Asm2Vec阅读笔记
文章目录
- Asm2Vec: Boosting Static Representation Robustness for Binary Clone Search against Code Obfuscation and Compiler Optimization 阅读笔记
- 1 Abstract
- 2 Introduction
- 创新点
- 贡献
- 3 Overall Workflow
- 4 Assembly Code Representation Learning(汇编代码表示学习)
- PV-DM模型
- 原始的PV-DM模型
- Asm2Vec模型
- 建模汇编函数
- (1)选择性内联
- (2) 边缘覆盖
- (3)随机游动
- 5 实验
- Searching with Different Compiler Optimiza- tion Levels(在编译器优化下)
- Searching with Code Obfuscation(代码混淆)
- Searching against All Binaries
- Searching Vulnerability Functions
Asm2Vec: Boosting Static Representation Robustness for Binary Clone Search against Code Obfuscation and Compiler Optimization 阅读笔记
S&P 2019 | 原文链接 | 论文PPT
1 Abstract
实用的二进制代码克隆搜索引擎依赖于汇编代码的强大矢量表示形式。但是,现有的代码克隆搜索方法依赖于手动的特征工程过程来为汇编函数形成特征向量,但却不考虑特征之间的关系,同时无法识别那些可以通过统计来区分汇编函数的独特模式。
为了解决这个问题,论文提出将汇编程序的词汇语义关系和汇编函数的向量表示结合起来。论文研究出了了汇编代码表示学习模型Asm2Vec。它只需要汇编代码作为输入,不需要任何先验知识如汇编函数之间的正确映射。它可以在汇编代码的token之间找到并合并丰富的语义关系。
论文表明,学习的表示形式更鲁棒,并且相对于混淆和优化所引入的变化,其性能明显优于现有方法。
2 Introduction
设计一个代码克隆搜索引擎的困难在于:编译器优化和代码混淆让两个逻辑上相似的汇编函数看起来不同。编译器优化和代码混淆会破坏控制流图和基本块,从而导致汇编函数语义上相似但是结构上不同。
开发一个克隆搜索引擎需要一个强大的汇编代码矢量表示,通过它可以测量查询和索引函数之间的相似性。基于手动设计的功能,可以将相关研究分为静态或动态方法。动态方法通过动态分析汇编代码的I / O行为对语义相似性进行建模;静态方法通过在汇编代码之间就语法或描述性统计数据,来寻找静态差异来对它们之间的相似性进行建模。
创新点
该论文的创新性主要两点:
- 将词汇语义的关联添加进模型;
- 已存在的静态方法的特征权重是一样的,或者需要一个等价的集合函数的映射来学习权重。该论文通过训练许多汇编代码的数据,让该模型识别出将一个功能与其他功能区分开来的最佳表示。
贡献
-
论文提出了一种用于汇编代码克隆检测的新方法。这是利用表示学习来为汇编代码构造特征向量的第一项工作,同时能够减轻人工工作;
-
论文开发了一个用于汇编代码语法和控制流图的表示学习模型,即Asm2Vec。该模型学习token之间的潜在词法语义,并将汇编函数表示为相互加权的集合语义的混合。学习过程不需要任何关于汇编代码的先验知识,比如编译器优化设置或汇编函数之间的正确映射。它只需要汇编代码函数作为输入。
-
论文证明,与最新的静态功能和动态方法相比,Asm2Vec在代码混淆和编译器优化方面更具弹性。实验涵盖了编译器的不同配置以及强大的混淆器,该混淆器可替代指令,拆分基本块,添加伪逻辑并完全破坏原始控制流程图。论文还对公开的漏洞数据集进行了漏洞搜索案例研究,其中Asm2Vec的误报率为零,召回率为100%。它优于动态的最新漏洞搜索方法。
3 Overall Workflow
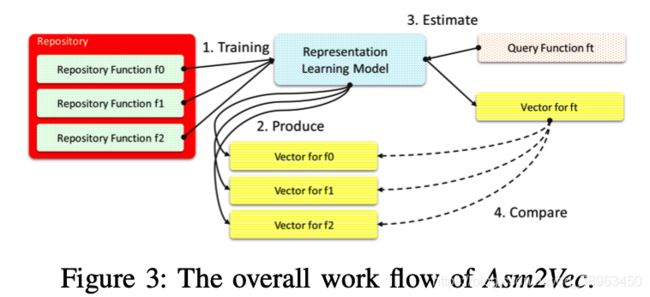
- 通过汇编函数数据集构造一个神经网络模型
- 模型为每一个库函数构造一个向量
- 利用模型预测目标函数Ft的表示向量
- 用余弦相似度来比较Ft和其他在库中的向量来得到top-k候选向量
4 Assembly Code Representation Learning(汇编代码表示学习)
PV-DM模型
首先,通过原始的PV-DM神经网络学习文本段落的矢量化表示。
然后,制定Asm2Vec模型,并描述如何针对给定函数在指令序列上对其进行训练。
之后,阐述如何将控制流程图建模为多个序列。
原始的PV-DM模型
PV-DM模型设计用于文本数据。它是原始word2vec模型的扩展。它可以共同学习每个单词和每个段落的矢量表示。
Asm2Vec模型
本部分对应于图3中的步骤1和2。训练表示模型,并为每个存储库函数fs∈RP生成数值向量。
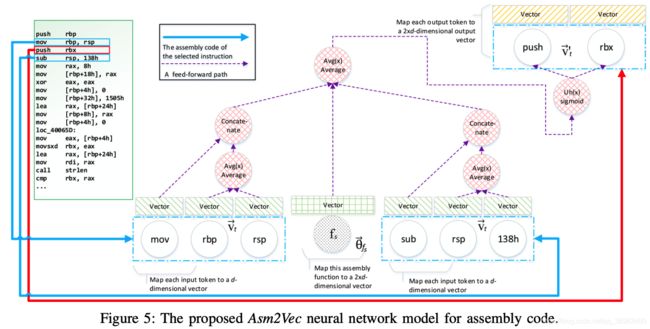
首先,将每个存储库函数 f s f_s fs映射到一个向量 θ f s ⃗ ∈ R 2 × d \vec{\theta_{f_{s}}} \in R^{2\times{d}} θfs∈R2×d。将汇编代码中的操作数和运算视为token,将每一个token t映射到两个数值向量 v t ⃗ ∈ R d \vec{v_{t}} \in R^d vt∈Rd 和 v t ′ ⃗ ∈ R 2 d \vec{v^{'}_t}\in R^2d vt′∈R2d, v t ⃗ \vec{v_t} vt用于tokens之间的关系的向量表示, v t ′ ⃗ \vec{v^{'}_t} vt′用于token的预测。 θ f s ⃗ \vec{\theta_{f_{s}}} θfs和 v t ⃗ \vec{v_t} vt 初始化为小随机数, v t ′ ⃗ \vec{v^{'}_t} vt′被初始化为0。


对每一个函数 f s ∈ R P f_s \in RP fs∈RP,它有许多的指令序列 S ( f s ) = s e q [ 1 : i ] S(f_s) = seq[1:i] S(fs)=seq[1:i],一个指令序列中有许多指令 I ( s e q i ) = i n [ 1 : j ] I(seq_i)=in[1:j] I(seqi)=in[1:j],一个指令 i n j in_j inj包含操作数 A ( i n j ) A(in_j) A(inj)和操作符 P ( i n j ) P(in_j) P(inj)。token T ( i n j ) = P ( i n j ) ∥ A ( i n j ) T(in_j) = P(in_j) \parallel A(in_j) T(inj)=P(inj)∥A(inj) 。
对于函数 f s f_s fs中的每个序列 s e q i seq_i seqi,神经网络从一开始就遍历所有指令。获得当前指令 i n j in_j inj,上一条指令 i n j − 1 in_{j -1} inj−1和下一条指令 i n j + 1 in_{j +1} inj+1。忽略了边界的指令。通过PV-DM模型最大化目标函数:
](http://img.e-com-net.com/image/info8/bfb717dcc23b4ff49cd524c61e818ab6.jpg)
通过当前函数的向量和邻居指令来预测当前指令。邻居指令提供的向量捕获了语法上的语义关系,当前函数的向量会记住在上下文中无法预测的内容,它对区分当前功能和其他功能的指令进行建模。
给定一个函数 f s f_s fs,通过先前构建的字典查找它的向量表示 θ f s ⃗ \vec{\theta_{f_{s}}} θfs。为了将邻居指令建模为 C T ( i n ) ∈ R 2 × d CT(in) \in R^{2×d} CT(in)∈R2×d,对它的操作数(∈Rd)的向量表示取平均,并将平均向量(∈Rd)与操作符的向量表示进行连接。
它可以表示为:

通过用 C T ( i n j − 1 ) CT(in_j − 1) CT(inj−1)和 C T ( i n j + 1 ) CT(in_j + 1) CT(inj+1)对 f s f_s fs求平均值, δ ( i n , f s ) \delta(in,f_s) δ(in,fs)对邻居指令的联合记忆进行建模:
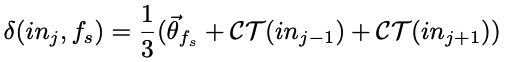
给定 δ ( i n , f s ) \delta(in,f_s) δ(in,fs),公式2中的概率项可以重写如下:

之前说过,将每一个token映射成两个向量 v ⃗ \vec{v} v和 v ′ ⃗ \vec{v^{'}} v′, v ′ ⃗ \vec{v^{'}} v′被用来进行预测。公式5中的概率可以建模为softmax多类回归问题:
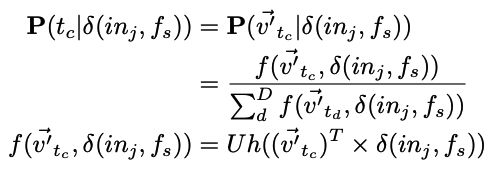
D表示根据库RP构建的整个词汇表。 Uh(·)表示应用于向量的每个值的Sigmod函数。|D|对于softmax分类太大。所以使用k个负采样方法将对数概率近似为:
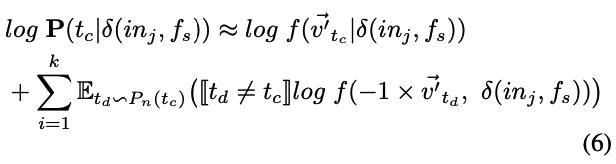
[[·]]函数:如果此函数内部的表达式的计算结果为true,则输出1;否则,结果为0。负采样算法通过随机选择的k个负样本 t d ∣ t d ≠ t c {td \vert td\neq tc} td∣td=tc来区分正确的猜测tc。 E t d P n ( t c ) E_{t_{d}~P_{n}(tc)} Etd Pn(tc)是采样函数,根据噪声分布 P n ( t c ) P_{n}(tc) Pn(tc)从词汇表D中提取一个token t d t_d td。通过分别取KaTeX parse error: Undefined control sequence: \Vec at position 1: \̲V̲e̲c̲{v_t}和KaTeX parse error: Undefined control sequence: \Vec at position 1: \̲V̲e̲c̲{\theta_{f_s}}的导数,可以如下计算梯度:
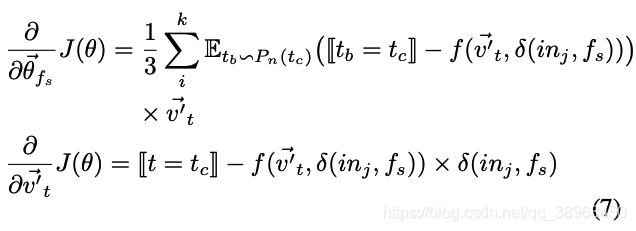
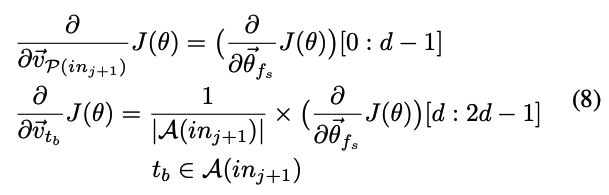
之后,使用反向传播来更新所涉及向量的值。具体来说是根据学习梯度更新 θ f s ⃗ \vec{\theta_{f_s}} θfs,所有涉及的 v t ⃗ \vec{v_t} vt和涉及的 v t ′ ⃗ \vec{v^{'}_t} vt′的梯度。
建模汇编函数
本节中,将汇编函数建模为多个序列。由于控制流程图的原始线性布局覆盖了一些无效的执行路径,所以不能直接将其用作训练序列。相反,我们将控制流图建模为边缘覆盖序列和随机游动。
(1)选择性内联
函数内联是一种编译器优化技术,它用被调用函数的主体替换函数调用指令,扩展了原始的汇编函数,并通过消除调用开销来提高其性能。它对控制流图进行了显著的修改,是汇编代码克隆搜索的主要挑战。
1)为了语义正确性,BinGo将所有标准库调用内联。我们不内联任何库调用,因为库调用token之间的词汇语义已经我们的模型中被很好地捕获。
2)BinGo递归内联函数调用,但我们只扩展调用图中的一阶调用。因为递归地扩展被调用方函数,会将太多被调用函数的代码主体包含到调用方中,这使得调用方函数代码在静态上更相似于被调用方。
BinGo使用的耦合度度量获取了每个被调用函数 f c f_c fc的入度和出度的比率:
![]()
判断一个函数是否需要内联,我们采用和Bingo同样的方法和同样的阈值值0.01。但如果被调用函数的长度大于调用函数,或者与调用函数的长度相当,则被调用函数将占用调用函数的很大一部分,我们添加了一个额外的度量来过滤掉冗长的调用:
![]()
(2) 边缘覆盖
我们从调用扩展后的(选择性内联过后的)控制流图中随机抽取所有的边,直到原始图中的所有边都被覆盖。对于每个采样的边缘,我们将其连接起来形成一个新的序列。这样可以确保控制流图被完全覆盖。即使控制流图中的基本块被分割或合并,该模型仍然可以产生相似的结果。
(3)随机游动
我们通过在扩展的控制流图上增加多个随机游动来扩展汇编函数的汇编序列。目的是使得到的序列更多地来覆盖关键路径的基本块。
5 实验
实验主要是在编译器优化和代码混淆的情况下,代码克隆识别的准确性。以及模型在漏洞数据集中能否检测出漏洞函数。
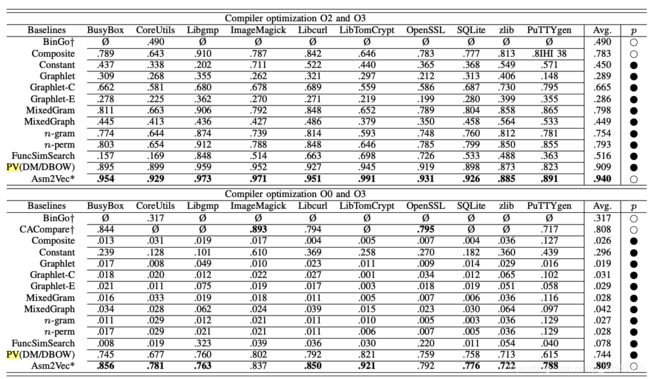
Searching with Different Compiler Optimiza- tion Levels(在编译器优化下)
实验对于GCC编译器的 O2 vs O3 选项和 O0 vs O3 选项进行了实验。与其他代码克隆搜索工具比较,Asm2Vec 有较高的检测效果。
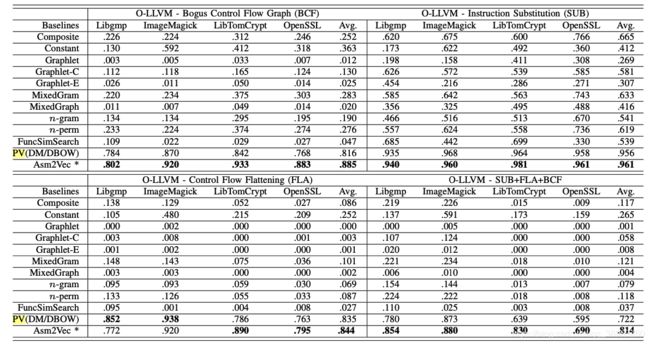
Searching with Code Obfuscation(代码混淆)
Searching against All Binaries

Searching Vulnerability Functions
Asm2Vec和ESH相比,在True Positive上更高,同时 ROC 和 CROC 的值都为 1:
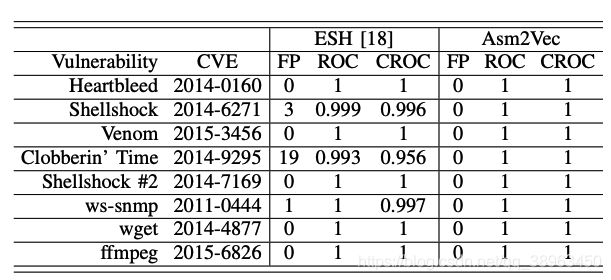
Asm2Vec检测出的漏洞函数