add(LeakyReLU(alpha=0.2))
model.add(Dropout(dropout))
model.add(Conv2D(128, kernel_size=3, strides=2, padding="same"))
model.add(LeakyReLU(alpha=0.2))
model.add(Dropout(dropout))
model.add(Conv2D(256, kernel_size=3, strides=2, padding="same"))
model.add(LeakyReLU(alpha=0.2))
model.add(Dropout(dropout))
model.add(Conv2D(512, kernel_size=3, strides=1, padding="same"))
model.add(LeakyReLU(alpha=0.2))
model.add(Dropout(dropout))
model.add(Flatten())
model.add(Dense(1))
model.add(Activation('sigmoid'))
model.summary()
image = Input(shape=self.img_shape)
validity = model(image)
return Model(image, validity)`生成网络
生成网络的架构如下:我们的输入是一个100维的向量(vector),经过Dense和Reshape变换为 7×7×256 7 × 7 × 256 大小的张量,然后经过四个逆卷积(转置卷积)得到最后的输出( 28×28×1 28 × 28 × 1 )。整个过程没有使用全连接,使用转置卷积直接替换上采样和卷积层(某些资料说能达到更好的效果)。
激活层之前都使用了BatchNormalization,激活函数除了最后输出层采用tanh,其它都采用relu。

def generator_model(self):
# 100-->7*7*256-->14*14*128-->28*28*64-->28*28*32-->28*28*1
model = Sequential()
model.add(Dense(256 * 7 * 7, input_shape=(self.latent_dim,)))
model.add(BatchNormalization(momentum=0.9))
model.add(Activation('relu'))
model.add(Reshape((7, 7, 256)))
model.add(Conv2DTranspose(128, kernel_size=3, strides=2, padding='same'))
model.add(BatchNormalization(momentum=0.9))
model.add(Activation('relu'))
model.add(Conv2DTranspose(64, kernel_size=3, strides=2, padding='same'))
model.add(BatchNormalization(momentum=0.9))
model.add(Activation('relu'))
model.add(Conv2DTranspose(32, kernel_size=3, padding='same'))
model.add(BatchNormalization(momentum=0.9))
model.add(Activation('relu'))
model.add(Conv2DTranspose(self.channels, kernel_size=3, padding='same'))
model.add(Activation('tanh'))
model.summary()
noise = Input(shape=(self.latent_dim,))
image = model(noise)
return Model(noise, image)对抗生成网络
对抗生成网络就是把生成网络和判别网络组合在一起,架构如下:
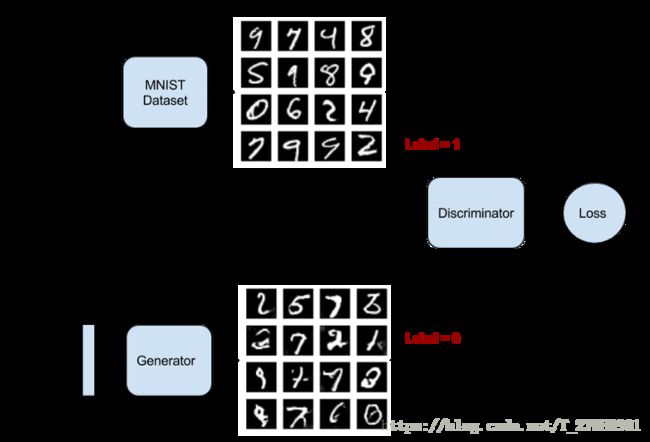
注意在Adversarial网络中,Discriminative网络不参与训练,只参与判别,就是说Discriminative网络的权重值不发生变换。
class DCGAN():
def __init__(self):
# Input shape
self.img_rows = 28
self.img_cols = 28
self.channels = 1
self.img_shape = (self.img_rows, self.img_cols, self.channels)
self.latent_dim = 100
optimizer = Adam(lr=0.0002, beta_1=0.5, decay=1e-8)
# Build and compile the discriminator
self.discriminator = self.discriminator_model()
self.discriminator.compile(loss='binary_crossentropy',
optimizer=optimizer,
metrics=['accuracy'])
# Build the generator
self.generator = self.generator_model()
# The generator takes noise as input and generates images
noise = Input(shape=(self.latent_dim,))
images = self.generator(noise)
# For the combined model we will only train the generator
self.discriminator.trainable = False
# The discriminator takes generated images as input and determines validity
validity = self.discriminator(images)
# The adversarial model (stacked generator and discriminator)
self.adversarial = Model(noise, validity)
self.adversarial.compile(loss='binary_crossentropy',
optimizer=optimizer,
metrics=['accuracy'])训练过程
在训练过程中,我们首先加载MNIST数据集,然后将其归一化到[-1, 1]区间。
首先,训练判别网络,这里的实现是一个epoch中给定一半的伪造图片,一半的真实图片。
然后,训练生成网络。
对于生成网络的输入,我们采用[-1, 1]区间的正态分布的随机数据。此外,我们这里的真假标签没有直接使用1和0,而是对于真实图片使用[0.7, 1.2]区间的随机值,对于伪造图片使用[0.0, 0.3]区间的随机值。
def train(self, epochs, batch_size=256, save_interval=100):
# Load the dataset
(x_train, _), (_, _) = mnist.load_data()
# Rescale to [-1, 1]
x_train = (x_train.astype(np.float32) - 127.5) / 127.5
x_train = np.expand_dims(x_train, axis=3)
for epoch in range(epochs):
# ---------------------
# Train Discriminator
# ---------------------
half_batch = int(batch_size / 2)
# Select a random half batch of images
idx = np.random.randint(0, x_train.shape[0], half_batch)
real_img = x_train[idx]
# Sample noise and generate a half batch of new images
noise = truncnorm.rvs(-1, 1, size=(half_batch, self.latent_dim))
fake_img = self.generator.predict(noise)
# Train the discriminator (real classified as ones and generated as zeros)
x = np.concatenate((real_img, fake_img))
real_label = truncnorm.rvs(0.7, 1.2, size=(half_batch, 1))
fake_label = truncnorm.rvs(0.0, 0.3, size=(half_batch, 1))
y = np.concatenate((real_label, fake_label))
d_loss = self.discriminator.train_on_batch(x, y)
# ---------------------
# Train Generator
# ---------------------
# Sample generator input
noise = truncnorm.rvs(-1, 1, size=(batch_size, self.latent_dim))
# Train the generator (wants discriminator to mistake images as real)
real_label = truncnorm.rvs(0.7, 1.2, size=(batch_size, 1))
a_loss = self.adversarial.train_on_batch(noise, real_label)
# Plot the progress
print('{} [D loss: {:.5f}, acc: {:.3f}] [A loss: {:.5f}, acc: {:.3f}]'.
format(epoch, d_loss[0], d_loss[1], a_loss[0], a_loss[1]))
# If at save interval => save generated image samples
if (epoch + 1) % save_interval == 0:
self.save_result(epoch)
self.generator.save('generator_{}.h5'.format(epoch))
self.discriminator.save('discriminator_{}.h5'.format(epoch))
def save_result(self, epoch):
rows, cols = 5, 5
noise = truncnorm.rvs(-1, 1, size=(rows * cols, self.latent_dim))
images = self.generator.predict(noise)
fig, axs = plt.subplots(rows, cols)
cnt = 0
for i in range(rows):
for j in range(cols):
axs[i, j].imshow(images[cnt, :, :, 0], cmap='gray')
axs[i, j].axis('off')
cnt += 1
fig.savefig("mnist-{0:0>5}.png".format(epoch + 1), dpi=300)
plt.close()最后的结果如下:

存在问题
- 我训练过程中的日志输出中的Accuracy一直是0,不知道什么回事?
- 最后模型收敛以后,感觉 5×5 5 × 5 的图片中,也不是每张的效果都很好。