【视频行为识别8】SlowFast Networks for Video Recognition快慢双通道网络(CVPR2019)
背景:
作者通过观察发现一个问题:视频场景中的帧通常包含两个不同的部分 —> 不怎么变化或者缓慢变化的静态区域和正在发生变化的动态区域(此区域一般为视频中行为发生的重要处)。例如,飞机起飞的视频会包含相对静态的机场和一个在场景中快速移动的动态物体(飞机)。
因此,本文的SlowFast网络:
1)使用了一个慢速高分辨率CNN(Slow通道)来分析视频中的静态内容;
2)同时使用一个快速低分辨率CNN(Fast通道)来分析视频中的动态内容。
3)这一技术部分源于灵长类动物的视网膜神经节的启发,在视网膜神经节中,大约80%的细胞(P-cells)以低频运作,可以识别细节,而大约20%的细胞(M-cells)则以高频运作,负责响应快速变化。
概述:
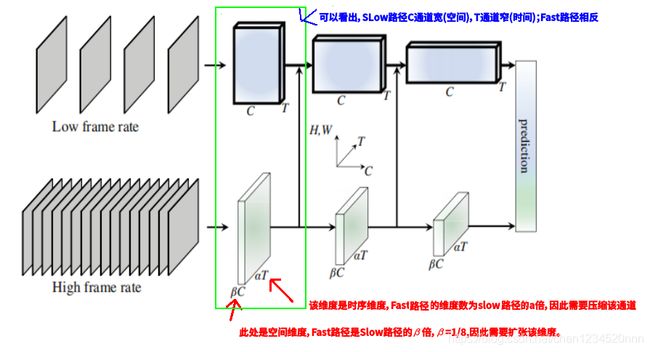
何凯明团队提出了一个快慢双通道网络(详见下图),利用FastPath捕捉动作信息;SlowPath捕捉视觉语义信息。
效果:在无预训练的情况下,Kinetics数据集上视频分类准确率达到了79.0%,在AVA action detection数据集上达到了当时最好的28.3mAP。
Slow路径:旨在捕获由图像或稀疏帧提供的语义信息,它以低帧率运行,刷新速度慢。
Fast路径:用于捕获快速变化的动作,它的刷新速度快、时间分辨率高。占总计算开销的20%左右。第二个路径通道较少。
二者通过横向连接(lateral connection)进行融合。

图1 SlowFast 网络包括低帧率、低时间分辨率的 Slow 路径和高帧率、高时间分辨率(Slow 路径时间分辨率的 α 倍)的 Fast 路径。Fast 路径使用通道数的一部分(β,如 β = 1/8)来轻量化。Slow 路径和 Fast 路径通过横向连接融合。
受到灵长类视觉系统中视网膜神经节细胞的生物学研究启发。研究发现,在这些细胞中,约80% 是P细胞,约15-20% 是M细胞。M细胞以较高的时间频率工作,对时间变化更加敏感,但对空间细节和颜色不敏感。P细胞提供良好的空间细节和颜色,但时间分辨率较低。
Slow路径:
SlowFast网络使用3D-ResNet,捕捉若干帧后进行3D卷积。
1)低帧率:slow路径输入帧数为T,在视频中每隔![]() 帧取一帧图像(采样率为
帧取一帧图像(采样率为![]() ),
),![]() 取16。即视频的总帧数为:
取16。即视频的总帧数为:![]() 。
。
2)高通道数:slow的图像帧数比fast路径少,但特征的通道数比fast路径多。
Fast路径:
1)高帧率
Fast路径采样αT帧作为输入,比Slow途径密集α倍。它的时间采样率为 τ/α,其中α>1,本文中α=8。
2)高时间分辨率特征
整个Fast路径中均不使用时间下采样层(既不使用时间池化也不使用时间步长的卷积操作),特征张量在时间维度上总是具有αT帧,尽可能地保持时间保真度。
3)低通道容量
Fast路径的通道数是Slow路径的β(β<1)倍。在文中β=1/8。
详细网络结构:

1)上表中,卷积核的尺寸为![]() ,其中
,其中![]() 分别表示时间、空间和通道channel的尺寸大小。
分别表示时间、空间和通道channel的尺寸大小。
2)步长为:![]() 。
。
3)速率比是α=8,通道比是β=1/8。τ是16。
4)绿色表示高一些的时序分辨率,Fast通道中的橙色表示较少的频道。
3.3横向连接
横向连接[32]:是用于合并不同级别的空间分辨率和语义的流行技术。Carreira和Zisserman提出I3D,把two-stream结构中的2D卷积扩展为3D卷积。由于时间维度不能缩减过快,前两个汇合层的卷积核大小是1×2×2,最后的汇合层的卷积核大小是2*7*7。和之前文章不同的是,two-tream的两个分支是单独训练的,测试时融合它们的预测结果。
三种横向链接方式:
如上图中所示,来自Fast通道的数据通过侧向连接被送入Slow通道,这使得Slow通道可以了解Fast通道的处理结果。单一数据样本的形状在两个通道间是不同的(Fast通道是{αT, S², βC} 而Slow通道是 {T, S², αβC})。因此,SlowFast对Fast通道的结果进行数据变换,然后融入Slow通道。
论文给出了三种进行数据变换的思路:其(作者实验结论第3种效果最好)。
1)Time-to-channel:将{αT, S², βC} 变形转置为 {T , S², αβC},就是说把α帧特征压入一帧中。
2)Time-strided采样:简单地每隔α帧进行采样,{αT , S², βC} 就变换为 {T , S², βC}。
3)Time-strided卷积:用一个![]() 的核进行3d卷积, 输出通道数为2βC(空间维度扩张2倍),时序维度的步长= α(时序维度压缩a倍)。
的核进行3d卷积, 输出通道数为2βC(空间维度扩张2倍),时序维度的步长= α(时序维度压缩a倍)。
另,研究人员实验双向侧链接,即将Slow通道结果也送入Fast通道,对性能没有改善。
在每个通道的末端,SlowFast执行全局平均池化,一个用来降维的标准操作,然后组合两个通道的结果并送入一个全连接分类层,该层使用softmax来识别图像中发生的动作。
对于ResNets[24],这些连接位于pool1、res2、res3和res4之后。这两条路径有不同的时间维度,因此横向连接执行一个转换以匹配它们(详见第。3.4条)。
训练:
1)本文的模型是从随机初始化(“从头开始”)开始训练的,不使用ImageNet[7]或任何预训练。
2)对于时间域,随机从全长视频中抽取一个片段(αT×τ帧),慢路径和快路径的输入分别为T帧和αT帧;
3)对于空间域,我们随机从视频或其水平翻转中裁剪224×224像素,较短的边随机抽取[256,320]像素。
预测:
1)我们对短边重新调整为256的视频执行空间完全卷积推理。
2)对于时域,从全长视频中均匀地采样10个剪辑,并单独计算它们的softmax分数。最终预测是所有剪辑的平均softmax分数。
3)实际的推理时间计算。 由于现有论文在空间和时间上进行裁剪/剪切的推理策略不同。与以前的工作进行比较时,我们在推断时报告了每个时空“视图”(具有空间裁剪的时间片段)的FLOP,并报告了使用的视图数。在我们的案例中,推断时空间大小为256 * 256(而不是 使用224 * 224进行训练)和10个时间片段,每个片段具有3种空间裁剪(30个视图)。
实验结果:
在Kinetics-400数据集比较:

在最后一列中,我们报告了单“视图”(具有空间裁剪的时间剪辑)的推理成本×所使用的视图数,慢通道中具有不同的输入采样(T×τ)和主干(R-50、R-101、NL)。“N/A”表示这些数值对我们不适用。
在Kinetics-600数据集比较:
