论文学习笔记-CenterNet(Objects as Points)
『写在前面』
应用最广泛的Anchor-Free 检测模型之一。
文章标题:《Objects as Points》
作者机构:Xingyi Zhou等, UT Austin.
原文链接:https://arxiv.org/abs/1904.07850
相关repo:https://github.com/xingyizhou/CenterNet
目录
摘要
1 介绍
2 相关工作
3 预备
4 Objects as Points
4.1 3D目标检测
4.2 人体姿势估计
6 实验结果
摘要
现有的大多数检测模型都首先会枚举大量的潜在box,这是低效的,而且往往还需要额外的后处理步骤辅助。
本文提出将目标建模成其box的中心点,通过关键点估计的方式找到它,然后通过回归的方式去回归box的其他属性,如长、宽等。
CenterNet的思路可以延伸到3D目标检测、姿势估计等任务,只需要对需要回归的额外属性做改动即可。
CenterNet是端到端可微的,简单的,快速的而且比同等基于anchor的模型更准确的。
1 介绍
简而言之,Anchor based模型的思路是将目标检测简化为对大量潜在对象边界框的图像分类问题。
但伴随之的问题是冗余框的剔除问题,这必须引入额外的后处理步骤(比如NMS),而这些后处理步骤往往不可微,从而无法进行端到端训练(针对two-stage型模型)。
端到端的问题在One-stage型模型中得到解决,但是One-stage这种基于滑动窗口的思路有些浪费,因为要枚举所有可能的位置和尺寸。
本文提出的CenterNet提出了 一种更简单和高效的设计,直接将图像输入一个FCN网络,网络生成一张heatmap,heatmap的峰值对应目标的中心位置,同时使用该位置的 feature 来预测目标的其余属性。
模型的训练遵循常规的dense prediction模型训练方式。
2 相关工作
对比CenterNet和Anchor-based one-stage方法
相通之处:
中心点可以被视作一个形状不可知的anchor
不同点:
1)CenterNet根据位置来分配anchor,而不是根据框的重叠程度
2)对于每个目标,CenterNet只会分配一个正锚点,因而不需要使用NMS
3)CenterNet使用了stride = 4的输出分辨率,从而消除了对多个anchor的需求。
与CornerNet / ExtremeNet等基于关键点检测的目标检测方法相比,CenterNet的好处是不需要进行grouping等后处理操作。
3 预备
给定输入图像![]() ,CenterNet的目标是生成一张heatmap,
,CenterNet的目标是生成一张heatmap,![]() ,其中R是输出stride(下采样倍数),C是需要预测的关键点类别数。比如,对于人体姿势估计任务,一般C=17;而对于COCO的目标检测任务,C=80.在本文中,默认R=4.
,其中R是输出stride(下采样倍数),C是需要预测的关键点类别数。比如,对于人体姿势估计任务,一般C=17;而对于COCO的目标检测任务,C=80.在本文中,默认R=4.
在预测的heatmap上,值为1的地方对应检测到的关键点,反之值为0的地方对应背景。本文使用了3种不同的FCN型结构来预测heatmap:Hourglass、ResNet + Upsample、DLA.
在训练时,根据Ground Truth中的关键点,得到其在低分辨率feature map上的对应的位置,并在这些关键点上使用高斯核进行模糊处理,高斯核的标准差根据目标大小自适应调节。注意如果遇到间隔比较近的两个同类目标,在它们交界处的值取element-wise maximum,这么做的目的是防止两个目标交界处出现较高的响应,从而保证Ground Truth map上的peak一定是目标的center。
训练loss采用逐像素的交叉熵结合focal loss,如下图所示,通过除以图像中包含的关键点数目N来做规范化。

为了恢复因下采样而引起的量化误差,额外添加了2个channel(X&Y)用于预测偏移量,此处所有的类别共享相同的偏移预测。偏移量通过L1-loss进行训练,训练过程中只在Ground Truth处进行监督,其余位置不做监督。

4 Objects as Points
在得到目标中心点位置以后,还需要预测其包围框的宽高信息,CenterNet在输出heatmap上添加了2个通道分别用于预测bounding box的W&H。类似对center offset的预测,宽高的预测同样是所有类别共享的,其训练也通过L1-loss进行监督。

此处,作者没有对bounding box的宽高做任何处理,直接使用了原始坐标进行计算。进一步地,在最后的综合loss中对offset的loss和size的loss进行加权。

CenterNet使用独立的网络(均采用 3x3 conv + ReLU + 1x1 conv)分别预测关键点、偏移和尺寸,但它们共享同一个FCN backbone。对整个模型而言,其为每个feature map上的每个位置都输出一个(C + 4)维的向量。对2D目标检测任务,CenterNet的输出如下图所示,[]内表示通道数。

在做inference时怎么从点到框?
首先,提取heatmap上所有的peak,peak定义为8-邻域内的极值点,具体实现中可以借助3x3 max pooling op;
然后,根据score排序,得到top-100的极值点;
最后,结合预测出的offset和size,得到目标的包围框信息如下。所有的输出结果都直接从feature map上获得,而不需要再做NMS等后处理操作。
其中,
是网络预测的offset,
是网络预测的size.
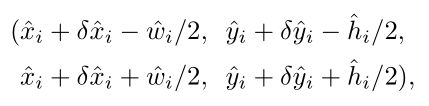
4.1 3D目标检测
对3D目标检测,加入额外的head结构用于预测尺寸、景深和朝向,具体如下图所示。

4.2 人体姿势估计
人体姿势估计需要为每个实例估计k个2D人体关键点位置。CenterNet将姿势考虑成关于中心点的一个k x 2维的属性,同时将各个关键点编码为关于中心点的偏移。通过L1-loss直接回归该联合偏移,同时通过mask操作忽略掉画面中不可见的关键点。
为了强化这些关键点,CenterNet还添加了一个输出k通道的head,遵循标准的bottom-up型多人姿势估计网络,直接估计各类别关键点的位置(不区分instance)。该部分的训练loss设计同预测center的heatmap的训练loss。
此外,还额外添加了2通道的head用于预测关键点的联合offset,类似对center offset的处理。

通过中心点的偏移定位出的关键点可以当做是一条对点(按instance)进行分组的线索,通过它来将(实例无关的)独立的关键点检测结果分配给不同的实例。
整体思路就是:首先根据中心点回归出与其相对于的关键点位置,然后根据这些点的位置去匹配真正的关键点检测结果。
最后只考虑检测框里内的关键点,将它们分配给相应的目标。
6 实验结果
