文件系统-文件的逻辑结构与存取方法
逻辑结构
字符流式的无结构文件
- 字符流的无结构文件中查找基本信息单位比较困难
- 字符流的无结构文件管理简单,用户操作方便
- 对基本信息单位操作不多的文件较适于采用字符流的无结构方式,例如,源程序文件、目标代码文件等。
记录式的有结构文件
- 记录式的有结构文件把文件中的基本信息(记录)按不同方式排列构成不同的逻辑结构,方便用户对文件中的记录进行修改、追加、查找和管理等操作
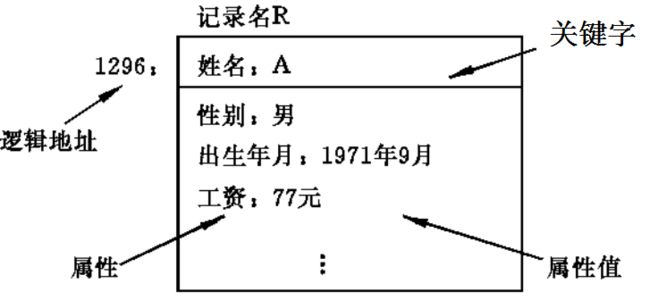
- 记录是一个具有特定意义的信息单位,由该记录在文件中的逻辑地址(相对位置) 以及与记录名对应的一组关键字、属性及其属性值组成。
- 一个记录可以有多个关键字,每个关键字可以对应多项属性。
记录式有结构文件四种格式
连续结构
- 记录按生成的先后顺序连续排列的逻辑结构。
- 连续结构的特点是适用性强,可用于所有文件 ,且记录的排列顺序与记录的内容无关。因此有利于记录的追加与变更。
- 连续结构文件的搜索性能较差,例如要找出某个指定关键字的记录时,系统必须进行全文件范围的搜索。
多重结构
记录按关键字和记录名排列成行列式结构,包含n个记录名、m个(m≤n)个关键字的文件构成一个m×n维行列式。
第i(1≤i≤m) 行和第j(1≤j≤n) 列对应位置为1表示关键字Ki在记录 Rj中;反之表示关键字Ki不在记录 Rj 中。同一个关键字可以同时属于不同记录。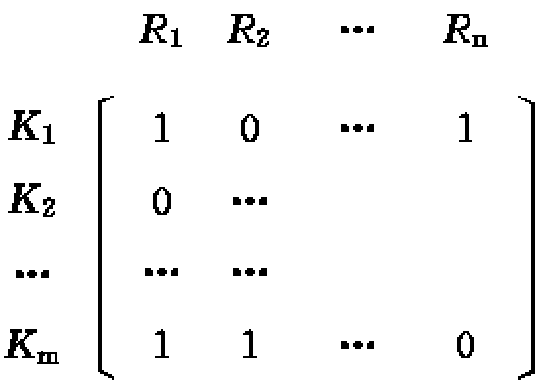
为了节约空间行列式的改进:
如果只按行列式结构排列记录,将会浪费较多存储空间。
去掉行列式中那些为零的项,并以关键字Ki为队首,以包含关键字Ki的记录为队列元素构成一个记录队列。
对于有m个关键字的记录来说,这样的队列有m个。
这m个队列构成了该文件的多重结构(multi_list)。
特点:
搜索时优于连续结构,但在搜索某一特定记录时,必须在找到该记录所对应的关键字之后,再在该关键字所对应的队列中顺序查找。
转置结构
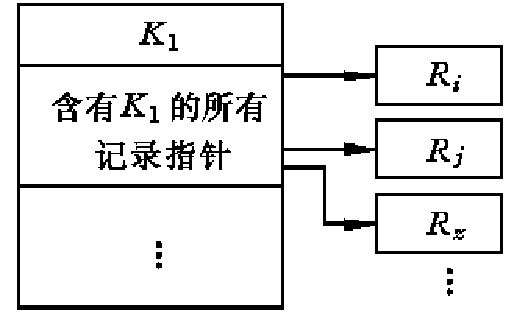
转置结构把含有相同关键字的记录指针全部指向该关键字,也就是说,把所有与同一关键字对应的记录的指针连续地置于目录中该关键字的位置.
转置结构最适合给定关键字后的记录搜索。
顺序结构
如果系统要求按某种优先顺序来搜索或追加、删除记录,则最好采用顺序结构。
如果给定了顺序规定(例如按字母顺序),则把文件中的关键字按规定顺序排列起来就形成了顺序结构文件
例子:例如,把人民日报新闻按年月日为关键字做成记录放入文件中,并以时间先后顺序组成文件。要获取某段时间内所发生的大事等问题,变得非常简单。例如用户想了解两伊战争的情况,只要搜索1990年8 月19日开始的两个月内的有关记录即可。
选取文件逻辑结构的原则
1.针对修改操作,给定的逻辑结构能尽量减少对已存储好的文件信息的变动。
2.给定逻辑结构下能在尽可能短的时间内查找到需要查找的记录或基本信息单位。
3.给定逻辑结构下文件信息占据最小的存储空间。
4.给定逻辑结构便于用户进行操作。
存取方法
顺序存取法
顺序存取按照文件的逻辑地址顺序存取
例子:若当前读取的记录为Ri,则下一次读取的记录被自动地确定为Ri的下一个相邻记录Ri+1。
特点:在无结构字符流文件中,顺序存取反映当前读写指针的变化。在存取完一段信息之后,读写指针自动加或减去该段信息长度,指出下次存取时的位置。
大多数操作系统采用顺序存取和随机存取方法。
随机存取法(直接存取法)
随机存取法允许用户根据记录编号存取文件的任一记录,或者是根据存取命令把读写指针移到指定读写处进行读写。
大多数操作系统采用顺序存取和随机存取方法。
按关键字存取法
按关键字存取法通常用于复杂文件系统,特别是数据库管理系统。
根据给定的关键字或记录名进行文件的存取。首先搜索待存取记录的逻辑位置,再将其转换到相应的物理地址后进行存取。
按关键字存取法对文件的搜索包括两种:关键字搜索和记录搜索。
关键字搜索
关键字搜索是在用户给定要搜索的关键字和记录之后,确定该关键字在文件中的位置
记录搜索
记录搜索是在搜索到要查找的关键字之后,在含有该关键字的所有记录中查找出需要的记录。
三种搜索算法
线性搜索法(linear search);
从第一个关键字或记录开始,依次与待搜索的关键字或记录比较,直到找到需要的记录为止。
线性搜索法搜索时间与搜索表格大小的 1/2成正比。因为找到一个需要的记录平均要和表中登记的总项数的1/2项比较后才能得到。
线性搜索法的搜索效率较低,在文件中记录个数较多时不宜采用。
散列法(hash coding)
广泛用于现代操作系统的数据查找。
散列法的核心思想是定义一个散列函数h(k),将给定的关键字k变换为与其对应的逻辑地址。
使用散列函数进行搜索时,有时会出现两个不同的输入值变换到同一地址的问题。即对于k1!=k2,有h(k1)=h(k2)=A。
由散列变换得到的结果并不是要搜索的关键字,称为散列冲突。
散列冲突的解决方法
- 线性散列法
- 随机数组法
- 平方散列函数
二分搜索法(binary search algorithm)。
对于顺序结构排列的关键字或记录,二分搜索法具有较高的搜索效率。其实就是对有序的信息,进行二分查找。时间复杂度O(log2N)