3D人体姿态估计论文汇总(CVPR/ECCV/ACCV/AAAI)
点击上方“3D视觉工坊”,选择“星标”
干货第一时间送达

作者:Vegetabird | 来源:知乎
https://zhuanlan.zhihu.com/p/137240831
本文仅做学术分享,如有侵权,请联系删除。
3D人体姿态估计是从图片或视频中估计出关节点的三维坐标 (x, y, z),它本质上是一个回归问题。
它广泛地应用在动画、游戏、运动捕捉系统和行为理解中,也可以做为其他算法的辅助环节(行人重识别),并可以跟人体相关的其他任务一起联合学习(人体解析)。
挑战
然而,因为一个2D骨架可以对应多个3D骨架,它具有在单视角下2D到3D映射中固有的深度模糊性与不适定性,这也导致了它本身就具有挑战性。
目前,3D姿态估计的主要瓶颈是缺少大型的室外数据集,并缺少一些特殊姿态的数据集(如摔倒, 打滚等)。这主要由于3D姿态数据集是依靠适合室内环境的动作捕捉(MOCAP)系统构建的,而MOCAP系统需要带有多个传感器和紧身衣裤的复杂装置,在室外环境使用是不切实际的。因此数据集大多是在实验室环境下建立的,模型的泛化能力也比较差。
方法
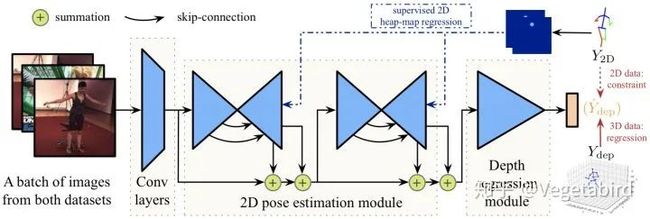
基于单视角的3D姿态估计主要分为两种方法。第一种是从2D图片直接暴力回归得到3D坐标,第二种是分为两个阶段进行,先获取2D信息,然后再“提升”到3D姿态。第二种方法又可以分为两类。一类是联合2D,3D共同训练(2D姿态网络和2D-3D姿态网络一起训练),还有一类是直接用预训练好的2D姿态网络,将得到的2D坐标输入到3D姿态估计网络中,我把第二类方法称为基于以2D骨架序列为输入的3D姿态估计。这几种方法的示意图见下,其中该图参考于论文[1]。

第一种方法(从2D图片直接暴力回归得到3D坐标)通过深度学习模型建立单目RGB图像到3D坐标的端到端映射,但是对于单一模型来说需要学习的特征过于复杂。
在早期,论文[2] (ACCV 2014)是第一个把深度学习应用到基于单张图片的3D姿态估计中,它设计了一个深度卷积网络从RGB图片直接回归3D坐标,并用多任务学习的方式将回归的关键点坐标和检测到的关键点bounding box结合了起来。而在监督的时候,不直接用3D坐标,用的是骨干长度和关键点bounding box来监督。

论文[3] (CVPR 2017)从2D图片中直接得到体素(Volumetric representation),而不是直接回归关节点的坐标,并取最大值的位置作为每个关节点的输出。体素这东西实际上是从2D姿态估计的heatmap那学来的,其实就是3D heatmap。

这里还有个[3]的扩展工作[4] (ECCV 2018)引入了积分回归(Integral Pose Regression)模块,将原先的取heatmap最大值对应的位置改成对heatmap求关节点的期望,使这一过程可微。全文就基于Integral Pose Regression模块做了大量的实验并验证其有效性,在3个数据集上分别实验成文。

联合2D,3D共同训练的方法不像第一种方法直接从图片中回归得到3D坐标,而是通过网络先得到2D信息作为特征的中间表示。2D网络通常使用Hourglass[5] (ECCV 2016),2D信息也以heatmap的形式来表示。但这种方法还是需要复杂的网络结构和充足的训练样本。
论文[6] (ICCV 2017)提出了一种端到端的2D姿态与深度回归3D人体姿态估计的网络框架,并在没有ground truth的情况下,使用“骨干长度之间的比率”Loss来实现弱监督。
有个做手部三维姿态估计的工作[7] (CVPR 2019)也是利用了联合2D,3D的方法。它以单张图片为输入,提出了一种基于图卷积端到端的3D手姿态和形态估计的框架。此外,他还生成了一个新的3D mesh手的数据集,先用生成的数据进行训练,再用真实数据的深度图进行弱监督减少domain gap。

在3D姿态估计中,非线性程度高,输出空间大,使用2D姿态估计中的基于检测的模型往往不能得到很好的效果,因此3D姿态估计主要使用基于回归的模型。然而,直接使用基于回归的方法往往不如先对2D姿态进行估计再进行3D估计的方法能取得更好的效果。
基于以2D骨架序列为输入的3D姿态估计是直接用预训练好的2D姿态网络,将得到的2D坐标输入到3D姿态估计网络中。这种方法能得以很好地实现与流行,主要得益于目前的2D姿态估计较为成熟,且通常采用Hourglass[5] (ECCV 2016)和CPN[8] (CVPR 2018)来作为2D姿态估计器。
这种方法可以减少模型在2D姿态估计上的学习压力;网络结构简单,轻量级;实时性,快速;训练快,占用显存少。但是会因为缺少原始图像的输入,可能会丢失一些空间信息,并且2D姿态估计的误差会在3D估计中放大。
论文阅读
一些基于以2D骨架序列为输入的3D姿态估计的论文
1.A simple yet effective baseline for 3d human pose estimation, ICCV 2017.
2.Learning pose grammar to encode human body configuration for 3d pose estimation, AAAI 2018.
3.Exploiting temporal information for 3d human pose estimation, ECCV 2018.
4.3D human pose estimation in video with temporal convolutions and semi-supervised training, CVPR 2019.
5.Semantic graph convolutional networks for 3D human pose regression, CVPR 2019.
6.Exploiting spatial-temporal relationships for 3d pose estimation via graph convolutional networks, ICCV 2019.
7.Repnet: Weakly supervised training of an adversarial reprojection network for 3d human pose estimation, CVPR 2019.
这些论文都用了相同的评价指标
1.Mean Per Joint Position Error (MPJPE): Protocol 1,关节点坐标误差的平均值
2.网络输出的关节点坐标与ground truth的平均欧式距离(通常转换到相机坐标)
3.Procrustes analysis MPJPE (P-MPJPE): Protocol 2,基于Procrustes分析的MPJPE
4.先对网络输出进行刚性变换(平移,旋转和缩放)向ground truth对齐后,再计算MPJPE
A Simple Yet Effective Baseline for 3d Human Pose Estimation (ICCV 2017) [Paper][Code]
这篇文章是基于以2D骨架序列为输入的3D姿态估计的一篇重要代表作,截止2020年3月已被引300多次。后人很多“以2D骨架序列为输入”的工作都是基于这篇论文的,而且都会引用这篇文章。
动机
虽然3D人体姿态估计已取得了不错的成果,但我们还是没有挖掘到问题的本质,从根本上解决痛点,不知道是什么原因导致某些姿态估计错了。作者归纳为两种原因
·2D姿态估计不够准确(visual analysis)。
·从2D关节点到3D关节点的映射不够完善。
所以本文进行了一系列有趣的实验来找到错误的根源,并解决它。
模型
网络结构很简单,就拿6个全连接层实现了一个2D坐标到3D坐标映射的功能。输入是16×2的2D关节点坐标,先经过一个全连接层提升为16×1024维的向量,然后输入到2个block中,再在最后经过一个全连接层将1024维的数据降维到16×3。其中每个block包含2个全连接层,且每个FC层跟着Batch Normalization, ReLU和Dropout,并使用残差连接。

结果
作者拿加了不同高斯噪声的2D ground truth骨架坐标进行测试,发现随着噪声的变大,错误率大大提高。
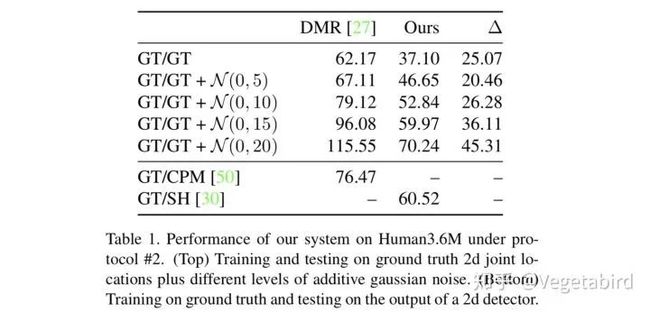
作者还跟之前所有的方法进行了对比,实现了SOTA的性能。只拿2D骨架为输入,便比所有以图像为输入的方法性能要好,包括之前CVPR 2017用3D heatmap的工作[3]。
实验结果显示用2D的ground truth关节点来生成3D的关节点错误率非常低,比目前最好的结果好了30%。而我们用从2D图像得到的2D关节点来生成3D关节点,这样的错误率只比目前最好的结果稍微好一点。
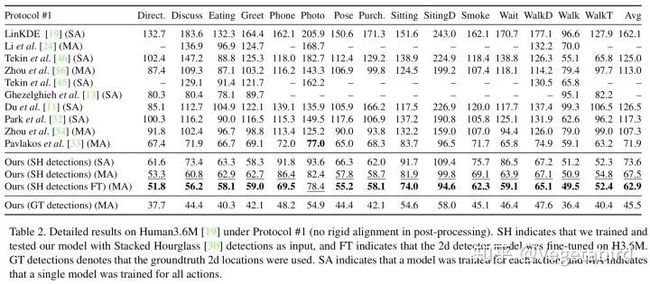
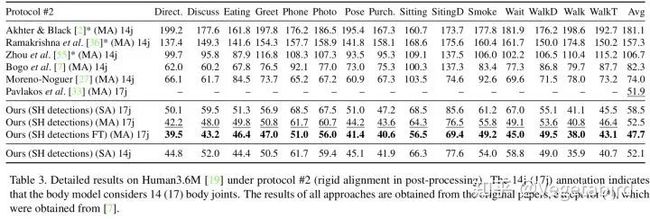
所以这一系列实验可以说明从2D姿态映射到3D姿态用一个简单,快速且轻量级的baseline就可以很好的实现,并且3D姿态估计的错误主要来源于2D姿态估计的不准确性,因此作者建议我们以后可以把工作主要放在2D图像向2D姿态的转化这一步。
Learning pose grammar to encode human body configuration for 3d pose estimation (AAAI 2018) [Paper][Code]
动机
·之前的方法很少将领域知识(domain-specific knowledge)应用过来。
·在进行跨视角(未知的相机视角)姿态估计时,泛化能力较差。
解决方案
·考虑运动学,对称性和运动协调性这3个domain-specific knowledge,提出了一个姿态语法网络(pose grammar),以对关于人体依赖关系的knowledge进行编码。
·设计了一个姿态模拟器(pose simulator),通过虚拟摄像机视图扩展训练样本。
模型
这篇文章是上文[9]的扩展,基本的网络结构用的也是带有残差连接的2层FC。还使用了对人体依赖性和相互关系进行编码的姿态语法网络(pose grammar network),其中每个grammar以关节点之间关联的双向RNN来表示。

这项工作还通过一个虚拟摄像机视图将3D ground-truth投影到虚拟的平面中得到2D姿态来扩充数据。

结果
本文构造了一种适用于交叉视图的新评估协议protocol #3,使用了不同的相机视角来训练与评估,以验证模型的泛化能力。可从实验结果观察到,之前大多数SOTA的方法在这种情况下表现都不是很好,而我们的方法可以很好地应对该挑战。
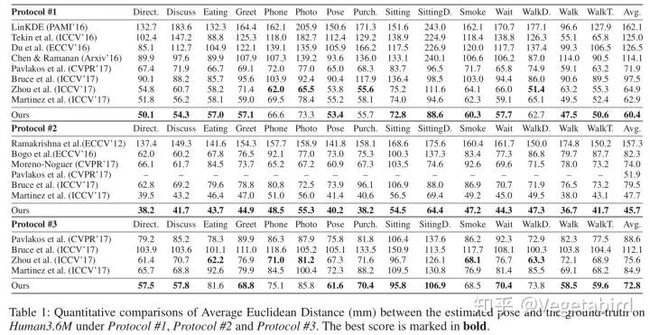
Exploiting temporal information for 3d human pose estimation (ECCV 2018) [Paper][Code]
动机
由于各帧之间的不连贯性与独立性,以单帧图片作为输入预测每个帧的3D姿态会导致视频抖动。因此,这项工作中利用时间信息,将2D骨架序列作为输入来得到3D姿态。
模型
该模型是个序列到序列的LSTM网络结构,并在解码器端带有残差连接。并引入时间平滑Loss来限制时间一致性,确保两帧之间的变化不是很大。
结果
实验结果显示引入时间信息将性能提升了12.2%,并且在某些帧2D姿态检测不准确的时候也能有较好的效果。
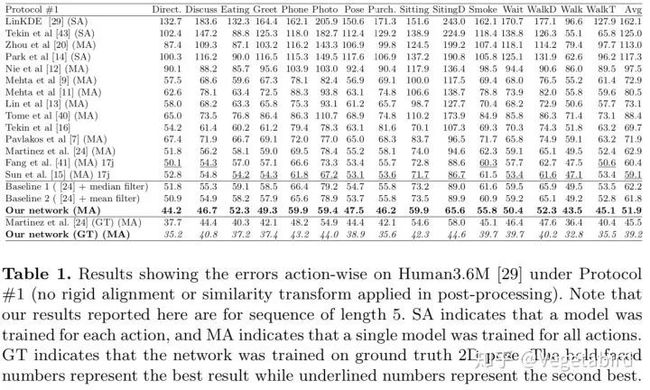
作者还实验了不同序列长度对实验结果的影响,发现该网络并不是序列长度越长越好,而是在序列长度为5的时候有最小的MPJPE。所以该序列模型还是不够完善的,需要后人进一步改进。

3D human pose estimation in video with temporal convolutions and semi-supervised training (CVPR 2019) [Paper][Code]
动机
·之前使用的循环神经网络无法并行处理多帧,同时处理2D姿态的空间信息和时间维度信息。
·缺乏标记的3D姿态数据集。
解决方案
·提出了时域空洞卷积的模型,相比RNN具有更高的精度、更简洁与有效性,在计算复杂度和参数数量上都有优势。
·引入了一种利用无标记视频数据的半监督训练方法。
模型
模型采用一种带有残差连接的全卷积结构,自底向上输出三维信息,捕获长期信息。时域卷积模型使用2D关节点序列(底部)作为输入,然后产生3D姿态预测作为输出(顶部)。

与论文[9]类似,首先将输入的17×2维度的骨架序列提升到1024维,然后通过4个block将2D骨架转化为3D骨架,其中每个block包含2层1024 channels的时域空洞卷积网络,并使用残差进行连接,最后的输出是17×3的3D骨架。

结果
在有监督的情况下,我们的全卷积模型在Human3.6M上的平均每关节位置误差比之前SOTA的方法降低了6mm,相对误差减少了11%。当以243帧为输入时,已将17年simple baseline[9]的62.9mm Protocol 1降到了46.8mm。
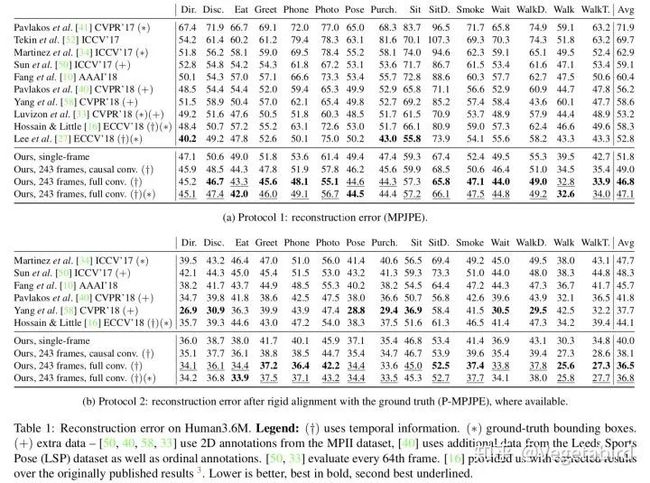
作者还给出了输入不同帧数时模型的参数量与性能

Semantic graph convolutional networks for 3D human pose regression (CVPR 2019) [Paper][Code]
动机
·为了使图卷积在具有任意拓扑结构的节点上工作,核函数W对所有边都是权值共享的,这样会导致临边以及整个图的内部结构没有被很好地利用起来。
·之前的工作仅使用了每个节点的第一级临边,这样就把感受野局限在一维大小,不利于学习全局特征。
解决方案:使用语义图卷积网络,学习捕获在图中没有显式表示的语义信息,例如局部和全局节点关系。
模型
首先使用预训练好的2D姿态网络从图片中提取2D骨架,然后输入到语义图卷积网络中将2D Pose回归到3D Pose,最后计算关节点Loss与骨长Loss之和来训练网络。

语义图卷积的网络结构图与上面这篇文章[12]的时域空洞卷积网络图很像

结果
实验结果显示,SemGCN实现了SOTA的性能,同时使用的参数减少了90%。

Exploiting Spatial-temporal Relationships for 3D Pose Estimation via Graph Convolutional Networks (ICCV 2019) [Paper][Code]
动机
3D姿态估计有个ill-posed problem:一个2D骨架可以对应多个3D骨架,因此很难得到一个唯一的有效解。因为本文利用几何依赖与时空信息来解决这个问题。
·空间信息:减少空间上不存在的3D结构的可能性,并减轻自遮挡的问题。
·时间信息:解决诸如深度模糊和视频抖动之类的问题。
模型
这项工作用预训练好的CPN[8]得到2D姿态,将多帧的2D坐标输入到时空图卷积中,并取中间那帧的3D姿态作为输出。
时空图卷积在时间上,将每个关节与其相邻帧中的对应关节连接起来;在空间上,将每个帧中有直接和间接运动学上依赖关系(相邻,对称)的关节点连接起来。并将关节点分为六个类,针对不同的节点类使用不同的卷积核进行训练。

时空图卷积使用了U-net的多尺度结构[15],该local-to-global网络结构进行了2层Graph Pooling和Graph Upsampling来捕获不同scale的特征。

结果
当以单帧为输入的时候,已将17年simple baseline[9]的62.9mm Protocol 1降到了50.6mm,并在T=7的时候MPJPE降到到了48.8mm。

Repnet: Weakly supervised training of an adversarial reprojection network for 3d human pose estimation (CVPR 2019) [Paper][Code]
动机
之前的模型虽然在相似的数据上具有较好的性能,但是泛化能力较差,无法将其应该到未知的环境中。所以本文的解决方案是忽略2D到3D数据的对应关系,用unpaired data,使用基于弱监督的对抗学习方法来训练网络,以解决过拟合问题。
模型
将由Hourglass[5]得到的2D关节点坐标分别输入到2个网络中。通过一个生成网络学习从2D关键点分布到3D关键点分布的映射,得到3D pose,经过一个相机网络得到弱透视相机的相机内参,并利用两者进行计算,重投影到2D pose来监督预测姿态与原始2D输入的偏差。将3D pose输入到鉴别器网络网络来学习3D人体姿态的分布。这里各个模块使用的网络结构都很简单,都是全连接层来实现,且都是参考[9]的网络结构。
这篇文章虽然使用了3D-ground truth来训练,但是没用2D-3D对来训练网络,所以是弱监督的。由于使用了未配对的数据,GAN的输出是比较杂乱的,所以将它投影到2D平面来保证输出的3D pose相对比较准确。这里,使用对抗训练的好处就是泛化能力强,可以in the wild,在另外一个域进行测试也能有较好的性能。

结果
从结果可以发现,跟全监督的方法相比结果肯定不是最好的,但跟Weakly Supervised方法相比达到了SOTA的性能。

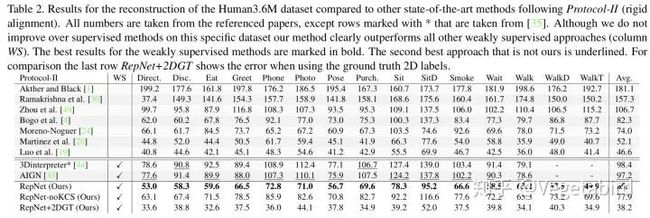
跟论文[9]一样,也拿加了不同的高斯噪声的ground truth的2D坐标进行测试。

Reference
1.Chen X, et al. Weakly-supervised discovery of geometry-aware representation for 3d human pose estimation, CVPR 2019.
2.Li S, et al. 3d human pose estimation from monocular images with deep convolutional neural network, ACCV 2014.
3.Pavlakos G, et al. Coarse-to-fine volumetric prediction for single-image 3D human pose, CVPR 2017.
4.Sun X, et al. Integral human pose regression, ECCV 2018.
5.Newell A, et al. Stacked hourglass networks for human pose estimation, ECCV 2016.
6.Zhou X, et al. Towards 3d human pose estimation in the wild: a weakly-supervised approach, ICCV 2017.
7.Ge L, et al. 3d hand shape and pose estimation from a single rgb image, CVPR 2019.
8.Chen Y, et al. Cascaded pyramid network for multi-person pose estimation, CVPR 2018.
9.Martinez J, et al. A simple yet effective baseline for 3d human pose estimation, ICCV 2017.
10.Fang H S, et al. Learning pose grammar to encode human body configuration for 3d pose estimation, AAAI 2018.
11.Rayat Imtiaz Hossain M, et al. Exploiting temporal information for 3d human pose estimation, ECCV 2018.
12.Pavllo D, et al. 3D human pose estimation in video with temporal convolutions and semi-supervised training, CVPR 2019.
13.Zhao L, et al. Semantic graph convolutional networks for 3D human pose regression, CVPR 2019.
14.Cai Y, et al. Exploiting spatial-temporal relationships for 3d pose estimation via graph convolutional networks, ICCV 2019.
15.Ronneberger O, et al. U-net: Convolutional networks for biomedical image segmentation, MICCAI 2015.
16.Yan S, et al. Spatial temporal graph convolutional networks for skeleton-based action recognition, AAAI 2018.
17.Wandt B, et al. Repnet: Weakly supervised training of an adversarial reprojection network for 3d human pose estimation, CVPR 2019.
推荐阅读:
专辑|相机标定
专辑|3D点云
专辑|SLAM
专辑|深度学习与自动驾驶
专辑|结构光
专辑|事件相机
专辑|OpenCV学习
专辑|学习资源汇总
专辑|招聘与项目对接
专辑|读书笔记
专辑|相机标定
专辑|3D点云
专辑|SLAM
专辑|深度学习与自动驾驶
专辑|结构光
专辑|事件相机
专辑|OpenCV学习
专辑|学习资源汇总
专辑|招聘与项目对接
专辑|读书笔记
重磅!3DCVer-学术论文写作投稿 交流群已成立
扫码添加小助手微信,可申请加入3D视觉工坊-学术论文写作与投稿 微信交流群,旨在交流顶会、顶刊、SCI、EI等写作与投稿事宜。
同时也可申请加入我们的细分方向交流群,目前主要有3D视觉、CV&深度学习、SLAM、三维重建、点云后处理、自动驾驶、CV入门、三维测量、VR/AR、3D人脸识别、医疗影像、缺陷检测、行人重识别、目标跟踪、视觉产品落地、视觉竞赛、车牌识别、硬件选型、学术交流、求职交流等微信群,请扫描下面微信号加群,备注:”研究方向+学校/公司+昵称“,例如:”3D视觉 + 上海交大 + 静静“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进去相关微信群。原创投稿也请联系。

▲长按加微信群或投稿

▲长按关注公众号
3D视觉从入门到精通知识星球:针对3D视觉领域的知识点汇总、入门进阶学习路线、最新paper分享、疑问解答四个方面进行深耕,更有各类大厂的算法工程人员进行技术指导。与此同时,星球将联合知名企业发布3D视觉相关算法开发岗位以及项目对接信息,打造成集技术与就业为一体的铁杆粉丝聚集区,近1000+星球成员为创造更好的AI世界共同进步,知识星球入口:
学习3D视觉核心技术,扫描查看介绍,3天内无条件退款

圈里有高质量教程资料、可答疑解惑、助你高效解决问题