概率机器学习和人工智能(Probabilistic machine learning and artificial intelligence_Nature2015)
This survey paper is regards to Probabilistic Machine Learning and Artificial Intelligence from Zoubin Ghahramani, which is published in Nature in 2015.
URL: http://blog.csdn.net/shanglianlm/article/details/46723425
Although the concepts of probalilistic machine learning is simple,
Although conceptually simple, a fully probabilistic approach to machine learning poses a number of computational and modelling challenges. Computationally, the main challenge is that learning involves marginalizing (summing out) all the variables in the model except for the variables of interest (Box 1). Such high-dimensional sums and integrals are generally computationally hard, in the sense that for many models
there is no known polynomial time algorithm for performing them exactly. Fortunately, a number of approximate integration algorithms have been developed, including Markov chain Monte Carlo (MCMC) methods, variational approximations, expectation propagation and sequential Monte Carlo23–26. It is worth noting that computational techniques are one area in which Bayesian machine learning differs from much of the rest of machine learning: for Bayesian researchers the main computational problem is integration, whereas for much of the rest of the community the focus is on optimization of model parameters. However, this dichotomy is not as stark as it appears: many gradient-based optimization methods can be turned into integration methods through the use of Langevin and Hamiltonian Monte Carlo methods27,28, while integration problems can be turned into optimization problems through the use of variational approximations24. I revisit optimization in a later section.
The main modelling challenge for probabilistic machine learning is that the model should be flexible enough to capture all the properties of the data required to achieve the prediction task of interest. One approach to addressing this challenge is to develop a prior distribution that encompasses an open-ended universe of models that can adapt in complexity to the data. The key statistical concept underlying flexible models that grow in complexity with the data is non-parametrics.
Probabilistic modelling and representing uncertainty
Flexibility through non-parametrics
Probabilistic programming
The basic idea of probabilistic programming is to use computer programs to represent probabilistic models (http://probabilistic-programming.org) [][][].
One way to do this is for the computer program to define a generator for data from the probabilistic model, that is, a simulator (Fig. 2). This simulator makes calls to a random number generator in such a way that repeated runs from the simulator would sample different possible data sets from the model.
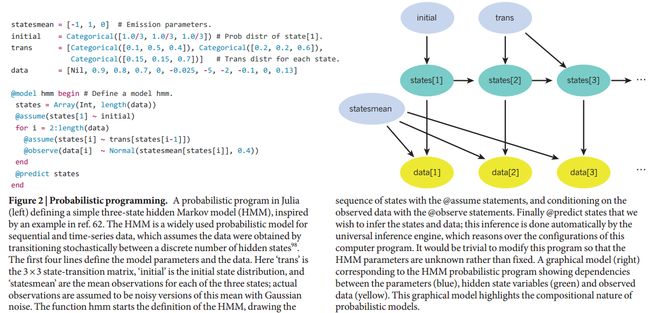
Probabilistic programming offers an elegant way of generalizing graphical models , allowing a much richer representation of models, because computer programs can allow constructs such as recursion (functions calling themselves) and control flow statements (for example, ‘if ’ statements that result in multiple paths a program can follow).
In fact, for many of the recent probabilistic programming languages that are based on extending Turing-complete languages (a class that includes almost all commonly used languages), it is possible to represent any computable probability distribution as a probabilistic program [].
The full potential of probabilistic programming comes from automating the process of inferring unobserved variables in the model conditioned on the observed data (Box 1). Conceptually, conditioning needs
to compute input states of the program that generate data matching the
observed data. Whereas normally we think of programs running from
inputs to outputs, conditioning involves solving the inverse problem of
inferring the inputs (in particular the random number calls) that match
a certain program output. Such conditioning is performed by a ‘universal inference engine’, usually implemented by Monte Carlo sampling
over possible executions of the simulator program that are consistent
with the observed data. The fact that defining such universal inference
algorithms for computer programs is even possible is somewhat surprising, but it is related to the generality of certain key ideas from sampling
such as rejection sampling, sequential Monte Carlo methods25 and
‘approximate Bayesian computation’49.
As an example, imagine you write a probabilistic program that simulates a gene regulatory model that relates unmeasured transcription
factors to the expression levels of certain genes. Your uncertainty in each
part of the model would be represented by the probability distributions
used in the simulator. The universal inference engine can then condition
the output of this program on the measured expression levels, and automatically infer the activity of the unmeasured transcription factors and
other uncertain model parameters. Another application of probabilistic
programming implements a computer vision system as the inverse of a
computer graphics program50.
There are several reasons why probabilistic programming could prove to be revolutionary for machine intelligence and scientific modelling.
-First, the universal inference engine obviates the need to manually derive inference methods for models. Since deriving and implementing inference methods is generally the most rate-limiting and bug-prone step in modelling, often taking months, automating this step so that it takes minutes or seconds will greatly accelerate the deployment of machine learning systems.
-Second, probabilistic programming could be potentially transformative for the sciences, since it allows for rapid prototyping and testing of different models of data. Probabilistic programming languages create a very clear separation between the model and the inference procedures, encouraging model-based thinking[].
There are a growing number of probabilistic programming languages. BUGS, Stan, AutoBayes and Infer.NET allow only a restrictive class of models to be represented compared with systems based on Turing-complete languages. In return for this restriction, inference in such languages can be much faster than for the more general languages, such as IBAL, BLOG, Church, Figaro, Venture, and Anglican. A major emphasis of recent work is on fast inference in general languages.
Nearly all approaches to probabilistic programming are Bayesian since it is hard to create other coherent frameworks for automated reasoning about uncertainty.
Notable exceptions are systems such as Theano, which is not itself a probabilistic programming language but uses symbolic differentiation to speed up and automate optimization of parameters of neural networks and other probabilistic models [].
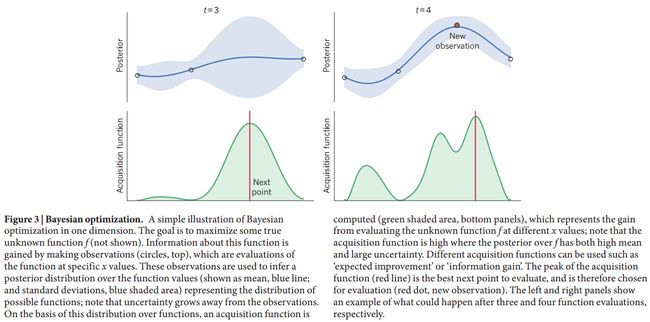
Bayesian optimization
Data compression
Consider the problem of compressing data so as to communicate them or store them in as few bits as possible in such a manner that the original data can be recovered exactly from the compressed data. Methods for such lossless data compression are ubiquitous in information technology, from computer hard drives to data transfer over the internet. Data compression and probabilistic modelling are two sides of the same coin, and Bayesian machine-learning methods are increasingly advancing the state-of-the-art in compression. The connection between compression and probabilistic modelling was established in the mathematician Claude Shannon’s seminal work on the source coding theorem 77[], which states that the number of bits required to compress data in a lossless manner is bounded by the entropy of the probability distribution of the data. All commonly used lossless data compression algorithms (for example, gzip) can be viewed as probabilistic models of sequences of symbols.
The link to Bayesian machine learning is that the better the probabilistic model one learns, the higher the compression rate can be 78[]. These models need to be flexible and adaptive, since different kinds of sequences have very different statistical patterns (say, Shakespeare’s plays or computer source code). It turns out that some of the world’s best compression algorithms (for example, Sequence Memoizer79 [] and PPM with dynamic parameter updates 80 []) are equivalent to Bayesian non-parametric models of sequences, and improvements to compression are being made through a better understanding of how to learn the statistical structure of sequences.
Future advances in compression will come with advances in probabilistic machine learning, including special compression methods for non-sequence data such as images, graphs and other structured objects.
Automatic discovery of interpretable models from data
One of the grand challenges of machine learning is to fully automate the process of learning and explaining statistical models from data. This is the goal of the Automatic Statistician (http://www.automaticstatistician.com), a system that can automatically discover plausible models from data, and explain what it has discovered in plain English81. This could be useful to almost any field of endeavour that is reliant on extracting knowledge from data. In contrast to the methods described in much of the machinelearning literature, which have been focused on extracting increasing performance improvements on pattern-recognition problems using techniques such as kernel methods, random forests or deep learning, the Automatic Statistician builds models that are composed of interpretable components, and has a principled way of representing uncertainty about model structures given the data. It also gives reasonable answers not just for big data sets, but also for small ones. Bayesian approaches provide an elegant way of trading off the complexity of the model and the complexity of the data, and probabilistic models are compositional and interpretable, as already described.

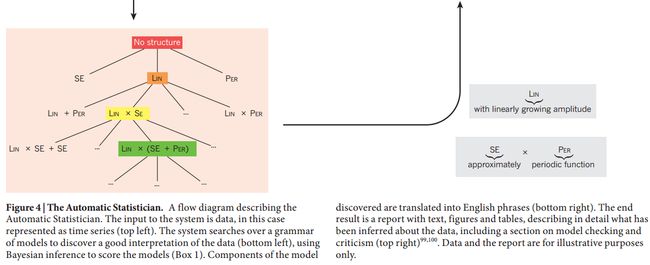
A prototype version of the Automatic Statistician takes in time-series data and automatically generates 5–15 page reports describing the model it has discovered(Fig. 4). This system is based on the idea that probabilistic building blocks can be combined through a grammar to buildan open-ended language of models []82. In contrast to work on equation learning (see for example ref. []83), the models attempt to capture general properties of functions (for example, smoothness, periodicity or trends) rather than a precise equation. Handling uncertainty is at the core of the Automatic Statistician; it makes use of Bayesian non-parametrics to give it the flexibility to obtain state-of-the-art predictive performance, and uses the metric marginal likelihood (Box 1) to search the space of models.
Important earlier work includes statistical expert systems [] []84,85 and the Robot Scientist, which integrates machine learning and scientific discovery in a closed loop with an experimental platform in microbiology to automate the design and execution of new experiments [] 86. Auto-WEKA is a recent project that automates learning classifiers, making heavy use of the Bayesian optimization techniques already described [] 71. Efforts to automate the application of machine-learning methods to data have recently gained momentum, and may ultimately result in artificial intelligence systems for data science.
Perspective
The information revolution has resulted in the availability of ever larger collections of data. What is the role of uncertainty in modelling such big data? Classic statistical results state that under certain regularity conditions, in the limit of large data sets the posterior distribution of the parameters for Bayesian parametric models converges to a single point around the maximum likelihood estimate. Does this mean that Bayesian probabilistic modelling of uncertainty is unnecessary if you have a lot of data?
There are at least two reasons this is not the case [] 87. First, as we have seen, B**ayesian non-parametric models have essentially infinitely many parameters**, so no matter how many data one has, their capacity to learn should not saturate, and their predictions should continue to improve.
Second, many large data sets are in fact large collections of small data sets. For example, in areas such as personalized medicine and recommendation systems, there might be a large amount of data, but there is still a relatively small amount of data for each patient or client, respectively. To customize predictions for each person it becomes necessary to build a model for each person — with its inherent uncertainties — and to couple these models together in a hierarchy so that information can be borrowed from other similar people. We call this the personalization of models, and it is naturally implemented using hierarchical Bayesian approaches such as hierarchical Dirichlet processes [] 36, and Bayesian multitask learning [][] 88,89.
Probabilistic approaches to machine learning and intelligence are a very active area of research with wide-ranging impact beyond conventional pattern-recognition problems. As I have outlined, these problems include data compression, optimization, decision making, scientific model discovery and interpretation, and personalization. The key distinction between problems in which a probabilistic approach is important and problems that can be solved using non-probabilistic machine-learning approaches is whether uncertainty has a central role. Moreover, most conventional optimization-based machine-learning approaches have probabilistic analogues that handle uncertainty in a more principled manner. For example, Bayesian neural networks represent the parameter uncertainty in neural networks [] 44, and mixture models are a probabilistic analogue for clustering methods [] 78. Although probabilistic machine learning often defines how to solve a problem in principle, the central challenge in the field is finding how to do so in practice in a computationally efficient manner [][] 90,91. There are many approaches to the efficient approximation of computationally hard inference problems. Modern inference methods have made it possible to scale to millions of data points, making probabilistic methods computationally competitive with conventional methods [][][][] 92–95. Ultimately, intelligence relies on understanding and acting in an imperfectly sensed and uncertain world. Probabilistic modelling will continue to play a central part in the development of ever more powerful machine learning and artificial intelligence systems.
Bayesian machine learning
There are two simple rules in probability theory(概率论): the sum rule:
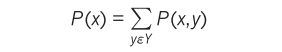
the product rule:

The sum rule states that the marginal P(x) of x is obtained by summing (or integrating for continuous variables) the joint over y . The product rule states that the joint P(x,y) can be decomposed as the product of the marginal P(x) and the conditional P(y|x) .
Bayes rule is a corollary of above two rules:
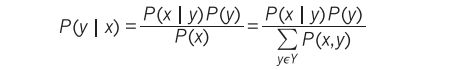
In order to apply probability theory to machine learning, we replace x by D to denote the observed data, and replace y by θ to denote the unknown parameters of a model. We also condition all terms on m , the class of probabilistic models we are considering. Thus, we get
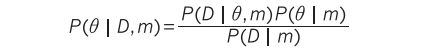
where P(D|θ,m) is the likelihood of parameters θ in model m , P(θ|m) is the prior probability of θ and P(θ|D,m) is the posterior of θ given data D .
Learning is the transformation of prior knowledge or assumptions about the parameters P(θ|m) , through the data D , into posterior knowledge about the parameters, P(θ|D,m) . This posterior is now the prior to be used for future data.
A learned model can be used to predict or forecast new unseen test data, Dtest , by simply applying the sum and product rule to get the prediction:

Finally, different models can be compared by applying Bayes rule at the level of m:

The term P(D|m) is the marginal likelihood or model evidence, and implements a preference for simpler models known as Bayesian Ockham’s razor.
Reference and related materials:
[1] Probabilistic machine learning and artificial intelligence
45.Koller, D., McAllester, D. & Pfeffer, A. Effective Bayesian inference for stochastic
programs. In Proc. 14th National Conference on Artificial Intelligence 740–747
(1997).
46.Goodman, N. D. & Stuhlmüller, A. The Design and Implementation of Probabilistic
Programming Languages. Available at http://dippl.org (2015).
47.Pfeffer, A. Practical Probabilistic Programming (Manning, 2015).
48.Freer, C., Roy, D. & Tenenbaum, J. B. in Turing’s Legacy (ed. Downey, R.)
195–252 (2014).
49.Marjoram, P., Molitor, J., Plagnol, V. & Tavaré, S. Markov chain Monte Carlo
without likelihoods. Proc. Natl Acad. Sci. USA 100, 15324–15328 (2003).
50.Mansinghka, V., Kulkarni, T. D., Perov, Y. N. & Tenenbaum, J. Approximate
Bayesian image interpretation using generative probabilistic graphics
programs. In Proc. Advances in Neural Information Processing Systems 26
1520–1528 (2013).
51.Bishop, C. M. Model-based machine learning. Phil. Trans. R. Soc. A 371,
20120222 (2013).
This article is a very clear tutorial exposition of probabilistic modelling.
52.Lunn, D. J., Thomas, A., Best, N. & Spiegelhalter, D. WinBUGS — a Bayesian
modelling framework: concepts, structure, and extensibility. Stat. Comput. 10,
325–337 (2000).
This reports an early probabilistic programming framework widely used in
statistics
64.Bergstra, J. et al. Theano: a CPU and GPU math expression compiler. In Proc.
9th Python in Science Conference http://conference.scipy.org/proceedings/
scipy2010/ (2010).
77.Shannon, C. & Weaver, W. The Mathematical Theory of Communication (Univ.
Illinois Press, 1949).
78.MacKay, D. J. C. Information Theory, Inference, and Learning Algorithms
(Cambridge Univ. Press, 2003).
79.Wood, F., Gasthaus, J., Archambeau, C., James, L. & Teh, Y. W. The sequence
memoizer. Commun. ACM 54, 91–98 (2011).
This article derives a state-of-the-art data compression scheme based on
Bayesian nonparametric models.
80.Steinruecken, C., Ghahramani, Z. & MacKay, D. J. C. Improving PPM with
dynamic parameter updates. In Proc. Data Compression Conference (in the
press).
81.Lloyd, J. R., Duvenaud, D., Grosse, R., Tenenbaum, J. B. & Ghahramani, Z.
Automatic construction and natural-language description of nonparametric
regression models. In Proc. 28th AAAI Conference on Artificial Intelligence
Preprint at: http://arxiv.org/abs/1402.4304 (2014).
Introduces the Automatic Statistician, translating learned probabilistic
models into reports about data.
82.Grosse, R. B., Salakhutdinov, R. & Tenenbaum, J. B. Exploiting compositionality
to explore a large space of model structures. In Proc. Conference on Uncertainty
in Artificial Intelligence 306–315 (2012).
83.Schmidt, M. & Lipson, H. Distilling free-form natural laws from experimental
data. Science 324, 81–85 (2009).
84.Wolstenholme, D. E., O’Brien, C. M. & Nelder, J. A. GLIMPSE: a knowledge-based
front end for statistical analysis. Knowl. Base. Syst. 1, 173–178 (1988).
85.Hand, D. J. Patterns in statistical strategy. In Artificial Intelligence and Statistics
(ed Gale, W. A.) (Addison-Wesley Longman, 1986).
86.King, R. D. et al. Functional genomic hypothesis generation and
experimentation by a robot scientist. Nature 427, 247–252 (2004)
87.Welling, M. et al. Bayesian inference with big data: a snapshot from a workshop.
ISBA Bulletin 21, https://bayesian.org/sites/default/files/fm/bulletins/1412.
pdf (2014).
88.Bakker, B. & Heskes, T. Task clustering and gating for Bayesian multitask
learning. J. Mach. Learn. Res. 4, 83–99 (2003).
89.Houlsby, N., Hernández-Lobato, J. M., Huszár, F. & Ghahramani, Z. Collaborative
Gaussian processes for preference learning. In Proc. Advances in Neural
Information Processing Systems 26 2096–2104 (2012).
90.Russell, S. J. & Wefald, E. Do the Right Thing: Studies in Limited Rationality (MIT
Press, 1991).
91.Jordan, M. I. On statistics, computation and scalability. Bernoulli 19, 1378–1390
(2013).
92.Hoffman, M., Blei, D., Paisley, J. & Wang, C. Stochastic variational inference.
J. Mach. Learn. Res. 14, 1303–1347 (2013).
93.Hensman, J., Fusi, N. & Lawrence, N. D. Gaussian processes for big data. In Proc.
Conference on Uncertainty in Artificial Intelligence 244 (UAI, 2013).
94.Korattikara, A., Chen, Y. & Welling, M. Austerity in MCMC land: cutting the
Metropolis-Hastings budget. In Proc. 31th International Conference on Machine
Learning 181–189 (2014).
95.Paige, B., Wood, F., Doucet, A. & Teh, Y. W. Asynchronous anytime sequential
Monte Carlo. In Proc. Advances in Neural Information Processing Systems 27
3410–3418 (2014).