文献阅读-ICRA2020-从单眼内窥镜图像中对手术机器人器械的柄姿势估计
文章序号、所属单元及链接:1630-Computer Vision for Medical Robots
一作所属单位:University of Tokyo
读后体会:以我浅薄的学术认知来看这篇论文最大的创新点在于使用CG数据进行数据扩充,其他好像没什么特别有价值的。
从单眼内窥镜图像中对手术机器人器械的柄姿势估计
- Abstract
- Introducton
- A.相关工作
- B.当前方法的局限性
- C.贡献说明
- Problem Statement
- Methods
- A.训练数据集
- B.其他训练方法
- C.网络架构
- Evaluation
- Conclusion
Abstract
手术机器人用于执行微创手术,减轻了外科医生的许多负担。我们的小组开发了一种外科手术机器人,可通过鼻孔进入颅骨底部,以帮助去除肿瘤。为了避免伤害患者,使用了避免碰撞算法,该算法依赖于针对器械柄的姿势具有准确的估计模型。由于器械的参数和其他干扰因素之间的相互作用,模型的参数可能会随时间变化,因此,在线估算器械轴的姿势至关重要。在这项工作中,我们提出了一种使用单眼内窥镜估计手术器械杆身姿势的新方法。我们的方法基于使用自动注释的训练数据集和改进的姿势估计深度学习结构。在初步实验中,我们证明了通过人工图片仿真,我们的方法可以超越基于视觉的无标记姿势估计技术(提供的位置估计误差减少了55%,俯仰(pitch)误差减少了64%,偏航(yaw)误差减少了69%)。
Introducton
与手动手术相比,机器人辅助手术具有许多优势。在机器人辅助手术中,外科医生的手震会被过滤掉,从而可以更精确地移动机器人器械。此外,外科医生可以有效地对尖端具有多个自由度的机器人器械进行灵巧的操纵,而手持式外科器械的灵巧性有限。考虑到这些优点,我们正在开发一种名为SmartArm 的多功能机器人,其设计重点是在深度和狭窄的空间中进行操作。
SmartArm的应用之一是鼻内手术,其中经蝶窦(transsphenoidal)手术是目标之一。经蝶骨手术是去除脑垂体肿瘤或颅底其他肿瘤的过程,如图1所示。在受约束的工作空间(例如鼻腔)中由机器人进行的辅助手术中,外科医生将视力限制在手术器械尖端附近的区域。为了自主地防止机器人与周围组织之间的碰撞,我们已经基于机器人的运动学模型开发了一种虚拟夹具框架。
但是,即使对机器人的参数进行了仔细的离线校准,并且在相当可控的环境中,我们仍然可以观察到运动学模型与机器人末端绝对姿态之间的几毫米误差。此外,即使可以对机器人进行完美的离线校准,温度变化以及工具与组织之间的相互作用等干扰也会导致机器人的参数随时间变化。如使用da Vinci Surgical System的相关文献所报道的那样,在线驱动的机器人中,计算出的姿势与机器人器械的绝对姿势之间的不匹配更加明显。这是常规用于体内手术的机器人系统。对于远程操作的用
户来说,这种不匹配并不明显的原因是,操作员通过使用他们的视野来“闭环”。当我们朝手术任务的(半)自动化发展时,“闭环”并提供工具参数在线校准的系统至关重要。此外,考虑到避免碰撞的有效性很大程度上取决于机器人模型的准确性,实现高度精确的参数校准非常重要。
A.相关工作
已经提出了许多策略来估计手术器械的姿势。有些需要增加传感器,例如超声波或电磁跟踪器。这样的要求使得很难在临床得以落地,并且传感器本身具有应考虑的限制。例如,超声波的传播受到其介质的影响,而电磁传感器则受到周围的金属材料和磁场的影响。
另一种方法是使用立体声相机。艾伦(Allan)等人使用语义过滤后的粒子过滤器和光流从立体腹腔镜的视差中计算出手术器械的姿势。Baek等基于将2D图像与3D模板相关联的其他方法,使用粒子过滤和运动学数据来跟踪显微外科机器人系统
的器械。Moccia等使用特征匹配和扩展的卡尔曼滤波器来估计和跟踪达芬奇器械的姿态。然而,鼻内窥镜手术需要微小的(3mm)内窥镜,这在市场上目前尚不可用。Gadwe等人提出了可印刷标记,但这还需要修改手术器械。
基于以上所述,我们旨在通过单眼内窥镜估计器械的姿势。大量的论文探索了从单眼图像中估计器械姿势的方法。例如,Reiter等使用关键点信息估算了达芬奇器械的姿势。Ye等研究了关键点提取和基于零件的模板匹配,即使在被遮挡的情况下,也可以估计工具的姿态。Zhou和Payandeh 从图像上轮廓线的垂直位置和尖端估计了姿势。其他研究团队使用分段和模板匹配方法加上对象跟踪,通过两步法提出了估计方法。在这类器械姿态估计中,报告的位置误差大于2.8mm,旋转误差大于4.8°。从单眼图像准确估计手术器械的姿势仍然是一项艰巨的任务。
深度学习技术正在迅速发展,并且在过去几年中已经研究了通过端到端学习和推理从单眼图像中估计物体的姿态。例如,Sundermeyer等使用训练数据集(由从3D模拟对象渲染的人工图像组成),根据单眼图像估计了真实对象的姿态。在他们的方法中,首先使用单发检测(SSD)来检测对象。然后,使用经过人工图像训练的自动编码器估算姿势。在另一项工作中,Kehl等人提出了SSD-6D方法,其中直接将对象的姿态与图像上的对象边界框一起估计为SSD的输出。据我们所知,这些方法尚未应用于手术工具的姿态估计。
B.当前方法的局限性
在初步评估中,我们尝试直接使用SSD-6D方法来估计机器人设置中手术器械柄的位置。我们确定了本工作中要解决的当前方法的两个局限性:
(1)在SSD-6D中,通过离散化姿势空间将姿势估计视为分类问题。例如,旋转以五度步长分类,这对于手术器械的姿势估计而言不够精确。
(2)假定物体离摄像机很远,因此图像几乎不受透视失真的影响。对于鼻内窥镜图像来说,这种假设不成立,因为仪器离镜头和内窥镜很近,通常具有宽广的视角。由于透视变形,这会导致对象的形状在内窥镜图像中变形(对象的较近部分看起来比同一对象的较远部分大)
C.贡献说明
考虑到先前的文献,我们在这项工作中的目标是使用端到端深度学习从单眼内窥镜图像估计手术器械的姿势。我们的用例打破了先前方法的某些假设,因为由于透视畸变,仪器的外观会根据距内窥镜的距离而变化。此外,在内窥镜图像上只能看到器械的尖端。为了克服这些问题,我们提出了一种新的深度学习架构。它是SSD-6D的改进架构,它执行回归而不是分类。该网络还可以很好地响应遮挡和各种器械。训练数据的生成还部分依赖于使用计算机图形(CG)渲染软件进行的人工数据扩充。我们的结果表明,我们可以从真实的内窥镜图像中准确估计手术器械的姿势。据我们所知,我们方法的准确性是外科器械基于视觉和无标记姿势估计的最新技术。
Problem Statement
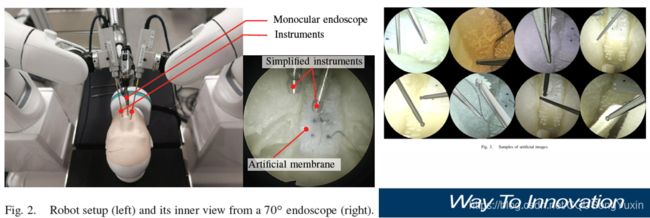
给定机器人辅助的鼻腔外科手术设置,如图2所示,让两个机械臂(SmartArm )的器械作为末端执行器。这些器械通过解剖学上逼真的头部模型(BionicBrain)的鼻孔插入。图像是通过高清内窥镜系统(Endoarm,奥林巴斯,日本)和70度内窥镜(视角为95度)获得的。对于这项工作,假设我们只对找到器械柄的姿势感兴趣,因为该信息足以在鼻内外科手术中适当避免碰撞。器械的参考坐标系固定在其远端,z轴沿仪器的轴。在这种情况下,我们的目标是估计器械的轴相对于单眼内窥镜的姿势。在未来的工作中,我们的愿景将是将此信息反馈给机器人控制器,以适应机器人参数,以提高机器人辅助程序的安全性和准确性。
Methods
本文提出了一种从单眼内窥镜图像估计手术器械杆身姿势的新方法。在本节中,我们首先描述如何创建由人工CG图像组成的训练数据集。其次,我们解释我们提出的用于姿势估计的网络体系结构。最后,我们解释了数据扩充方法和损失函数。
A.训练数据集
众所周知,深度卷积神经网络(DCNN)需要大量的训练数据才能避免过拟合,而手动标注是一项耗时且容易出错的任务。在多任务学习中,甚至需要更复杂的注释。例如,在SSD-6D和这项工作中,语义注释,边界框和轴的精确姿势是必需的。为了解决这个问题,我们使用基于的渲染模型,使用开源渲染软件(Blender,Blender Foundation,荷兰)部分依赖CG图像的自动注释。创建了100000张图像。
B.其他训练方法
我们在数据集中添加了一些真实的内窥镜图像及其边界框的手动注释。目前,尚未将姿势信息添加到实际图像中。我们小组正在不断进行研究,以创建这样一个真实的数据集。
C.网络架构
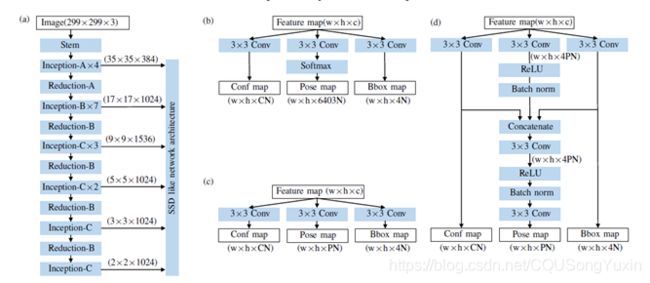
1)主网络:我们的网络可以看作是SSD-6D网络的扩展。我们使用通过扩展InceptionV4 作为SSD 的骨干而创建的网络。更改了“ Inception-B”的填充
以获取奇数大小的特征图。
2) 检测和姿态估计网络:在这项工作中,我们探索了用于器械检测和姿态估计的两种体系结构。第一种架构是对SSD-6D 网络的调整,以执行回归,如图4(b)所示。另一种架构是更复杂的网络,它将类置信度预测输出和边界框预测输出馈送到姿态估计路径,以提高姿态估计的质量,如图4(c)所示。
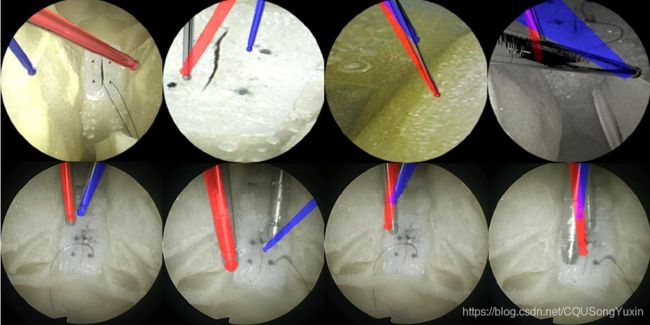
Evaluation
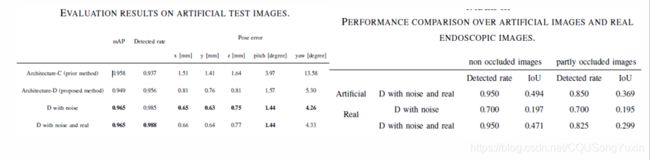
进行了两个实验以评估我们的方法。在第一个实验中,在人工图像上评估了姿态估计的质量。在第二个实验中,我们在真实的内窥镜图像上评估了网络。所有架构都使用相同的参数。九万张人造图像用作训练数据,另外10000张图像用作测试数据。Batchsize=32,所有架构均使用TensorFlow 1.13和cuDNN 7.4在Python 3.6中实现,Ubuntu 18.04中使用QuadroGV 100图形卡。
Conclusion
在本文中,我们提出了一种深度学习方法来估计单眼内窥镜图像中手术器械的杆身姿势。为此,我们扩展了SSD-6D 网络。我们还创建了一个由人工渲染的图像组成的数据集,并自动标注了仪器的边界框和姿势。
在我们的研究背景下,通过使用人工图像的实验,我们提出的架构可以大大降低姿态估计误差(位置估计的55%,俯仰的64%和偏航的69%)。此外,在使用真实图像的初步实验中,我们表明网络可以在一定程度上从真实图像进行泛化。必须做进一步的工作来改善我们的训练数据集并添加带有姿势注释的真实图像。
这是我们实现器械轴在线校准目标的重要第一步,目的是在受限工作空间中可靠地避免机器人辅助手术过程中的碰撞。只要器械的轴很突出,我们的方法就应该适用于其他器械估计。在未来的工作中,我们打算利用顺序视频信息来提高我们预测的稳健性。