PyTorch 与 TensorboardX 的版本兼容性问题
1· PyTorch 与 TensorboardX 的版本兼容性问题
在tensorflow的使用中,大家往往都会用tensorboard进行数据的可视化,例如模型结构、损失函数的变化等,实际上PyTorch也可以使用TensorboardX 进行可视化。PyTorch有自己的visdom模块实现可视化,但是从接口的方便、简介的角度来说,TensorboardX用起来更加容易。
本文简要介绍一下自己的尝试以及遇到的问题。先放结论:(不想细看的朋友们直接看结论好了)
PyTorch 1.1.0及以前的版本,最好使用tensorboardX 1.7及以前,因为在1.8更新了add_graph方法导致其可能无法使用。add_graph方法用于可视化模型结构。
PyTorch 1.2.0及以上可以使用更新的tensorboardX,上述的方法实现更新实际上对较新版本的PyTorch有更好的支持。
更新后的测试
更新了torch 1.3.1 + torchvision 0.4.2 + tensorboardX 2.0,用起来没什么问题,果然新版本配套使用效果更佳。由于我CUDA版本是10.0,所以更新时要使用:
pip3 install torch==1.3.1+cu100 torchvision==0.4.2+cu100 -f https://download.pytorch.org/whl/torch_stable.html
同时装有Python2和3的要注意根据版本使用pip或pip3,不过现在python2不再更新维护了,以后还是都用python3比较好。目前pytorch默认支持cuda版本是10.1,其他版本的要注意加上后缀(CUDA10.0 +cu100, 9.2 +cu92, cpu版 +cpu)
另外看到PyTorch的更新日志显示,1.1.0后不支持CUDA8.0了,也不知道10.0能撑到哪个版本。关于开源工具版本的迭代与开发者硬件之间的问题,大家怎么看呢,一起分享一下呀。
以下是个人经历,分享一下避免踩坑:
我自己想尝试一下TensorboardX,于是通过pip安装了一下,如下:
pip3 install tensorboardX
由于对其更新也缺乏了解,没有指定版本,这个时候是2.0版本的tensorboardX。
我的PyTorch版本是1.1.0,系统是Ubuntu 19.04.
用前面博客中自己写的AlexNet识别手写数字为例,首先尝试了loss的可视化,在train的方法中做一点小更新:
from tensorboardX import SummaryWriter
def train(epochs, trainLoader, model, device, Lr, momen):
writer = SummaryWriter(logdir='./log')
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(model.parameters(), lr=Lr, momentum=momen)
model.to(device)
model.train()
numInLoader = len(trainLoader)
for e in range(epochs):
for i, (imgs, labels) in enumerate(trainLoader):
imgs = imgs.to(device)
labels = labels.to(device)
out = model(imgs)
loss = criterion(out, labels)
optimizer.zero_grad() # if don't call zero_grad, the grad of each batch will be accumulated
loss.backward()
optimizer.step()
if i%20==0:
print('epoch: {}, batch: {}, loss: {}'.format(e + 1, i + 1, loss.data))
niter = e * numInLoader + i
with writer:
writer.add_scalars('Train_loss', {"train_loss": loss.data.item()}, niter)
torch.save(model, 'myAlexMnistDemo.pth') # save net model and parameters
首先从 tensorboardX 中 import SummaryWriter,
writer = SummaryWriter(logdir='./log',comment='myAlexNet')
定义一个writer,logdir是log目录地址。SummaryWriter的构造函数其它参数还包括:
def __init__(self, logdir=None, comment='', purge_step=None, max_queue=10,
flush_secs=120, filename_suffix='', write_to_disk=True, log_dir=None, **kwargs):
"""Creates a `SummaryWriter` that will write out events and summaries
to the event file.
Args:
logdir (string): Save directory location. Default is
runs/**CURRENT_DATETIME_HOSTNAME**, which changes after each run.
Use hierarchical folder structure to compare
between runs easily. e.g. pass in 'runs/exp1', 'runs/exp2', etc.
for each new experiment to compare across them.
comment (string): Comment logdir suffix appended to the default
``logdir``. If ``logdir`` is assigned, this argument has no effect.
purge_step (int):
When logging crashes at step :math:`T+X` and restarts at step :math:`T`,
any events whose global_step larger or equal to :math:`T` will be
purged and hidden from TensorBoard.
Note that crashed and resumed experiments should have the same ``logdir``.
max_queue (int): Size of the queue for pending events and
summaries before one of the 'add' calls forces a flush to disk.
Default is ten items.
flush_secs (int): How often, in seconds, to flush the
pending events and summaries to disk. Default is every two minutes.
filename_suffix (string): Suffix added to all event filenames in
the logdir directory. More details on filename construction in
tensorboard.summary.writer.event_file_writer.EventFileWriter.
write_to_disk (boolean):
If pass `False`, SummaryWriter will not write to disk.
接下来,通过add_scalars增加要可视化的数据:
writer.add_scalars('Train_loss', {"train_loss": loss.data.item()}, niter)
其参数列表包括:
def add_scalars(self, main_tag, tag_scalar_dict, global_step=None, walltime=None):
"""Adds many scalar data to summary.
Note that this function also keeps logged scalars in memory. In extreme case it explodes your RAM.
Args:
main_tag (string): The parent name for the tags
tag_scalar_dict (dict): Key-value pair storing the tag and corresponding values
global_step (int): Global step value to record
walltime (float): Optional override default walltime (time.time()) of event
global_step 可以认为是作图后的横坐标,每次迭代或每个epoch记录数据;
tag_scalar_dict则是需要被观察的数据,参数是一个dict,key是数据标签,value是数据值。
事实上,add_scalars作用是记录数据随着横坐标(迭代次数等)的变化情况。
我是在训练阶段进行数据记录的,训练结束后,执行:
tensorboard --logdir ./log --port 9999
然后在浏览器打开host:port就可以看到可视化结果了。
到这里,我的结果都很正常
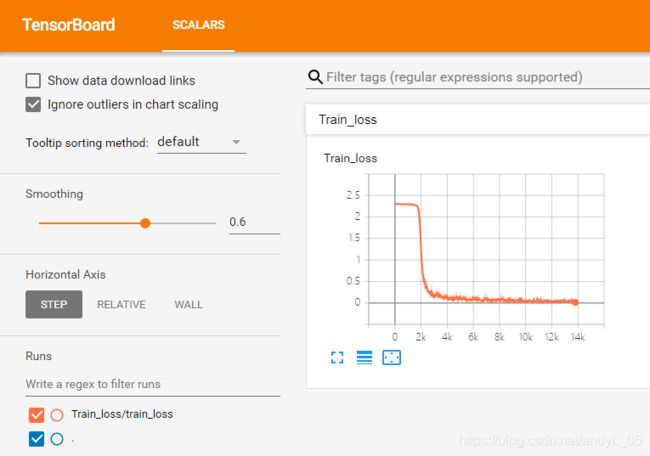
嗯很满意,接下来我想看一下我的网络结构,于是我加入:
dummyInput = torch.rand(1, 1, 28, 28).to(device)
with writer:
writer.add_graph(model,(dummyInput,))
这里第一个参数就是需要被可视化的网络模型,后面是一个元组形式的模拟输入,除了batch_size其他的维度要与网络真实输入一致。
然而,就出现了这样的错误:

此时我发现调用的位置是在to(device)后,那不如我不用cuda了,于是就变成了:

翻山越岭找到这个profile类的init方法

还真没有这个record_shapes参数。
根据我多年 没几年 的 写bug 调bug经验,嗯,应该是版本问题。于是来到pypi的tensorboardX页面

确实,在1.8版本开始逐步对add_graph方法的实现进行了优化和改进,虽说按照他的说法对1.2/1.3的PyTorch支持更好了,但是1.1.0的朋友很难受啊,无奈只好先卸了,装回到tensorboardX 1.7的版本
pip3 install tensorboardX==1.7
然后就可以了,依然是在程序结束后,shell使用tensorboard指令指定log地址、端口号等,打开如下:

点击上面的graph可以看到:

双击这个网络可以显示细节,包括每一层以及层之间传递的张量形状等:

另外,按照大佬们的说法,add_graph一定要在with [SummaryWriter]下进行,目前我也不知道原因。
后续我会尝试一下visdom等可视化工具和大家分享。
2· 关于tensorboardX的使用
这一点很多博客已经讲得很细了,我这里简单说一下吧。
首先就是定义SummaryWriter,接着根据不同需求调用writer的add_*系列函数:
add_scalar或add_scalars就是曲线图形式的数据,一般用来看精度、误差、损失等的变化;
add_graph 显示网络结构与传播细节
add_image 图,可以看中间feature map的结果
add_audio 音频
add_histogram 直方图
add_text 文本
add_pr_curve 精度-回调曲线(precision-recall)
add_embedding 张量
还有很多其他的方法,可以在这里查看。