论文学习笔记 - FCOS
『写在前面』
Anchor-free型检测器的代表作之一。
文章标题:《FCOS: Fully Convolutional One-Stage Object Detection》
作者机构:Zhi Tian等, The University of Adelaide.
论文出处:ICCV 2019
原文链接:https://arxiv.org/abs/1904.01355
相关repo:https://github.com/tianzhi0549/FCOS/
目录
摘要
1 介绍
2 相关工作
Anchor-based检测器
Anchor-free检测器
3 FCOS
3.1 完全卷积One-stage目标检测器
网络输出
Loss函数
推理
3.2 基于FPN的多级预测
网络设计部分
具体怎么做
3.3 FCOS的Centerness分支
4 实验
4.1 分解研究
BPR问题
歧义样本
关于中心度分支
4.2 与SOTA模型的对比
摘要
FCOS以一种类似语义分割的方式,按像素进行预测,解决目标检测问题。
anchor free & proposal free
FCOS 避免了与anchor有关的复杂计算,同时避免了相关的超参数设置,在仅保留NMS后处理步骤的情况下,超越了先前的单阶段检测器。
1 介绍
人们普遍认为,是anchor的使用促成了检测器的成功。但是引入anchor带来了以下几个缺点:
(1)检测器性能受anchor的大小、比例和数量影响较大;
(2)即使精心设计,但由于比例固定,影响了其泛化能力;
(3)为了提高recall,往往密集地设置anchor,这在训练过程中会导致负样本比例严重高于正样本,样本不平衡问题凸显;
(4) anchor的使用还设计IoU计算。
2 相关工作
Anchor-based检测器
Anchor在Faster RCNN中的RPN部分,以及在SSD,YOLOv2中等得到了广泛的应用。
Anchor-free检测器
最流行的anchor-free型检测器当属YOLOv1,在YOLOv1中,通过使用目标中心附近的点来预测包围框。而与其对比,FCOS利用了GT包围框中所有点的信息来预测包围框,并且通过center-ness分支来抑制低质量的检测框。
3 FCOS
3.1 完全卷积One-stage目标检测器
与Anchor-based模型相比,FCOS直接将位置视为训练样本,而不是Anchor box。对一个位置(x,y),如果其落在了任何一个GT框中,则可将其视为一个正样本,同时它的类别就是框的类别;反之,如果它是一个负样本,则其类别为0。因此,FCOS可以利用尽可能多的前景样本点去训练回归器,这与ANCHOR BASED模型不同,该类模型一般只会将与GT框IOU较高的anchor box作为正样本。
进一步地,FCOS对每个location预测一个4维向量,分别对应该处距离其所属包围框各边的距离。
当一个位置属于多个GT包围框时,它就成为一个有歧义的样本。但是这样的情况通过FCOS提出的多级预测(下文详述)可以显著减少,几乎不会影响检测性能。
网络输出
FCOS网络最后的输出层包含(4+C)个通道,分别对应预测C个类别得分及4维包围框参数。
Follow RetinaNet,训练C个二分类分类器,而不是训练一个多类别分类器。与RetinaNet相似,在backbone后添加两个4*conv层分支,分别用来进行分类与回归。此外,因回归分支target>0,故在网络输出上做exp(·).
需要注意的是,与遵循常规设置的RetinaNet(在每个location设置9个anchor box)相比,FCOS的输出数量小了9倍。
Loss函数

其中,Lcls使用focal loss,Lreg使用GIoU loss。λ用来平衡权重。只有正样本处计算回归损失。
推理
FCOS的推理思路很直接,直接统计输出feature map上各个location的得分,选取得分高于阈值(如>0.05)的部分进一步读取其包围框信息即可。
3.2 基于FPN的多级预测
根据3.1中对FCOS模型的介绍,我们可以直接感受到这种设计思路存在的2个BUG:
(1)大的输出stride导致比较低的BPR;
(2)对于重叠的GT框,在重叠部分存在歧义,到底认为该处该对哪个框进行预测?
解决方法:基于FPN的多级预测
网络设计部分
同RetinaNet中FPN部分,使用![]() 共5个feature map进行预测,分别对应stride为8,16,32,64和128.
共5个feature map进行预测,分别对应stride为8,16,32,64和128.
此外,还像RetinaNet一样,在多个特征级别上共享检测头,这样做不仅使得检测器的参数更有效,同时改善了检测性能。但在FCOS中,因为不同的特征级别需要回归不同范围的size,所以都用同样的头结构是不合理的。作者对exp()的基数添加了一个可训练的参数s,对各个特征级别做自适应缩放。
具体怎么做
在anchor based类检测模型中,会对不同级别的feature map分配不同大小的anchor box. 而在FCOS中,我们直接限制不同级别的feature map负责预测的box尺寸范围。
具体来说,首先计算所有每个级别的feature map上,各个位置负责回归的box的4个参数,如果4个参数的最大值不在该level
负责回归的范围内,则把它当做负样本。具体各个feature map负责预测的目标尺寸范围如下表所示。
| Feature Map Level | Stride | Distance Range |
|---|---|---|
| P3 | 8 | 0~64 |
| P4 | 16 | 64~128 |
| P5 | 32 | 128~256 |
| P6 | 64 | 256~512 |
| P7 | 128 | >512 |
因为大多数的重叠情况发生在大小明显不同的对象之间,所以通过上述方法可以区别开它们。但假如两个对象大小相似,没能区分开,FCOS的策略是选择面积较小的那一个GT框来作为目标即可。
试验结果表明,多级预测的方式可以大大减轻重叠框带来的歧义,并将基于FCN的检测器提高到鱼基于Anchor的检测器相同的水平。
3.3 FCOS的Centerness分支
因为FCOS会使用GT框内所有的点作为正样本,所以一个不良后果是会在远离对象中心的位置产生很多低质量的预测框。因此,FCOS提出了Centerness分支,通过设置一个与分类分支平行的单层分支(实际上,在最新版的FCOS中,中心度分支被设计成与回归分支平行),来预测当前位置的“中心度”。“中心度”被定义为当前位置距离其负责的GT框中心的归一化距离,其计算方法如下所示。
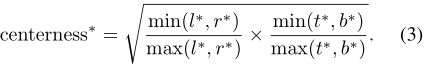
中心度取值范围0~1,通过BCE loss进行训练。在推理阶段,通过将预测的中心度乘上相应的分类得分来进行排序。因此,可以有效降低远离对象中心的边界框的分数,进而又后续的NMS步骤将这些框剔除掉。
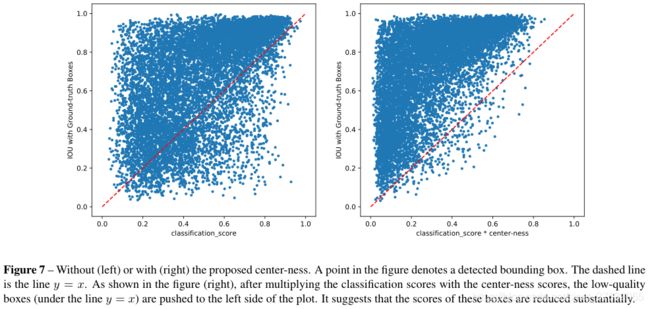
从上图可以看出,左图是不做中心度分支加权前,框得分与IoU的分布情况,可以看到很零散。而右图乘上中心度以后,会将预测结果向左上角迁移,也就意味着修正后的得分越高,相应的该框与GT框的重合程度越高,也就说明预测结果更佳。
中心度分支还有一种选择是仅使用GT框的中心部分作为正样本,同时引入一个额外的超参数对代价进行建模。FCOS-Plus中使用了这样的策略,事实证明上述两种方法的组合使用会得到更好的性能。
4 实验
4.1 分解研究
BPR问题
通过使用基于FPN的多级预测可以达到98.40%,虽然与RetinaNet的99.23%相比仍低1个点,但是因为现有的检测器的best recall远低于90%,所以影响不大。
歧义样本
继续思考因为重叠引起的样本歧义问题,其实如果是同类别的样本存在重叠是不会产生歧义的,因为重叠的部分不论分配给哪个对象,都不会学习错误类别,而两框不重叠的部分会负责预测漏掉的样本。所以只考虑不同类别存在重叠的情况,通过FPN多级预测的方式,可以将有歧义的样本数量降低至3.75%. 而且这部分有歧义的样本还可以通过仅输入它的那些location去预测,所以影响也不大。
关于中心度分支
中心度分支是使得FCOS超越RetinaNet的关键。
同时使用阈值+中心度分支的方式可以得到更好的性能。
使用直接回归向量的方式来计算中心度效果不佳。
4.2 与SOTA模型的对比
