Detectron研读和实践二:getting _started例子faster_rcnn_R-50-FPN
版权声明:本文为博主原创文章,未经博主允许不得转载。
关于Detectron的介绍可以参看我的上一篇博客。此篇博客主要是对Detectron的getting_started例子faster_rcnn_R-50-FPN模型的相关代码进行分析。
1.相关原理简介
该模型主要涉及两个网络模块:基于ResNet50的FPN特征提取网络和Faster R-CNN目标检测网络。实际上,该模型是对Feature Pyramid Networks for Object Detection这篇论文的实现。
1.1 FPN特征提取网络
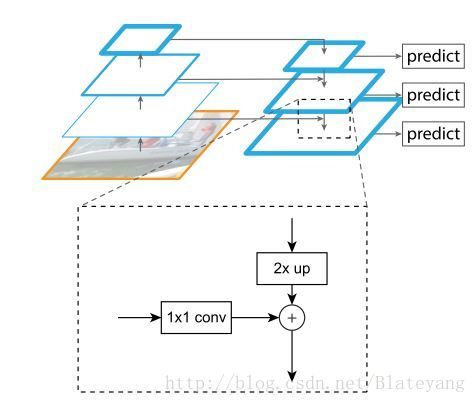
上图为FPN网络的示意图,FPN网络利用深度卷积神经网络固有的多尺度金字塔结构构建特征金字塔。具体来说,就是将卷积网络最高层的特征图进行上采样(将尺寸进行2x放大)然后与卷积网络次高层经过1*1卷积后的特征图进行相加(横向连接),形成特征金字塔网络的一层。按照此操作自顶向下的逐层构建特征金字塔的各层。特征金字塔网络的预测是在各层分别进行的。
FPN将分辨率低但语义强的上层特征和语义弱但分辨率高的下层特征通过自顶向下的通路和横向连接结合起来,使得网络的检测性能有了很大的提升。
关于FPN的详细介绍可以阅读原论文和FPN(feature pyramid networks)算法讲解这篇博客。
1.2 Faster R-CNN检测网络
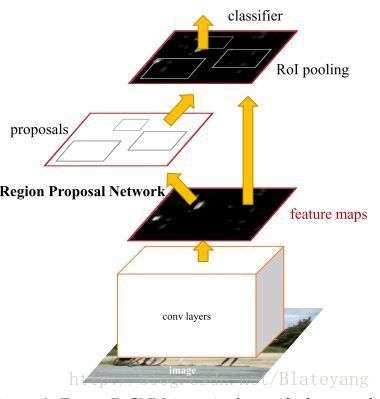
上图为Faster R-CNN的网络结构(预测阶段),首先利用特征提取网络提取特征图,然后给RPN网络进行处理生成可能包含目标区域的proposals,后面的Fast R-CNN分类器对proposals进行RoI pooling后进行分类和bbox的回归。
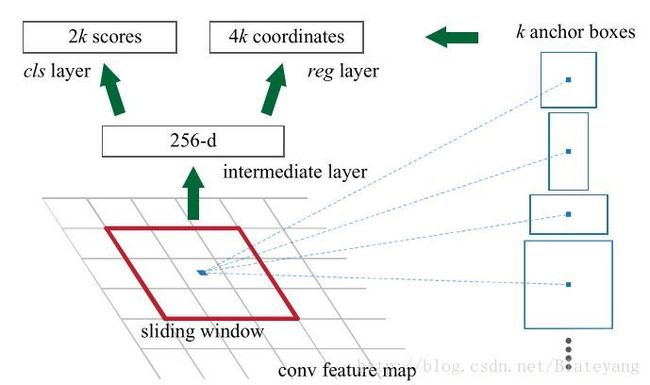
RPN是Faster R-CNN最为关键的部分,因为说白了,Faster R-CNN就是在Fast R-CNN的基础上加了一个RPN进去。RPN是一个能够在每个位置同时预测目标边界框和属于目标得分的全卷积网络。它通过端到端训练能产生高质量的区域提名,这些区域提名被其后的Fast R-CNN用来做检测。由于本文的重点不在分析相关原理,因此下面只把RPN的网络结构贴出来,有关的详细介绍可以阅读原论文或是去网上搜解读Faster R-CNN的博客。
2.相关源码分析
2.1 train_net.py
train_net.py位于tools文件夹下,是detectron用来训练网络的文件。
主程序流程图如下:
模型训练的流程图如下:
下面是该文件主要程序段的摘录,在作者的注释基础上补充了一些注释。
"""Train a network with Detectron."""
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
from __future__ import unicode_literals
import argparse
import cv2 # NOQA (Must import before importing caffe2 due to bug in cv2)
import logging
import numpy as np
import os
import pprint
import re
import sys
import test_net
from caffe2.python import memonger
from caffe2.python import workspace
from core.config import assert_and_infer_cfg
from core.config import cfg
from core.config import get_output_dir
from core.config import merge_cfg_from_file
from core.config import merge_cfg_from_list
from datasets.roidb import combined_roidb_for_training
from modeling import model_builder
from utils import lr_policy
from utils.logging import setup_logging
from utils.training_stats import TrainingStats
import utils.c2
import utils.env as envu
import utils.net as nu
utils.c2.import_contrib_ops()
utils.c2.import_detectron_ops()
# OpenCL may be enabled by default in OpenCV3; disable it because it's not
# thread safe and causes unwanted GPU memory allocations.
cv2.ocl.setUseOpenCL(False)
def parse_args():
parser = argparse.ArgumentParser(
description='Train a network with Detectron'
)
parser.add_argument(
'--cfg',
dest='cfg_file',
help='Config file for training (and optionally testing)',
default=None,
type=str
)
parser.add_argument(
'--multi-gpu-testing',
dest='multi_gpu_testing',
help='Use cfg.NUM_GPUS GPUs for inference',
action='store_true'
)
parser.add_argument(
'--skip-test',
dest='skip_test',
help='Do not test the final model',
action='store_true'
)
parser.add_argument(
'opts',
help='See lib/core/config.py for all options',
default=None,
nargs=argparse.REMAINDER
)
if len(sys.argv) == 1:
parser.print_help()
sys.exit(1)
return parser.parse_args()
def main():
# Initialize C2
workspace.GlobalInit(
['caffe2', '--caffe2_log_level=0', '--caffe2_gpu_memory_tracking=1']
)
# Set up logging and load config options
logger = setup_logging(__name__)
logging.getLogger('roi_data.loader').setLevel(logging.INFO)
args = parse_args()
logger.info('Called with args:')
logger.info(args)
if args.cfg_file is not None:
merge_cfg_from_file(args.cfg_file)
if args.opts is not None:
merge_cfg_from_list(args.opts)
assert_and_infer_cfg()
logger.info('Training with config:')
logger.info(pprint.pformat(cfg))
# Note that while we set the numpy random seed network training will not be
# deterministic in general. There are sources of non-determinism that cannot
# be removed with a reasonble execution-speed tradeoff (such as certain
# non-deterministic cudnn functions).
np.random.seed(cfg.RNG_SEED)
# Execute the training run
checkpoints = train_model()
# Test the trained model
if not args.skip_test:
test_model(checkpoints['final'], args.multi_gpu_testing, args.opts)
def train_model():
"""Model training loop."""
# 模型训练主函数,主要完成模型的创建,迭代训练,相关训练统计数据记录和权重文件的定期及最终输出
logger = logging.getLogger(__name__)
model, start_iter, checkpoints, output_dir = create_model()
if 'final' in checkpoints:
# The final model was found in the output directory, so nothing to do
return checkpoints
setup_model_for_training(model, output_dir)
training_stats = TrainingStats(model) # 追踪一些关键的训练统计数据
CHECKPOINT_PERIOD = int(cfg.TRAIN.SNAPSHOT_ITERS / cfg.NUM_GPUS)
for cur_iter in range(start_iter, cfg.SOLVER.MAX_ITER):
training_stats.IterTic()
lr = model.UpdateWorkspaceLr(cur_iter, lr_policy.get_lr_at_iter(cur_iter))
workspace.RunNet(model.net.Proto().name)
if cur_iter == start_iter:
nu.print_net(model)
training_stats.IterToc()
training_stats.UpdateIterStats()
training_stats.LogIterStats(cur_iter, lr)
if (cur_iter + 1) % CHECKPOINT_PERIOD == 0 and cur_iter > start_iter:
checkpoints[cur_iter] = os.path.join(
output_dir, 'model_iter{}.pkl'.format(cur_iter)
)
nu.save_model_to_weights_file(checkpoints[cur_iter], model)
if cur_iter == start_iter + training_stats.LOG_PERIOD:
# Reset the iteration timer to remove outliers from the first few
# SGD iterations
training_stats.ResetIterTimer()
if np.isnan(training_stats.iter_total_loss):
logger.critical('Loss is NaN, exiting...')
model.roi_data_loader.shutdown()
envu.exit_on_error()
# Save the final model
checkpoints['final'] = os.path.join(output_dir, 'model_final.pkl')
nu.save_model_to_weights_file(checkpoints['final'], model)
# Shutdown data loading threads
model.roi_data_loader.shutdown()
return checkpoints
def create_model():
"""Build the model and look for saved model checkpoints in case we can
resume from one.
"""
# 建立一个模型并寻找已被保存的模型检查点以便可以从检查点处继续,相当于支持断点续训
logger = logging.getLogger(__name__)
start_iter = 0
checkpoints = {}
output_dir = get_output_dir(training=True)
if cfg.TRAIN.AUTO_RESUME:
# Check for the final model (indicates training already finished)
final_path = os.path.join(output_dir, 'model_final.pkl')
if os.path.exists(final_path):
logger.info('model_final.pkl exists; no need to train!')
return None, None, {'final': final_path}, output_dir
# Find the most recent checkpoint (highest iteration number)
files = os.listdir(output_dir)
for f in files:
iter_string = re.findall(r'(?<=model_iter)\d+(?=\.pkl)', f)
if len(iter_string) > 0:
checkpoint_iter = int(iter_string[0])
if checkpoint_iter > start_iter:
# Start one iteration immediately after the checkpoint iter
start_iter = checkpoint_iter + 1
resume_weights_file = f
if start_iter > 0:
# Override the initialization weights with the found checkpoint
cfg.TRAIN.WEIGHTS = os.path.join(output_dir, resume_weights_file)
logger.info(
'========> Resuming from checkpoint {} at start iter {}'.
format(cfg.TRAIN.WEIGHTS, start_iter)
)
logger.info('Building model: {}'.format(cfg.MODEL.TYPE))
# 此处利用model_builder创建yaml配置文件中制定的模型
model = model_builder.create(cfg.MODEL.TYPE, train=True)
if cfg.MEMONGER:
optimize_memory(model)
# Performs random weight initialization as defined by the model
workspace.RunNetOnce(model.param_init_net)
return model, start_iter, checkpoints, output_dir
# 后面还有...2.2 model_builder.py
在2.1创建模型中,该句model = model_builder.create(cfg.MODEL.TYPE, train=True) 用到了lib/modeling文件夹中的model_builder.py文件,它包含有许多Detectron模型构造函数,就像作者在文件开头的注释中写道的:
Detectron supports a large number of model types. The configuration space is
large. To get a sense, a given model is in element in the cartesian product of:
- backbone (e.g., VGG16, ResNet, ResNeXt)
- FPN (on or off)
- RPN only (just proposals)
- Fixed proposals for Fast R-CNN, RFCN, Mask R-CNN (with or without keypoints)
- End-to-end model with RPN + Fast R-CNN (i.e., Faster R-CNN), Mask R-CNN, …
- Different “head” choices for the model
- … many configuration options …
A given model is made by combining many basic components. The result is flexible
though somewhat complex to understand at first.
利用model_builder.create()函数创建faster_rcnn_R-50-FPN模型的流程图如下:
这里贴出几个重要函数,通过注释进行分析。
# ---------------------------------------------------------------------------- #
# Generic recomposable model builders
#
# For example, you can create a Fast R-CNN model with the ResNet-50-C4 backbone
# with the configuration:
#
# MODEL:
# TYPE: generalized_rcnn
# CONV_BODY: ResNet.add_ResNet50_conv4_body
# ROI_HEAD: ResNet.add_ResNet_roi_conv5_head
# ---------------------------------------------------------------------------- #
def generalized_rcnn(model):
"""This model type handles:
- Fast R-CNN
- RPN only (not integrated with Fast R-CNN)
- Faster R-CNN (stagewise training from NIPS paper)
- Faster R-CNN (end-to-end joint training)
- Mask R-CNN (stagewise training from NIPS paper)
- Mask R-CNN (end-to-end joint training)
"""
return build_generic_detection_model(
model,
get_func(cfg.MODEL.CONV_BODY),
add_roi_box_head_func=get_func(cfg.FAST_RCNN.ROI_BOX_HEAD),
add_roi_mask_head_func=get_func(cfg.MRCNN.ROI_MASK_HEAD),
add_roi_keypoint_head_func=get_func(cfg.KRCNN.ROI_KEYPOINTS_HEAD),
freeze_conv_body=cfg.TRAIN.FREEZE_CONV_BODY
)
def rfcn(model):
# TODO(rbg): fold into build_generic_detection_model
return build_generic_rfcn_model(model, get_func(cfg.MODEL.CONV_BODY))
def retinanet(model):
# TODO(rbg): fold into build_generic_detection_model
return build_generic_retinanet_model(model, get_func(cfg.MODEL.CONV_BODY))
# ---------------------------------------------------------------------------- #
# Helper functions for building various re-usable network bits
# ---------------------------------------------------------------------------- #
def create(model_type_func, train=False, gpu_id=0):
"""Generic model creation function that dispatches to specific model
building functions.
By default, this function will generate a data parallel model configured to
run on cfg.NUM_GPUS devices. However, you can restrict it to build a model
targeted to a specific GPU by specifying gpu_id. This is used by
optimizer.build_data_parallel_model() during test time.
"""
model = DetectionModelHelper(
name=model_type_func,
train=train,
num_classes=cfg.MODEL.NUM_CLASSES,
init_params=train
)
model.only_build_forward_pass = False
model.target_gpu_id = gpu_id
# 先调用get_func函数返回model_type_func指定的(generalized_rcnn)模型函数对象
return get_func(model_type_func)(model)
def get_func(func_name):
"""Helper to return a function object by name. func_name must identify a
function in this module or the path to a function relative to the base
'modeling' module.
"""
if func_name == '':
return None
new_func_name = modeling.name_compat.get_new_name(func_name)
# 若在配置文件中指定的模型TYPE与经处理后的new_func_name不符,如TYPE是在本文件420多行列出的
# 弃用函数名rpn,fast-rcnn,faster-rcnn等,则换成统一的新名字,generalized_rcnn
if new_func_name != func_name:
logger.warn(
'Remapping old function name: {} -> {}'.
format(func_name, new_func_name)
)
func_name = new_func_name
# 尝试在当前module寻找func_name(不带.),若失败,则在modeling目录下寻找,
# 并返回对应的函数对象
try:
parts = func_name.split('.')
# Refers to a function in this module
if len(parts) == 1:
return globals()[parts[0]]
# Otherwise, assume we're referencing a module under modeling
module_name = 'modeling.' + '.'.join(parts[:-1])
module = importlib.import_module(module_name)
# 等价于module.parts[-1],如FPN.add_fpn_ResNet50_conv5_body
return getattr(module, parts[-1])
except Exception:
logger.error('Failed to find function: {}'.format(func_name))
raise
# 通过配置参数和接口函数_add_xxx_head等,将backbone,RPN,FPN,Fast R-CNN,Mask head,
# keypoint head等模块组合起来,构建一个通用检测模型
def build_generic_detection_model(
model,
add_conv_body_func,
add_roi_box_head_func=None,
add_roi_mask_head_func=None,
add_roi_keypoint_head_func=None,
freeze_conv_body=False
):
def _single_gpu_build_func(model):
"""Build the model on a single GPU. Can be called in a loop over GPUs
with name and device scoping to create a data parallel model.
"""
# Add the conv body (called "backbone architecture" in papers)
# E.g., ResNet-50, ResNet-50-FPN, ResNeXt-101-FPN, etc.
# add_conv_body_func=get_func(cfg.MODEL.CONV_BODY)
blob_conv, dim_conv, spatial_scale_conv = add_conv_body_func(model)
if freeze_conv_body:
for b in c2_utils.BlobReferenceList(blob_conv):
model.StopGradient(b, b)
if not model.train: # == inference
# Create a net that can be used to execute the conv body on an image
# (without also executing RPN or any other network heads)
model.conv_body_net = model.net.Clone('conv_body_net')
head_loss_gradients = {
'rpn': None,
'box': None,
'mask': None,
'keypoints': None,
}
if cfg.RPN.RPN_ON:
# Add the RPN head
head_loss_gradients['rpn'] = rpn_heads.add_generic_rpn_outputs(
model, blob_conv, dim_conv, spatial_scale_conv
)
if cfg.FPN.FPN_ON:
# After adding the RPN head, restrict FPN blobs and scales to
# those used in the RoI heads
blob_conv, spatial_scale_conv = _narrow_to_fpn_roi_levels(
blob_conv, spatial_scale_conv
)
if not cfg.MODEL.RPN_ONLY:
# Add the Fast R-CNN head
head_loss_gradients['box'] = _add_fast_rcnn_head(
model, add_roi_box_head_func, blob_conv, dim_conv,
spatial_scale_conv
)
if cfg.MODEL.MASK_ON:
# Add the mask head
head_loss_gradients['mask'] = _add_roi_mask_head(
model, add_roi_mask_head_func, blob_conv, dim_conv,
spatial_scale_conv
)
if cfg.MODEL.KEYPOINTS_ON:
# Add the keypoint head
head_loss_gradients['keypoint'] = _add_roi_keypoint_head(
model, add_roi_keypoint_head_func, blob_conv, dim_conv,
spatial_scale_conv
)
if model.train:
loss_gradients = {}
for lg in head_loss_gradients.values():
if lg is not None:
loss_gradients.update(lg)
return loss_gradients
else:
return None
optim.build_data_parallel_model(model, _single_gpu_build_func)
return model
# 后面还有...
2.3 FPN.py
承接上面_single_gpu_build_func函数中的
blob_conv, dim_conv, spatial_scale_conv = add_conv_body_func(model) # add_conv_body_func=get_func(cfg.MODEL.CONV_BODY)由于cfg.MODEL.CONV_BODY在配置文件中被设置为FPN.add_fpn_ResNet50_conv_body,因此下面来分析modeling/FPN.py文件。
该部分涉及到的相关程序流程(即FPN.add_fpn_ResNet50_conv_body(model)函数)如下:
主要代码分析:
"""Functions for using a Feature Pyramid Network (FPN)."""
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
from __future__ import unicode_literals
import collections
import numpy as np
from core.config import cfg
from modeling.generate_anchors import generate_anchors
from utils.c2 import const_fill
from utils.c2 import gauss_fill
import modeling.ResNet as ResNet
import utils.blob as blob_utils
import utils.boxes as box_utils
# Lowest and highest pyramid levels in the backbone network. For FPN, we assume
# that all networks have 5 spatial reductions, each by a factor of 2. Level 1
# would correspond to the input image, hence it does not make sense to use it.
LOWEST_BACKBONE_LVL = 2 # E.g., "conv2"-like level
HIGHEST_BACKBONE_LVL = 5 # E.g., "conv5"-like level
# ---------------------------------------------------------------------------- #
# FPN with ResNet
# ---------------------------------------------------------------------------- #
def add_fpn_ResNet50_conv5_body(model): #利用ResNet50_conv5_body构建fpn网络
return add_fpn_onto_conv_body(
model, ResNet.add_ResNet50_conv5_body, fpn_level_info_ResNet50_conv5
)
def add_fpn_ResNet50_conv5_P2only_body(model):
return add_fpn_onto_conv_body(
model,
ResNet.add_ResNet50_conv5_body,
fpn_level_info_ResNet50_conv5,
P2only=True
)
# 此处省略add_fpn_ResNet101和add_fpn_ResNet152相关的conv_body函数
# ---------------------------------------------------------------------------- #
# Functions for bolting FPN onto a backbone architectures
# ---------------------------------------------------------------------------- #
def add_fpn_onto_conv_body(
model, conv_body_func, fpn_level_info_func, P2only=False
):
"""Add the specified conv body to the model and then add FPN levels to it.
"""
# Note: blobs_conv is in revsersed order: [fpn5, fpn4, fpn3, fpn2]
# similarly for dims_conv: [2048, 1024, 512, 256]
# similarly for spatial_scales_fpn: [1/32, 1/16, 1/8, 1/4]
conv_body_func(model)
blobs_fpn, dim_fpn, spatial_scales_fpn = add_fpn(
model, fpn_level_info_func()
)
if P2only: # P2指FPN论文中conv2层对应的FPN输出
# use only the finest level
return blobs_fpn[-1], dim_fpn, spatial_scales_fpn[-1]
else:
# use all levels
return blobs_fpn, dim_fpn, spatial_scales_fpn
def add_fpn(model, fpn_level_info):
"""Add FPN connections based on the model described in the FPN paper."""
# FPN levels are built starting from the highest/coarest level of the
# backbone (usually "conv5"). First we build down, recursively constructing
# lower/finer resolution FPN levels. Then we build up, constructing levels
# that are even higher/coarser than the starting level.
# 从backbone的最高层(一般为conv5)开始,先向下递归地建立FPN(P5,P4,P3,...),
# 然后回到开始的level(conv5),向上建立更高层的level(如P6),该函数会返回各层的blob
fpn_dim = cfg.FPN.DIM
min_level, max_level = get_min_max_levels()
# Count the number of backbone stages that we will generate FPN levels for
# starting from the coarest backbone stage (usually the "conv5"-like level)
# E.g., if the backbone level info defines stages 4 stages: "conv5",
# "conv4", ... "conv2" and min_level=2, then we end up with 4 - (2 - 2) = 4
# backbone stages to add FPN to.
# 可以想象成总共有len(fpn_level_info.blobs)层堆栈,LOWEST_BACKBONE_LVL
# 代表最低层编号,min_level代表人为要取的最低层编号
num_backbone_stages = (
len(fpn_level_info.blobs) - (min_level - LOWEST_BACKBONE_LVL)
)
lateral_input_blobs = fpn_level_info.blobs[:num_backbone_stages]
output_blobs = [
'fpn_inner_{}'.format(s)
for s in fpn_level_info.blobs[:num_backbone_stages]
]
fpn_dim_lateral = fpn_level_info.dims
xavier_fill = ('XavierFill', {})
# For the coarest backbone level: 1x1 conv only seeds recursion
model.Conv(
lateral_input_blobs[0],
output_blobs[0],
dim_in=fpn_dim_lateral[0],
dim_out=fpn_dim,
kernel=1,
pad=0,
stride=1,
weight_init=xavier_fill,
bias_init=const_fill(0.0)
)
#
# Step 1: recursively build down starting from the coarsest backbone level
#
# For other levels add top-down and lateral connections
for i in range(num_backbone_stages - 1):
add_topdown_lateral_module(
model,
output_blobs[i], # top-down blob
lateral_input_blobs[i + 1], # lateral blob
output_blobs[i + 1], # next output blob
fpn_dim, # output dimension
fpn_dim_lateral[i + 1] # lateral input dimension
)
# Post-hoc(事后,因果颠倒) scale-specific 3x3 convs
# 接着又从下往上对横向连接输出后的blob进行3*3卷积,
# 将结果依次存入blobs_fpn列表中
blobs_fpn = []
spatial_scales = []
for i in range(num_backbone_stages):
fpn_blob = model.Conv(
output_blobs[i],
'fpn_{}'.format(fpn_level_info.blobs[i]),
dim_in=fpn_dim,
dim_out=fpn_dim,
kernel=3,
pad=1,
stride=1,
weight_init=xavier_fill,
bias_init=const_fill(0.0)
)
blobs_fpn += [fpn_blob]
spatial_scales += [fpn_level_info.spatial_scales[i]]
#
# Step 2: build up starting from the coarsest backbone level
#
# Check if we need the P6 feature map
if not cfg.FPN.EXTRA_CONV_LEVELS and max_level == HIGHEST_BACKBONE_LVL + 1:
# Original FPN P6 level implementation from our CVPR'17 FPN paper
P6_blob_in = blobs_fpn[0]
P6_name = P6_blob_in + '_subsampled_2x'
# Use max pooling to simulate stride 2 subsampling
P6_blob = model.MaxPool(P6_blob_in, P6_name, kernel=1, pad=0, stride=2)
blobs_fpn.insert(0, P6_blob)
spatial_scales.insert(0, spatial_scales[0] * 0.5)
# Coarser FPN levels introduced for RetinaNet
if cfg.FPN.EXTRA_CONV_LEVELS and max_level > HIGHEST_BACKBONE_LVL:
fpn_blob = fpn_level_info.blobs[0]
dim_in = fpn_level_info.dims[0]
for i in range(HIGHEST_BACKBONE_LVL + 1, max_level + 1):
fpn_blob_in = fpn_blob
if i > HIGHEST_BACKBONE_LVL + 1:
fpn_blob_in = model.Relu(fpn_blob, fpn_blob + '_relu')
fpn_blob = model.Conv(
fpn_blob_in,
'fpn_' + str(i),
dim_in=dim_in,
dim_out=fpn_dim,
kernel=3,
pad=1,
stride=2,
weight_init=xavier_fill,
bias_init=const_fill(0.0)
)
dim_in = fpn_dim
blobs_fpn.insert(0, fpn_blob)
spatial_scales.insert(0, spatial_scales[0] * 0.5)
return blobs_fpn, fpn_dim, spatial_scales
def add_topdown_lateral_module(
model, fpn_top, fpn_lateral, fpn_bottom, dim_top, dim_lateral
):
"""Add a top-down lateral module."""
# Lateral 1x1 conv
lat = model.Conv(
fpn_lateral,
fpn_bottom + '_lateral',
dim_in=dim_lateral,
dim_out=dim_top,
kernel=1,
pad=0,
stride=1,
weight_init=(
const_fill(0.0) if cfg.FPN.ZERO_INIT_LATERAL
else ('XavierFill', {})
),
bias_init=const_fill(0.0)
)
# Top-down 2x upsampling
td = model.net.UpsampleNearest(fpn_top, fpn_bottom + '_topdown', scale=2)
# Sum lateral and top-down
model.net.Sum([lat, td], fpn_bottom)
def get_min_max_levels():
"""The min and max FPN levels required for supporting RPN and/or RoI
transform operations on multiple FPN levels.
"""
min_level = LOWEST_BACKBONE_LVL
max_level = HIGHEST_BACKBONE_LVL
if cfg.FPN.MULTILEVEL_RPN and not cfg.FPN.MULTILEVEL_ROIS:
max_level = cfg.FPN.RPN_MAX_LEVEL
min_level = cfg.FPN.RPN_MIN_LEVEL
if not cfg.FPN.MULTILEVEL_RPN and cfg.FPN.MULTILEVEL_ROIS:
max_level = cfg.FPN.ROI_MAX_LEVEL
min_level = cfg.FPN.ROI_MIN_LEVEL
if cfg.FPN.MULTILEVEL_RPN and cfg.FPN.MULTILEVEL_ROIS:
max_level = max(cfg.FPN.RPN_MAX_LEVEL, cfg.FPN.ROI_MAX_LEVEL)
min_level = min(cfg.FPN.RPN_MIN_LEVEL, cfg.FPN.ROI_MIN_LEVEL)
return min_level, max_level
# ---------------------------------------------------------------------------- #
# RPN with an FPN backbone
# ---------------------------------------------------------------------------- #
# 会被rpn_heads.py中的add_generic_rpn_outputs函数调用
def add_fpn_rpn_outputs(model, blobs_in, dim_in, spatial_scales):
"""Add RPN on FPN specific outputs."""
num_anchors = len(cfg.FPN.RPN_ASPECT_RATIOS) # 三种方向比例[0.5, 1, 2]
dim_out = dim_in
k_max = cfg.FPN.RPN_MAX_LEVEL # coarsest level of pyramid,default is 6
k_min = cfg.FPN.RPN_MIN_LEVEL # finest level of pyramid, default is 2
assert len(blobs_in) == k_max - k_min + 1
for lvl in range(k_min, k_max + 1):
# blobs_in is in reversed order,bl_in starts from blobs_in[4],that is finest level
bl_in = blobs_in[k_max - lvl]
sc = spatial_scales[k_max - lvl] # in reversed order
slvl = str(lvl)
if lvl == k_min:
# Create conv ops with randomly initialized weights and
# zeroed biases for the first FPN level; these will be shared by
# all other FPN levels
# RPN hidden representation
conv_rpn_fpn = model.Conv(
bl_in,
'conv_rpn_fpn' + slvl,
dim_in,
dim_out,
kernel=3,
pad=1,
stride=1,
weight_init=gauss_fill(0.01),
bias_init=const_fill(0.0)
)
model.Relu(conv_rpn_fpn, conv_rpn_fpn)
# Proposal classification scores
rpn_cls_logits_fpn = model.Conv(
conv_rpn_fpn,
'rpn_cls_logits_fpn' + slvl,
dim_in,
num_anchors,
kernel=1,
pad=0,
stride=1,
weight_init=gauss_fill(0.01),
bias_init=const_fill(0.0)
)
# Proposal bbox regression deltas
rpn_bbox_pred_fpn = model.Conv(
conv_rpn_fpn,
'rpn_bbox_pred_fpn' + slvl,
dim_in,
4 * num_anchors,
kernel=1,
pad=0,
stride=1,
weight_init=gauss_fill(0.01),
bias_init=const_fill(0.0)
)
else:
# Share weights and biases
sk_min = str(k_min)
# RPN hidden representation
# ConvShared在detector.py中定义,添加一个与另一conv op共享权值(及偏置)的conv op
conv_rpn_fpn = model.ConvShared(
bl_in,
'conv_rpn_fpn' + slvl,
dim_in,
dim_out,
kernel=3,
pad=1,
stride=1,
weight='conv_rpn_fpn' + sk_min + '_w',
bias='conv_rpn_fpn' + sk_min + '_b'
)
model.Relu(conv_rpn_fpn, conv_rpn_fpn)
# Proposal classification scores
rpn_cls_logits_fpn = model.ConvShared(
conv_rpn_fpn,
'rpn_cls_logits_fpn' + slvl,
dim_in,
num_anchors,
kernel=1,
pad=0,
stride=1,
weight='rpn_cls_logits_fpn' + sk_min + '_w',
bias='rpn_cls_logits_fpn' + sk_min + '_b'
)
# Proposal bbox regression deltas
rpn_bbox_pred_fpn = model.ConvShared(
conv_rpn_fpn,
'rpn_bbox_pred_fpn' + slvl,
dim_in,
4 * num_anchors,
kernel=1,
pad=0,
stride=1,
weight='rpn_bbox_pred_fpn' + sk_min + '_w',
bias='rpn_bbox_pred_fpn' + sk_min + '_b'
)
if not model.train or cfg.MODEL.FASTER_RCNN:
# Proposals are needed during:
# 1) inference (== not model.train) for RPN only and Faster R-CNN
# OR
# 2) training for Faster R-CNN
# Otherwise (== training for RPN only), proposals are not needed
lvl_anchors = generate_anchors(
stride=2.**lvl,
sizes=(cfg.FPN.RPN_ANCHOR_START_SIZE * 2.**(lvl - k_min), ),
aspect_ratios=cfg.FPN.RPN_ASPECT_RATIOS
)
rpn_cls_probs_fpn = model.net.Sigmoid(
rpn_cls_logits_fpn, 'rpn_cls_probs_fpn' + slvl
)
model.GenerateProposals( # 在detector.py中定义,将rpn输出的anchors转换成rois
[rpn_cls_probs_fpn, rpn_bbox_pred_fpn, 'im_info'],
['rpn_rois_fpn' + slvl, 'rpn_roi_probs_fpn' + slvl],
anchors=lvl_anchors,
spatial_scale=sc
)
# 同上,也会被rpn_heads.py中的add_generic_rpn_outputs函数调用
def add_fpn_rpn_losses(model):
"""Add RPN on FPN specific losses."""
loss_gradients = {}
for lvl in range(cfg.FPN.RPN_MIN_LEVEL, cfg.FPN.RPN_MAX_LEVEL + 1):
slvl = str(lvl)
# Spatially narrow the full-sized RPN label arrays to match the feature map shape
# Reduces ("narrows") the spatial extent of A to that of B
# by removing rows and columns from the bottom and right.
model.net.SpatialNarrowAs(
['rpn_labels_int32_wide_fpn' + slvl, 'rpn_cls_logits_fpn' + slvl],
'rpn_labels_int32_fpn' + slvl
)
for key in ('targets', 'inside_weights', 'outside_weights'):
model.net.SpatialNarrowAs(
[
'rpn_bbox_' + key + '_wide_fpn' + slvl,
'rpn_bbox_pred_fpn' + slvl
],
'rpn_bbox_' + key + '_fpn' + slvl
)
loss_rpn_cls_fpn = model.net.SigmoidCrossEntropyLoss(
['rpn_cls_logits_fpn' + slvl, 'rpn_labels_int32_fpn' + slvl],
'loss_rpn_cls_fpn' + slvl,
normalize=0,
scale=(
model.GetLossScale() / cfg.TRAIN.RPN_BATCH_SIZE_PER_IM /
cfg.TRAIN.IMS_PER_BATCH
)
)
# Normalization by (1) RPN_BATCH_SIZE_PER_IM and (2) IMS_PER_BATCH is
# handled by (1) setting bbox outside weights and (2) SmoothL1Loss
# normalizes by IMS_PER_BATCH
loss_rpn_bbox_fpn = model.net.SmoothL1Loss(
[
'rpn_bbox_pred_fpn' + slvl, 'rpn_bbox_targets_fpn' + slvl,
'rpn_bbox_inside_weights_fpn' + slvl,
'rpn_bbox_outside_weights_fpn' + slvl
], #inside_weights即frcnn原论文RPN损失函数中的前背景指示量;
#outside_weights可以认为是样本损失权重,详见detectron/smooth_l1_loss_op.cc的说明文档
'loss_rpn_bbox_fpn' + slvl,
beta=1. / 9., #SmoothL1Loss函数中的一个参数,控制从L2损失到L1损失的过渡点
scale=model.GetLossScale(),
)
loss_gradients.update(
blob_utils.
get_loss_gradients(model, [loss_rpn_cls_fpn, loss_rpn_bbox_fpn])
)
model.AddLosses(['loss_rpn_cls_fpn' + slvl, 'loss_rpn_bbox_fpn' + slvl])
return loss_gradients
2.4 ResNet.py
在FPN.py的add_fpn_ResNet50_conv5_body(model)函数中涉及到了利用ResNet.add_ResNet50_conv5_body函数构建ResNet50特征提取网络,下面来分析一下该函数涉及到的ResNet.py文件。
该文件主要是对ResNet和ResNext的实现,ResNet的网络结构表如下:
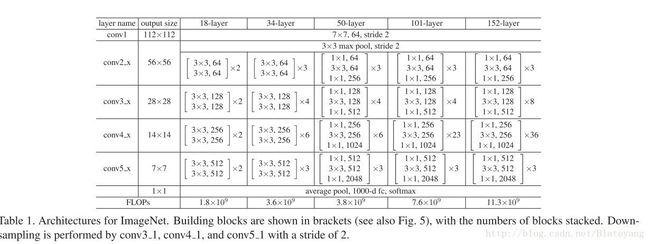
ResNext与ResNet的区别在于ResNext在ResNet的基础上使用了分组卷积的思想。
ResNet.add_ResNet50_conv5_body的程序流程图如下:
下面是源程序的相关代码:
""Implements ResNet and ResNeXt.
See: https://arxiv.org/abs/1512.03385, https://arxiv.org/abs/1611.05431.
"""
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
from __future__ import unicode_literals
from core.config import cfg
# ---------------------------------------------------------------------------- #
# Bits for specific architectures (ResNet50, ResNet101, ...)
# ---------------------------------------------------------------------------- #
def add_ResNet50_conv4_body(model):
return add_ResNet_convX_body(model, (3, 4, 6))
def add_ResNet50_conv5_body(model):
return add_ResNet_convX_body(model, (3, 4, 6, 3))
def add_ResNet101_conv4_body(model):
return add_ResNet_convX_body(model, (3, 4, 23))
def add_ResNet101_conv5_body(model):
return add_ResNet_convX_body(model, (3, 4, 23, 3))
def add_ResNet152_conv5_body(model):
return add_ResNet_convX_body(model, (3, 8, 36, 3))
# ---------------------------------------------------------------------------- #
# Generic ResNet components
# ---------------------------------------------------------------------------- #
def add_stage(
model,
prefix,
blob_in,
n,
dim_in,
dim_out,
dim_inner,
dilation, # 相当于padding参数
stride_init=2
):
"""Add a ResNet stage to the model by stacking n residual blocks."""
# e.g., prefix = res2
for i in range(n):
blob_in = add_residual_block(
model,
'{}_{}'.format(prefix, i),
blob_in,
dim_in,
dim_out,
dim_inner,
dilation,
stride_init,
# Not using inplace for the last block;
# it may be fetched externally or used by FPN
inplace_sum=i < n - 1
)
dim_in = dim_out
return blob_in, dim_in
def add_ResNet_convX_body(model, block_counts, freeze_at=2):
"""Add a ResNet body from input data up through the res5 (aka conv5) stage.
The final res5/conv5 stage may be optionally excluded (hence convX, where
X = 4 or 5)."""
assert freeze_at in [0, 2, 3, 4, 5]
p = model.Conv('data', 'conv1', 3, 64, 7, pad=3, stride=2, no_bias=1)
# Applies a separate affine transformation to each channel of the input.
# Useful for replacing spatial batch norm with its equivalent fixed transformation.
# 感觉AffineChannel这个函数起到batch normalization的作用
p = model.AffineChannel(p, 'res_conv1_bn', dim=64, inplace=True)
p = model.Relu(p, p)
p = model.MaxPool(p, 'pool1', kernel=3, pad=1, stride=2)
dim_in = 64
# 在cfg文件中,NUM_GROUPS用于设置卷积组数,RESNET为1,RESNXT大于1;WIDTH_PER_GROUP为64
dim_bottleneck = cfg.RESNETS.NUM_GROUPS * cfg.RESNETS.WIDTH_PER_GROUP
(n1, n2, n3) = block_counts[:3]
# 通过堆叠n1个residual blocks来给model添加一个ResNet的卷积块
s, dim_in = add_stage(model, 'res2', p, n1, dim_in, 256, dim_bottleneck, 1)
if freeze_at == 2:
model.StopGradient(s, s) # 停止该ResNet卷积块的梯度更新
s, dim_in = add_stage(
model, 'res3', s, n2, dim_in, 512, dim_bottleneck * 2, 1
)
if freeze_at == 3:
model.StopGradient(s, s)
s, dim_in = add_stage(
model, 'res4', s, n3, dim_in, 1024, dim_bottleneck * 4, 1
)
if freeze_at == 4:
model.StopGradient(s, s)
if len(block_counts) == 4:
n4 = block_counts[3]
s, dim_in = add_stage(
model, 'res5', s, n4, dim_in, 2048, dim_bottleneck * 8,
cfg.RESNETS.RES5_DILATION
)
if freeze_at == 5:
model.StopGradient(s, s)
return s, dim_in, 1. / 32. * cfg.RESNETS.RES5_DILATION
else:
return s, dim_in, 1. / 16.
def add_ResNet_roi_conv5_head(model, blob_in, dim_in, spatial_scale):
"""Adds an RoI feature transformation (e.g., RoI pooling) followed by a
res5/conv5 head applied to each RoI."""
# TODO(rbg): This contains Fast R-CNN specific config options making it non-
# reusable; make this more generic with model-specific wrappers
model.RoIFeatureTransform(
blob_in,
'pool5',
blob_rois='rois',
method=cfg.FAST_RCNN.ROI_XFORM_METHOD,
resolution=cfg.FAST_RCNN.ROI_XFORM_RESOLUTION,
sampling_ratio=cfg.FAST_RCNN.ROI_XFORM_SAMPLING_RATIO,
spatial_scale=spatial_scale
)
dim_bottleneck = cfg.RESNETS.NUM_GROUPS * cfg.RESNETS.WIDTH_PER_GROUP
stride_init = int(cfg.FAST_RCNN.ROI_XFORM_RESOLUTION / 7)
s, dim_in = add_stage(
model, 'res5', 'pool5', 3, dim_in, 2048, dim_bottleneck * 8, 1,
stride_init
)
s = model.AveragePool(s, 'res5_pool', kernel=7)
return s, 2048
def add_residual_block(
model,
prefix,
blob_in,
dim_in,
dim_out,
dim_inner,
dilation,
stride_init=2,
inplace_sum=False
):
"""Add a residual block to the model."""
# prefix = res_, e.g., res2_3
# Max pooling is performed prior to the first stage (which is uniquely
# distinguished by dim_in = 64), thus we keep stride = 1 for the first stage
stride = stride_init if (
dim_in != dim_out and dim_in != 64 and dilation == 1
) else 1
# transformation blob(bottleneck_transformation)
tr = globals()[cfg.RESNETS.TRANS_FUNC](
model,
blob_in,
dim_in,
dim_out,
stride,
prefix,
dim_inner,
group=cfg.RESNETS.NUM_GROUPS,
dilation=dilation
)
# sum -> ReLU
sc = add_shortcut(model, prefix, blob_in, dim_in, dim_out, stride)
if inplace_sum:
s = model.net.Sum([tr, sc], tr)
else:
s = model.net.Sum([tr, sc], prefix + '_sum')
return model.Relu(s, s)
def add_shortcut(model, prefix, blob_in, dim_in, dim_out, stride):
if dim_in == dim_out:
return blob_in
c = model.Conv(
blob_in,
prefix + '_branch1',
dim_in,
dim_out,
kernel=1,
stride=stride,
no_bias=1
)
return model.AffineChannel(c, prefix + '_branch1_bn', dim=dim_out)
# ------------------------------------------------------------------------------
# various transformations (may expand and may consider a new helper)
# ------------------------------------------------------------------------------
def bottleneck_transformation(
model,
blob_in,
dim_in,
dim_out,
stride,
prefix,
dim_inner,
dilation=1,
group=1
):
"""Add a bottleneck transformation to the model."""
# In original resnet, stride=2 is on 1x1.
# In fb.torch resnet, stride=2 is on 3x3.
(str1x1, str3x3) = (stride, 1) if cfg.RESNETS.STRIDE_1X1 else (1, stride)
# conv 1x1 -> BN -> ReLU
cur = model.ConvAffine(
blob_in,
prefix + '_branch2a',
dim_in,
dim_inner,
kernel=1,
stride=str1x1,
pad=0,
inplace=True
)
cur = model.Relu(cur, cur)
# conv 3x3 -> BN -> ReLU
cur = model.ConvAffine(
cur,
prefix + '_branch2b',
dim_inner,
dim_inner,
kernel=3,
stride=str3x3,
pad=1 * dilation,
dilation=dilation,
group=group,
inplace=True
)
cur = model.Relu(cur, cur)
# conv 1x1 -> BN (no ReLU)
# NB: for now this AffineChannel op cannot be in-place due to a bug in C2
# gradient computation for graphs like this
cur = model.ConvAffine(
cur,
prefix + '_branch2c',
dim_inner,
dim_out,
kernel=1,
stride=1,
pad=0,
inplace=False
)
return cur5月18日更新:
最近还发现了两个解读Detectron的博客1.Detectron代码分析:从Faster R-CNN到Mask R-CNN,感觉写得挺好的,是对Pytorch版的Detectron进行的解读,基本包含了整个Detectron框架的大部分内容,采用的是原理图+少量代码注解的形式
2.caffe2专栏 分文件对Detectron的相关源码进行了详细的注释
感兴趣的朋友都可以去看看