DeepLab系列学习笔记
目录 DeepLabV1
- 预备知识
- paper笔记
DeepLabV2
- paper与参考
- paper笔记
DeepLabV3
- paper与参考
- paper笔记
DeepLabV4
- paper与参考
- paper笔记
正文 DeepLabV1
一、预备知识
- SEMANTIC IMAGE SEGMENTATION WITH DEEP CONVOLUTIONAL NETS AND FULLY CONNECTED CRFS
- 空洞卷积(dilated convolution)理解
- 条件随机场
- 一篇解读博客<详细>
- Deep Learning:DeepLab<网络结构详解>
但最后Multi-Scale Prediction的结构,我大概是没理解清楚。二、paper笔记
论文首先指出DCNNs具有空间不变性, 这样的特性十分有利于分类这种高层次的抽象决策任务(比如一张图片里边不管人在什么位置, 最后都能正确预测为人).但是对于分割或检测任务来说, DCNNs它只能够预测目标出大概的位置,不能预测出很精细的边缘细节.为什么呢?因为DCNNs中多采用卷积和max pooling的组合来提取特征以及下采样,最后得到很高级很抽象的语义特征,特别适用于分类任务.但是在这不断的下采样过程中,必然会损失掉很多空间信息,所以最后得到的小分辨率feature maps对于小目标来说,是不容检测出来的,尤其是边缘细节.
那么作者怎么做呢?针对分辨率小这个问题,在卷积过程中就可以减少下采样的倍数(实际论文中是将pool4和pool5的stride改为1,也就是得到8x下采样feature maps之后就不下采样了,此时相当于8个输入像素计算一个特征响应),从而获得更加稠密(分辨率高)的feature maps,相当于是在高层语义特征和高分辨率之间的一个权衡折中.但是又会有问题,不做下采样的话,就会失去原先网络的大感受野(感受野会变小).怎么办?deeplabv1从小波变换将空洞算法引入卷积网络中,空洞卷积核可以扩大卷积核的感受野.总的来说,pool4(stride=1)之后,conv5采用dialate conv(input stride或rate=2)来弥补;pool5(stride=1)之后,跟着fc6,fc7,fc8,softmax.而作者在fc6采用几种kernel size核input stride的组合来做对比实验,得到的结论是,fc6采用1024x3x3,rate=12的卷积核来全卷积连接,得到最佳表现(与fc6为4096x7x7精度相等,但更快更轻量).
更加稠密的feature maps,意味着更多的计算量,使用空洞卷积核,一方面可以使小卷积核获得大卷积核的大感受野,另一方面,小卷积核计算更高效。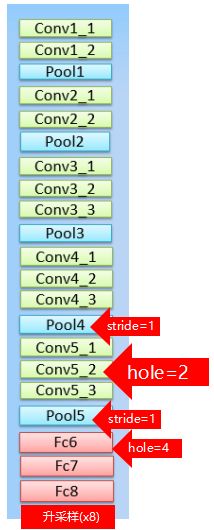
前面是在空洞卷积做文章,其实本文的亮点还有两个,一个是针对多尺度目标的检测问题,当下有多数先进方法是在多尺度卷积特征的整合上进一步处理的,论文作者也采用了多尺度卷积特征整合的方式,但是效果其实不明显,只有1个百分点左右的提升.大概做法是,将前4个max pool的输出经过1个128x3x3和1个128x1x1的卷积核来提取特征,并整合(concate)到pool5的输出,最终输入fc层和softmax层得到8x下采样的预测结果(训练时将gt下采样8x了),然后再将预测结果8x双线性插值上采样得到和输入尺寸一致的分割结果.
另外一个亮点是,本文提出全连接的CRFs算法,来后处理分割结果,以得到更加精细的边缘细节.这里CRFs的提升比较明显.但这样会使得模型比较冗赘,不能够end-2-end地训练和推理,在deeplabv3之后就取消了CRFs,并且效果还更好(所以暂时先不学习这个CRFs了).
感受野的计算
net_struct = {'alexnet': {'net':[[11,4,0],[3,2,0],[5,1,2],[3,2,0],[3,1,1],[3,1,1],[3,1,1],[3,2,0]],
'name':['conv1','pool1','conv2','pool2','conv3','conv4','conv5','pool5']},
'vgg16': {'net':[[3,1,1],[3,1,1],[2,2,0],[3,1,1],[3,1,1],[2,2,0],[3,1,1],[3,1,1],[3,1,1],
[2,2,0],[3,1,1],[3,1,1],[3,1,1],[2,2,0],[3,1,1],[3,1,1],[3,1,1],[2,2,0]],
'name':['conv1_1','conv1_2','pool1','conv2_1','conv2_2','pool2','conv3_1','conv3_2',
'conv3_3', 'pool3','conv4_1','conv4_2','conv4_3','pool4','conv5_1','conv5_2','conv5_3','pool5']},
'zf-5':{'net': [[7,2,3],[3,2,1],[5,2,2],[3,2,1],[3,1,1],[3,1,1],[3,1,1]],
'name': ['conv1','pool1','conv2','pool2','conv3','conv4','conv5']}}
imsize = 224
def outFromIn(isz, net, layernum):
totstride = 1
insize = isz
for layer in range(layernum):
fsize, stride, pad = net[layer]
outsize = (insize - fsize + 2*pad) / stride + 1
insize = outsize
totstride = totstride * stride
return outsize, totstride
def inFromOut(net, layernum):
RF = 1
for layer in reversed(range(layernum)):
fsize, stride, pad = net[layer]
RF = ((RF -1)* stride) + fsize
return RF
if __name__ == '__main__':
print ("layer output sizes given image = %dx%d" % (imsize, imsize))
for net in net_struct.keys():
print ('************net structrue name is %s**************'% net)
for i in range(len(net_struct[net]['net'])):
p = outFromIn(imsize,net_struct[net]['net'], i+1)
rf = inFromOut(net_struct[net]['net'], i+1)
print ("Layer Name = %s, Output size = %3d, Stride = % 3d, RF size = %3d" % (net_struct[net]['name'][i], p[0], p[1], rf))
DeepLabV2
一、Paper与参考
Semantic Image Segmentation with Deep ConvNets, Atrous Conolution, and Fully Connected CRFs
DeepLab-LargeFOV与DeepLab-ASPP(V2版的ASPP),结构对比如图Fig.7.
图像分割 DeepLab v2
二、Paper笔记
首先,V2除了提出ASPP模块和采用ResNet101做backbone以外,其他就是V1的详细补充了(空洞卷积和CRFs并没有实质性的改动).所以这里补充一些V1的遗留问题和V2的创新点.
空洞卷积就是在常规卷积核里边按给定的input stride(rate)填充0,从而增大了卷积核的有效视野(FOV).这样的机制可以抵消掉max pool不下采样(stride=1)带来的感受野减小的问题.另外,在DCNNs中减少了两次下采样,输出的feature maps尺寸相对于输入图像是下采样了8x,即得到了更加稠密(分辨率更高)同时又具备足够高级语义的feature输出,这有利于小目标和目标边缘细节的精细分割.这样做不仅考虑了目标尺度和边缘,分割精度得到明显的提升,而且,简化了传统DCNNs用于语义分割时冗余且低效的上采样过程.空洞卷积核并没有参数量引入额外的参数,相比传统语义分割的DCNNs少了两次上采样,速度也更快了.总的来说就是真的做到更快更精准.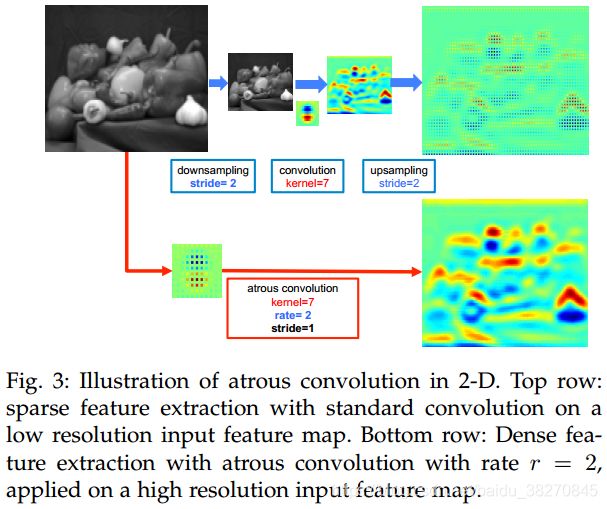
空洞卷积与常规卷积对比 空洞空间金字塔池化(ASPP)灵感来自于SPP检测网络,主要解决目标的多尺度问题.输入的feature maps为pool5的输出.假如要分割的目标在橙色框内,那么显然用大的滤波器来检测是不合适的.而往往我们也不知道使用什么样的滤波器才好,所以作者在这里设计了4种尺度的卷积核来提取目标特征,相比以往fc6层只采用单个尺度的卷积核效果好太多了.在fc层ASPP之后,将各个feature maps进行融合,得到更加有效的特征输出.论文中作者在baseline(deeplab-large-fov,1024x3x3卷积核,rate=12)基础上,分别对比了ASPP-S(rate=(2,4,8,12)),和ASPP-L(rate=(6,12,18,24))在CRFs前后的性能,结论是下图中的组合(ASPP-L)效果最好.值得一提的是,在分割网络中,空洞卷积(膨胀卷积)和ASPP模块经常被采用,可以带来性能提升.
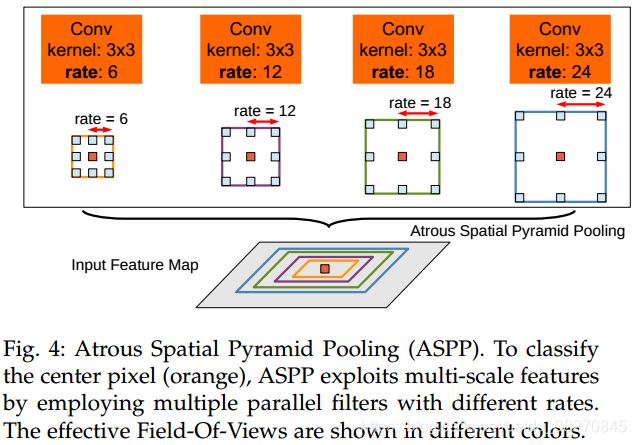
ASPP结构 
DeepLab-LargeFOV与DeepLab-ASPP 使用全连接CRFs结构化预测,恢复分割边缘细节作为一种典型的后处理方式,十分有效.
训练过程采用SGD优化器,学习率的自适应衰减方式由传统的by step策略改进为poly策略, ( 1 − i t e r m a x _ i t e r ) p o w e r (1-\frac{iter}{max\_iter})^{power} (1−max_iteriter)power
从公式可以看出来,就是一种自适应衰减学习率的策略;一开始的时候,学习率最大,每次迭代学习率都会衰减!作者发现这样的策略比每隔一个step衰减一次效果更好.随着迭代次数增多,学习率渐渐减小至0.但是弊端也明显,衰减程度和max_iter有关,假如给定的max_iter不够大,还不足以收敛,那么这个是无法一次性有效训练的.但是对于fine-tune来说,是个不错的策略.
此外,训练时数据增强有采用随机缩放策略(0.5~1的比例之间随机缩放).
VGG16与ResNet101的性能比较总的来说,就是ResNet101的表现要更好于VGG16,不论是分类,分割,还是检测.
推理评估的时候,采用多尺度的输入(0.5,0.75,1),最后整合各输出的预测分数(训练的时候往往会采用多尺度随机缩放增强扩充数据).对于比赛来说,这是提高精度的有效手段,但从工程角度来看,不具备实用性. 消融实验性能表现
消融实验性能表现
DeepLabV3
一、Paper与参考
- Rethinking-Atrous-Convolution-for-Semantic-Image-Segmentation
- Rethinking-Atrous-Convolution-for-Semantic-Image-Segmentation PPT
- DeepLabV3论文解读
二、Paper笔记
介绍 本文在DeepLabV2的基础上,继续探讨多种空洞采样率
(mutiple atrous rate)对目标多尺度上下文信息的作用.本文使用ResNet50和ResNet101作为backbone来提取图像特征,主要采取了级联(串行复制block4)和并行(改进ASPP模块)两种方案来研究atrous convolution对模型性能的影响.此外就是训练和测试的实验细节说明.
下图是目前比较流行的捕获目标多尺度上下文信息的几种方法.在DeepLab系列中,deeplab系列中multi-scale用到了(a)的方法,aspp来自于(d),v3中探讨了级联模型参考了(c),v4中则是结合了(b)编解码器和(d)aspp.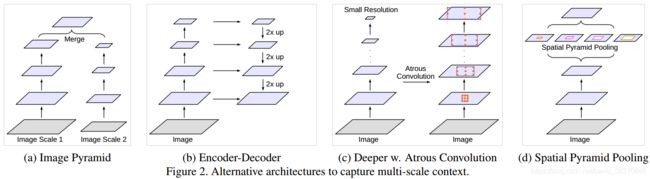
提取目标多尺度上下文信息的几种常见方法 探讨级联模型 v2中只通过并行方式
(ASPP)来探讨了空洞卷积来提取多尺度上下文信息的有效性,那么串联方式是否有效呢?本文将ResNet中block4模块复制3个,并级联在backbone后面,分别对比了在block4~block7中用和不用空洞卷积条件下模型的性能表现.这样做(级联stride=2的模块,搭建更深的网络)的依据是,更深层次的模块使得模型更容易去捕获更大范围的上下文信息(The motivation behind this model is that the introduced striding makes it easy to capture long range information in the deeper blocks).
当不采用空洞卷积时,就只是简单duplicate block4扩展额外的3个模块(Figure 3.(a)).作为对照组(Figure 3.(b)),则是在扩展的block中通过multi-grid策略将空洞卷积引入扩展的级联模块中.每个block中由3个卷积核构成,multi-grid策略就是给其中每个卷积核指定一个unit rate,(eg. multi-grid=(1,2,4), rate_block4=2, 则block4中实际各个卷积核的rates=2*(1,2,4)).当然了,级联模型的末端,也是通过ASPP模块来整合预测seg scores.
带和不带空洞卷积的两种级联模型结构 下表中可以看到,不断的下采样feature maps会使模型分割精度下降(虽然没有对比
without atrous convolution,但可想而知会很差).当output_stride=8时精度最高,但是代价是计算更大的feature map会消耗更多的内存.
不同output_stride下模型的表现 ASPP模块的改进 ASPP中采用多种
atrous rates可以有效地捕获目标的多尺度特征.但本文中作者发现,rate设置越大,卷积核上真正作用在有效特征区域上(而不是作用在padding为0的区域上)的权重数量会越来越少,如下图.在极端的情况下,rate=feature_size的时候,3x3卷积核会退化成1x1卷积核.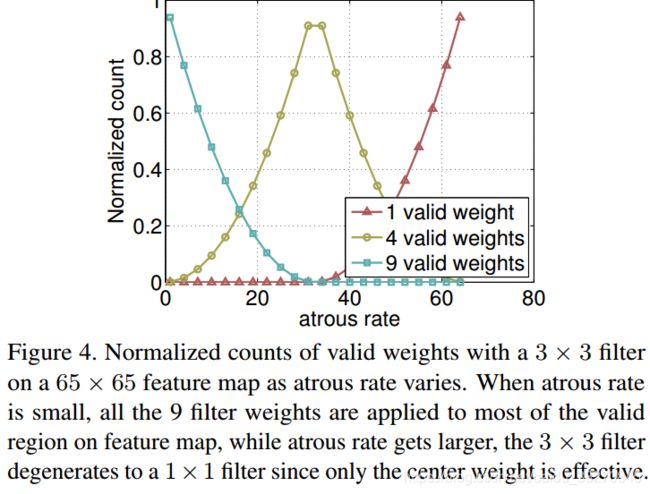
为了克服大的
rate造成卷积核有效权重会退化的问题,以及要在模型中捕获全局上下文信息,作者引入了图像级的特征(image-level features).实际上就是在ASPP中增加了一个并行分支,首先使用1个AdaptiveAvgPool2d池化(2x下采样),然后经过1x1卷积核,BN层和ReLU层.最后再双线性插值上采样至输入AvgPool前的大小.
整体上,ASPP模块由1个1x1卷积核和3个rate分别为6,12,18的3x3卷积核并行构成(每个conv后都跟着BN和ReLU,输出通道均为256).最终,将ASPP各并行分支的输出concat融合,再经过1个1x1卷积核输出256通道,16x下采样的feature maps(最后还经过1个3x3和1个1x1卷积核输出预测结果).实际上下表中简化省略了block4之后的级联模块了.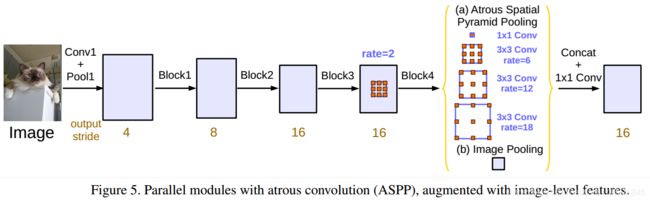
实验结果分析

对比了ResNet50和ResNet101两种不同的backbone,两者均只采用最朴素的空洞卷积方法,output_stride=16.可以看到R50到了block6之后精度开始下降,而R101依旧有提升.此外也可以看到,级联方法确实能够带来显著的提升.
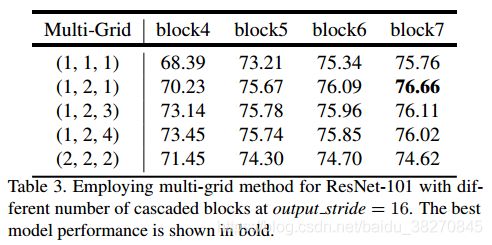
上表格分析了不同Multi-Grid组合的性能.可以看到在级联模型中(后续接未改进的ASPP)采用Multi-Grid=(1,2,1)+block7是最佳参数.纯粹地成比例翻倍没啥作用.

在上述最佳模型的基础上,探讨不同的inference策略的结果.
首先模型训练的时候输出stride为16(训练耗内存小而且更快),而在测试的时候采取输出stride为8效果会更好(这样是既能加快训练过程,又能保证模型预测的精度).此外测试时采用图像金字塔策略以及翻转图像,再将输出整合,也可以提高分割精度(可实际也只有比赛才值得这么做了,这里作为学术探讨).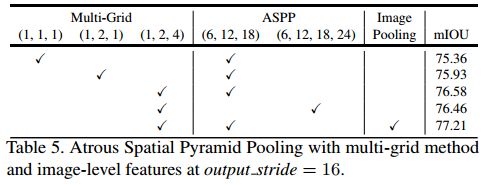
上表分析了,在output_stride为16条件下,不同Multi-Grid和ASPP各项改进(默认都有
1x1卷积核,以及BN和ReLU)的组合对模型的影响.在改进的ASPP模块中,采用Multi-Grid=(1,2,4)是最佳参数.默认并行模块有3个空洞卷积核,增加其数量至4个时,精度下降.引入Image Pooling时能够提升精度.所以最佳组合参数是Multi-Grid=(1,2,4),ASPP=(6,12,18),Image Pooling.
到了这里,我们已经可以得出DeepLabV3的最佳配置了,如上表所示.此外可以看到,当下对于深度模型来说,庞大的数据集才是提升模型性能的有效手段.
DeepLabV4
一、Paper与参考
- Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation
- Xception: Deep Learning with Depthwise Separable Convolutions
- Xception算法详解
- Xception-明月清风
- 『高性能模型』深度可分离卷积和MobileNet_v1
二、Paper笔记
介绍 DeepLabV3可以视为一个Encoder(编码器),负责编码提取图像的高级特征.本文在此基础上,引入Separable Convolution和Decoder Module.前者主要的作用是在保证模型预测精度的同时,大量减少模型计算复杂度,即加速模型预测速度.后者的作用主要是通过解码器一方面可以修正目标分割的边缘细节,另一方面也可以缓冲直接8x或者16x上采样预测结果带来的粗糙边界的问题.此外,Separable Convolution分别应用在backbone和ASPP中.文中也探讨了ResNet101和Xception两种卷积网络,Xception更胜一筹.总之,采用Xception作为backbone,backbone中结合Separable Convolution与Atrous Convolution,ASPP Module中也引入Separable Convolution能够在保证模型精度的同时大量减少模型计算复杂度,起到加速的作用;而Decoder则是将Low-Level Features与Encoder输出的上采样Features整合,修正输出更精细的目标边界信息,使得模型整体精度大幅度提高.
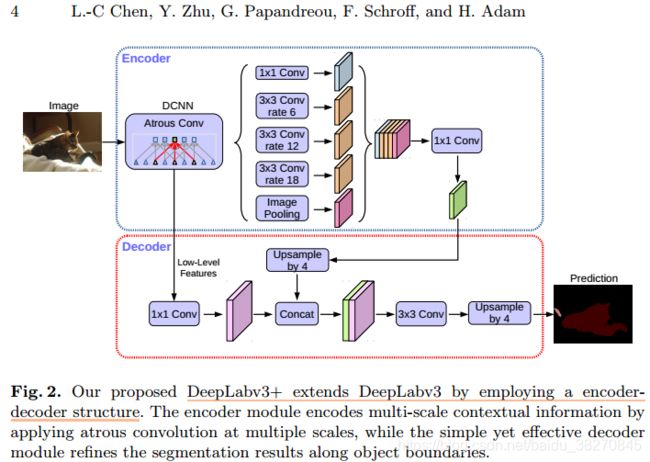
Encoder DeepLabV4中主打经过Atrous Convolution改进的Xception作为backbone,并级联ASPP,以全卷积的深度模型来编码提取图像的高级特征信息.相当于将DeepLabV3当作一个Encoder,对应地,差值上采样可以当作一个弱解码器.
Separable Convolution 关于可分离卷积,出自于MobileNet`中用于轻量化网络起到加速模型的作用.作者认为,卷积网络中,特征层的空间和通道应该区别处理.而在传统卷积方法中,每个卷积核将输入feature maps的空间和通道信息相加整合到一起,输出的通道数与卷积核的个数有关.如下图所示.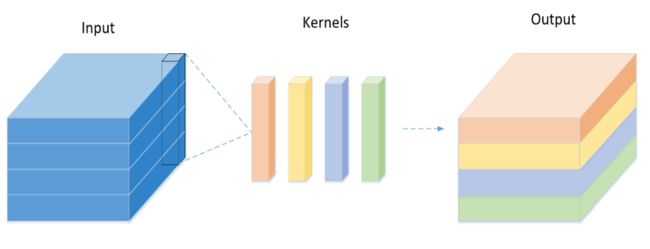
可分离卷积则是通过
Depthwise Conv和Pointwise Conv将空间和通道的处理过程区别开来.对应输入feature maps,每一个通道由一个Depthwise Conv(比如3x3)来滤波,即不将各通道卷积结果相加.由此得到一个和输入通道数一致且各通道的特征之间相互独立的输出feature maps.然后再由Pointwise Conv(1x1)来整合输出最终卷积结果.输出的feature maps在空间和通道上与常规卷积结果相比是一致的,但可分离卷积方法大量减少了模型参数和计算量.值得一提的是,Separable Convolution在MobileNet中目的是加速,而在Xception中,一方面通过Separable Convolution减少参数量和降低计算复杂度,另一方面也在扩展模型的宽度,所以模型的参数量基本与InceptionV3(Xception主要在此网络上改进)是差不多的.因此Xception的设计目的主要还是在模型整体性能上(速度和精度).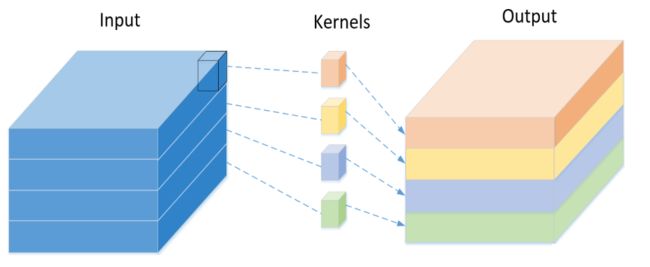
Decoder DeepLabV3中output_stride设为16
(训练过程),也就是说,最后输出的logit scores需要插值上采样16x,才能恢复到输入图像的大小.插值上采样固然可以看作一个解码器,但上采样stride太大,必然无法恢复分割目标的细节.因此本文专门设计一个解码器,一方面,首先将DeepLabV3的输出按较小的倍数(4x)上采样;另一方面,通过1x1卷积核将backbone中的低层特征(具有高分辨率,丰富的空间细节信息)提取出来.然后将上采样特征和低层特征concat起来,并由3x3卷积核来整流输出,最后再4x上采样解码出最终的预测图.
具体的,backbone中有5个层级的feature maps,是提取哪一层,还是像UNet或者FPN那样逐层提取并整合输出?作者进行了两种探索,1是直接采用1x1卷积核提取Conv2的feature maps(没有经过stride=2下采样,此时Conv2的输出大小正好是4x下采样输入的大小),那么输出通道又是多少才合适?作者也进行了探讨.结果如下表.可以看到,输出通道数为48时精度最好.
那么将各feature maps整合之后,采用
3x3卷积核来提取特征,这里应该采取一个什么样的配置组合才是最好的?作者也进行了几组比较分析,如下表.可以看到,在经过[1,1,48]卷积核提取特征并与上采样特征进行整合之后,级联2个[3,3,256]卷积核效果最好.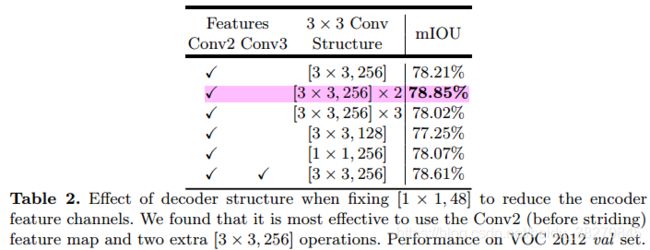
前面说到作者提取低层级的特征时探索了两种方案,第二种就是先将Encoder的输出上采样2x,然后与Conv3 concat,再经过1个
[3,3,256]卷积层,然后继续2x上采样,与Conv2 concat,再经过1个[3,3,256]卷积层,最后4x上采样得到预测结果.这与UNet的设计非常相似.但作者发现,这样做是有提高,但是麻烦而且效果不是最好.如上表所示,最后一组,就逊色于第二组.
Modified Aligned Xception 对Xception的3点改进,如下图.(1)引入更多的卷积层;(2)所有max pooling操作被替换为空洞可分离卷积;(3)每个3x3可分离卷积后跟着BN层与ReLU层.由于Xception效果比ResNet101要好,也是本文模型主打的backbone首选,就不分析ResNet101了.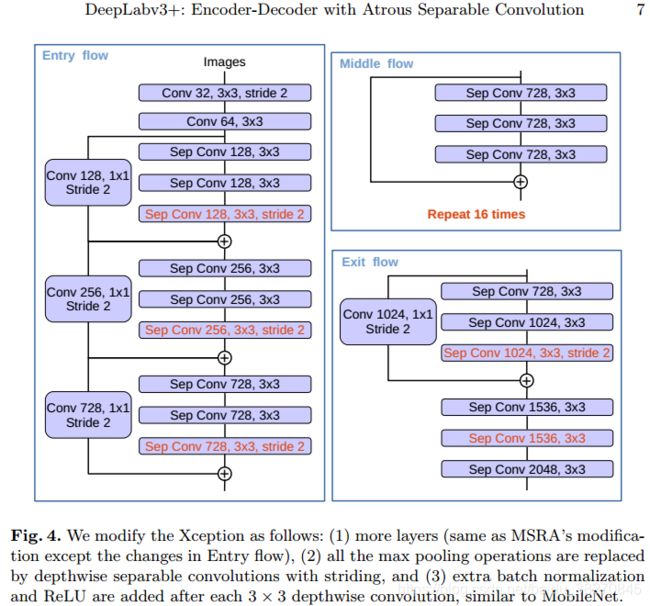
实验结果分析

最后说几句,学习了DeepLab这一系列,感受到模型性能的提升是由一系列方法技巧一点点累积起来的,着实不易.后处理往往能够带来很棒的效果,如果能够将这些后处理有效地融入到工业产品中,真正落地到实处,是工程师们最希望看到的.