(三)论文阅读 | 目标检测之CenterNet-Points
简介

论文是 2019 {\rm 2019} 2019年的一篇 A n c h o r {\rm Anchor} Anchor- F r e e {\rm Free} Free目标检测算法。前面介绍的 C o r n e r N e t {\rm CornerNet} CornerNet通过检测左上角关键点和右下角关键点完成目标检测; C e n t e r N e t {\rm CenterNet} CenterNet在前者的基础上,额外检测一个中心关键点用于辅助检测流程。而本文介绍的 C e n t e r N e t {\rm CenterNet} CenterNet仅通过检测目标的中心关键点就能完成检测流程。在原论文中, C e n t e r N e t {\rm CenterNet} CenterNet可以轻易迁移到 3 D {\rm 3D} 3D目标检测和人体姿态估计中,而本文只介绍其用于 2 D {\rm 2D} 2D目标检测。在 M S C O C O {\rm MS\ COCO} MS COCO数据集上的实验结果为 A P 28.1 % 142 F P S {\rm AP28.1\%\ 142FPS} AP28.1% 142FPS、 A P 37.4 % 52 F P S {\rm AP37.4\%\ 52FPS} AP37.4% 52FPS、 A P 45.1 % 1.4 F P S {\rm AP45.1\%\ 1.4FPS} AP45.1% 1.4FPS。论文原文 源码
0. Abstract
论文指出大多数检测算法的做法是产生大量对目标位置的预测,但这类做法耗时低效且需要后处理。与前面介绍的 C o r n e r N e t {\rm CornerNet} CornerNet类似,论文提出将目标检测转化为检测关键点,且仅依靠检测边界框的中心点就能确定最终的检测结果。
论文贡献:(一)提出一种新的 A n c h o r {\rm Anchor} Anchor- F r e e {\rm Free} Free目标检测方法;(二)论文方法可轻易迁移至 3 D {\rm 3D} 3D目标检测和人体姿态估计等相关检测任务。
1. Introduction
当前大多数目标检测方法首先产生大量建议框,然后判别每个框内是否含有目标。然而,由于这类算法需要产生所有可能的建议框而常常需要大量冗余的计算,进而影响了算法的精度和实时性。

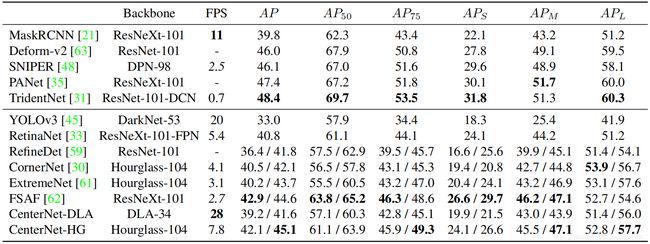
论文提出了一种简单和高效的方法:如上图,使用边界框的中心点表示物体。将图像输入到一个全卷积网络得到一个热图,这个热图的峰值对应于目标的中心点,峰值周围的图像特征用于预测边界框的高和宽。在推理阶段, C e n t e r N e t {\rm CenterNet} CenterNet使用单个网络进行前向传播,无需 N M S {\rm NMS} NMS等后处理。 C e n t e r N e t {\rm CenterNet} CenterNet与其他检测算法的实验对比见下图:

2. Related Work
C e n t e r N e t {\rm CenterNet} CenterNet方法同 A n c h o r {\rm Anchor} Anchor- B a s e d {\rm Based} Based的一阶段方法相关,一个中心点可以看做是单个形状不定的 A n c h o r {\rm Anchor} Anchor。但也存在不同之处: ( 1 ) (1) (1) C e n t e r N e t {\rm CenterNet} CenterNet仅根据位置来分配 A n c h o r {\rm Anchor} Anchor ,没有手动设置的用于前景和背景分类的阈值; ( 2 ) (2) (2) C e n t e r N e t {\rm CenterNet} CenterNet仅含有一个正类 A n c h o r {\rm Anchor} Anchor ,不需要 N M S {\rm NMS} NMS后处理; ( 3 ) (3) (3) C e n t e r N e t {\rm CenterNet} CenterNet使用较大分辨率的输出,避免使用多重 A n c h o r {\rm Anchor} Anchor。

图 ( 4 ) (4) (4)的左半部分是 A n c h o r {\rm Anchor} Anchor- B a s e d {\rm Based} Based的目标检测算法,当候选框同真实框的交并比大于 0.7 {\rm 0.7} 0.7时则视该候选框为正样本;否则为负样本。右半部分是 C e n t e r N e t {\rm CenterNet} CenterNet的做法,通过预测目标的中心直接回归目标的具体位置。
3. Preliminary
首先定义几个相关变量。 I I I表示宽为 W W W,高为 H H H的输入图形; C e n t e r N e t {\rm CenterNet} CenterNet基于输入产生关键点热图 Y ^ \hat{Y} Y^, R R R表示输出的步长(下采样的倍数), C C C是关键点的类别数; Y ^ = 1 \hat{Y}=1 Y^=1表示检测的关键点, Y ^ = 0 \hat{Y}=0 Y^=0表示背景。注意: I ∈ R W × H × 3 I\in R^{W×H×3} I∈RW×H×3, Y ^ ∈ [ 0 , 1 ] W / R × H / R × 3 \hat{Y}\in[0,1]^{W/R×H/R×3} Y^∈[0,1]W/R×H/R×3。
对于类别为 c c c的标注关键点 p p p,计算其在下采样图中为 p ~ \tilde{p} p~。然后使用高斯核 Y x y c Y_{xyc} Yxyc将所有标注关键点分散到一个热图 Y Y Y上, σ 2 σ^2 σ2表示标准差。如果同一类别的两个高斯计算结果相同,取较大值。注意: p ∈ R 2 p\in \mathcal{R}^2 p∈R2, p ~ = ⌊ p / R ⌋ \tilde{p}=\lfloor p/R\rfloor p~=⌊p/R⌋, Y x y c = e x p ( − ( x − p ~ x ) 2 + ( y − p ~ y ) 2 / 2 σ p 2 ) Y_{xyc}={\rm exp}(-(x-\tilde{p}_x)^2+(y-\tilde{p}_y)^2/2σ^2_p) Yxyc=exp(−(x−p~x)2+(y−p~y)2/2σp2), Y ∈ [ 0 , 1 ] W / R × H / R × c Y\in[0,1]^{W/R×H/R×c} Y∈[0,1]W/R×H/R×c。由此得到第一部分损失函数 L k L_k Lk:
L k = − 1 N ∑ x y c { ( 1 − Y ^ x y c ) α l o g ( Y ^ x y c ) i f Y x y c = 1 ( 1 − Y x y c ) β ( Y ^ x y c ) α l o g ( 1 − Y ^ x y c ) o t h e r w i s e (1) L_k =\frac{-1}{N}\sum\limits_{xyc}\left\{ \begin{aligned} &(1-\hat{Y}_{xyc})^α{\rm log}(\hat{Y}_{xyc})&if\ \ Y_{xyc}=1\\ &(1-Y_{xyc})^β(\hat{Y}_{xyc})^α{\rm log}(1-\hat{Y}_{xyc})&otherwise \end{aligned} \right.\tag{1} Lk=N−1xyc∑{(1−Y^xyc)αlog(Y^xyc)(1−Yxyc)β(Y^xyc)αlog(1−Y^xyc)if Yxyc=1otherwise(1)
同时预测一个偏移 O ^ \hat{O} O^处理下采样后的图像中的关键点映射回原图所产生误差,由此得到第二部分损失函数 L o f f L_{off} Loff:
L o f f = 1 N ∑ p ∣ O ^ p ~ − ( p R − p ~ ) ∣ (2) L_{off} =\frac{1}{N}\sum\limits_{p}|\hat{O}_{\tilde{p}}-(\frac{p}{R}-\tilde{p})| \tag{2} Loff=N1p∑∣O^p~−(Rp−p~)∣(2)
注意: O ^ ∈ R W / R × H / R × 2 \hat{O}∈R^{W/R×H/R×2} O^∈RW/R×H/R×2, L o f f L_{off} Loff的计算只针对正样本。
4. Objects as Points
首先定义几个相关变量。 ( x 1 ( k ) , y 1 ( k ) , x 2 ( k ) , y 2 ( k ) ) (x_1^{(k)},y_1^{(k)},x_2^{(k)},y_2^{(k)}) (x1(k),y1(k),x2(k),y2(k))表示类别为 c k c_k ck的目标 k k k的边界框,则其中心点的坐标为 p k = ( ( x 1 ( k ) + x 2 ( k ) ) / 2 , p_k=((x_1^{(k)}+x_2^{(k)})/2, pk=((x1(k)+x2(k))/2, ( y 1 ( k ) + y 2 ( k ) ) ) / 2 ) (y_1^{(k)}+y_2^{(k)}))/2) (y1(k)+y2(k)))/2)。使用前面定义的热图 Y ^ \hat{Y} Y^来预测所有的中心点。此外,对于每个目标 k k k,回归边界框的宽高 s k = ( x 2 ( k ) − x 1 ( k ) , y 2 ( k ) − y 1 ( k ) ) s_k=(x_2^{(k)}-x_1^{(k)},y_2^{(k)}-y_1^{(k)}) sk=(x2(k)−x1(k),y2(k)−y1(k))。同时,为了减少计算量,对每个类别使用同样的宽高预测 S ^ \hat{S} S^。由此得到第三部分损失函数 L s i z e L_{size} Lsize:
L s i z e = 1 N ∑ k = 1 N ∣ S ^ p k − s k ∣ (3) L_{size} =\frac{1}{N}\sum\limits_{k=1}^{N} |\hat{S}_{p_k}-s_k| \tag{3} Lsize=N1k=1∑N∣S^pk−sk∣(3)
注意, S ^ ∈ R W / R × H / R × 2 \hat{S}∈R^{W/R×H/R×2} S^∈RW/R×H/R×2。则总的损失函数 L d e t L_{det} Ldet定义为:
L d e t = L k + λ s i z e L s i z e + λ o f f L o f f (4) L_{det} =L_k+λ_{size}L_{size}+λ_{off}L_{off} \tag{4} Ldet=Lk+λsizeLsize+λoffLoff(4)
网络同时预测关键点热图 Y ^ \hat{Y} Y^、位置偏移 O ^ \hat{O} O^、宽高预测 S ^ \hat{S} S^,在每个像素点位置得到 C + 4 C+4 C+4个输出。

C + 4 C+4 C+4对应于上图中的三幅图,第一幅图中为 C C C表示类别、第二幅图中为 2 2 2表示中心点的偏移、第三幅图中为 2 2 2表示预测的宽高。
如何使用中心点生成边界框?在推理阶段,独立地提取每个类别热图的峰值,判断峰值是否大于或等于其 8 8 8-领域的值,最后保留前 100 100 100个峰值。 P ^ c \hat{\mathcal{P}}_c P^c表示类别 c c c得到的 n n n个检测点,每个关键点的坐标为 ( x i , y i ) (x_i, y_i) (xi,yi), Y ^ x i y i c \hat{Y}_{x_iy_ic} Y^xiyic为其置信度。得到边界框(左上角坐标和右下角坐标):
( x ^ i + δ x ^ i − w ^ i / 2 , y ^ i + δ y ^ i − h ^ i / 2 ) (\hat{x}_i+δ\hat{x}_i-\hat{w}_i/2,\hat{y}_i+δ\hat{y}_i-\hat{h}_i/2) (x^i+δx^i−w^i/2,y^i+δy^i−h^i/2)
( x ^ i + δ x ^ i + w ^ i / 2 , y ^ i + δ y ^ i + h ^ i / 2 ) (\hat{x}_i+δ\hat{x}_i+\hat{w}_i/2,\hat{y}_i+δ\hat{y}_i+\hat{h}_i/2) (x^i+δx^i+w^i/2,y^i+δy^i+h^i/2)
其中 P ^ c = { ( x i ^ , y i ^ ) } i = 1 n \hat{\mathcal{P}}_c=\{(\hat{x_i},\hat{y_i})\}_{i=1}^n P^c={(xi^,yi^)}i=1n, ( δ x i ^ , δ y i ^ ) = O ^ x i ^ , y i ^ (δ\hat{x_i},δ\hat{y_i})=\hat{O}_{\hat{x_i},\hat{y_i}} (δxi^,δyi^)=O^xi^,yi^为预测的偏移, ( w ^ i , h ^ i ) = S ^ x ^ i , y ^ i (\hat{w}_i,\hat{h}_i)=\hat{S}_{\hat{x}_i,\hat{y}_i} (w^i,h^i)=S^x^i,y^i为预测的宽高。
5. Implementation Details
论文使用四种 B a c k b o n e {\rm Backbone} Backbone做实验:

6. Experiments
7. Conclusion
论文提出了一种新的用中心点表示目标的方法。 C e n t e r N e t {\rm CenterNet} CenterNet检测目标的中心,然后回归宽高;算法简单高效,不需要任何 N M S {\rm NMS} NMS等后处理。由于 C e n t e r N e t {\rm CenterNet} CenterNet的简单高效性,其稍加改动就可以将其应用于 3 D {\rm 3D} 3D目标检测和人体姿态估计,笔者认为这是当前目标检测算法应该具有的特性。这是因为 3 D {\rm 3D} 3D目标检测和人体姿态估计等都是基于目标检测任务的。
参考
- Zhou X, Wang D, Krähenbühl P. Objects as points[J]. arXiv preprint arXiv:1904.07850, 2019.